Figure 1. The Internet's Confederation Approach
| Sharon Eisner Gillett Research Affiliate Center for Coordination Science Sloan School of Management |
Mitchell Kapor Adjunct Professor Media Arts and Sciences |
|
| Massachusetts Institute of Technology | ||
Prepared for:
Coordination and Administration of the Internet
Workshop at Kennedy School of Government, Harvard University
September 8-10, 1996
Appearing in:
Coordination of the Internet, edited by Brian Kahin and James Keller, MIT
Press, 1997
Contrary to its popular portrayal as anarchy, the Internet is actually managed, though not by a manager in the traditional sense of the word. This paper explains how the decentralized Internet is coordinated into a unified system. It draws an analogy to an organizaional syle in which a manager sets up a system that allows 99% of day-to-day functions to be handled by empowered employeees, leaving the manger free to deal with the 1% of exceptional issues. Within that framework, it discusses:
How the Internet's technical design and cultural understandings serve as the system that automates 99% of Internet coordination; What the 1% of exceptional coordination issues are in today's Internet, how they are handled by multiple authorities, and where the stresses lie in the current structure; and The differences in mindset that distinguish the Internet's self-governance from the management of more traditional communication systems.
Introduction
If the Internet were an organization, how would we describe its management?
To answer this question, we first distinguish two extremes of management style: centralized and decentralized. In the centralized extreme, managers make their presence essential to most day-to-day functioning. Without their involvement, little information would be exchanged and few decisions would be made. Managers have lots of power, but they can never take a vacation.
In contrast, in the decentralized organization, managers create systems that allow their organizations to run without them most of the time. All routine events, constituting 99 percent of organizational life, are handled by members of the organization empowered by the system. The manager's roles are to set up the initial system, to integrate new activities into it as they emerge, and to deal with the one percent of truly exceptional events.
Contrary to its popular portrayal as total anarchy, the Internet is actually managed. It runs like a decentralized organization, but without a single person or organization filling the manager's role. The system that allows 99 percent of day-to-day operations to be coordinated without a central authority is embedded in the technical design of the Internet. The manager's job - handling the exceptional one percent - is performed by not one but several organizations.
As the size, international scope, and financial importance of the Internet continue to grow, Internet management is perceived to be coming under increasing pressure. Internet technology is called on to coordinate a system of unprecedented scale and complexity. The organizations that fill the Internet's managerial role today do so mostly as an accident of history, and the legitimacy of these arrangements is increasingly questioned. The intent of this volume is to identify the organizational and technical pressures in the coordination of today's Internet and discuss what changes may best relieve them.
Informed discussion of potential changes requires, however, that the decentralized organizational model of the Internet first be properly understood. It can be especially difficult to understand which coordination issues are handled by the 99 percent system, and which fall into the one percent category that truly requires managerial intervention. Without this understanding, there is a dangerous temptation to apply big hammers to coordination problems that are properly viewed as small nails. This risk is especially great for the many people who, because of the realities of exponential growth, have not grown up with the Internet (so to speak) but will help to chart its future. Although the Internet looks quite different from traditional communications infrastructures (such as the telephone system, and the mass media of print, radio, and television), there is a natural tendency to apply the better understood, more centralized mindset associated with these systems to the Internet's coordination problems.
The aim of this chapter is to provide context for the rest of the volume by giving participants a deeper understanding of the Internet's current coordination system. It begins by describing the decentralized nature of the Internet: how the 99 percent looks different from more traditional infrastructures, and the design of the underlying technical and cultural system for coordination. This system relies much more heavily on automation and loosely unified heterogeneity than on institutions and centrally dictated uniformity. By demonstrating the link between this approach and the Internet's success, we hope to give newcomers a gut-level trust in the power of the Internet's unusual organizational model. For old-timers, we offer a new, more socially oriented interpretation of what is already familiar technically.
Next the chapter lays out the one percent category, describing what the exceptional functions are, how they are managed today, and where the stresses lie in the current system.
Instead of proposing specific changes (a difficult job that we leave to those more directly involved in the process), the chapter concludes with a list of questions to ask about proposed changes. These questions are intended to determine how well each proposal enhances, or at least does not detract from, the Internet's distinguishing social, economic, and political properties - its highly valued openness, diversity, and dynamism.
Coordination of the 99 Percent: The Decentralized Nature of the Internet
The Internet is more decentralized than any of the communications systems that have come before it, including print, telephony, television, and the original model of an on-line information service. This decentralization is reflected both in the choices presented to users, and in the underlying structure that creates those choices. We first examine the user's view, then turn our attention to the scaffolding underneath.
The closest approximation to the Internet's organizational model is the on-line service - America OnLine (AOL), CompuServe, Microsoft Network, and so on. Under pressure from the World Wide Web, these services have evolved considerably. Looking at the major changes to their business model helps bring out what is different about the Internet, as Table 1 illustrates.
The first difference is the most important: Who decides what content is made available? In the original on-line service, this choice is made by the service operator, who takes on the role of information "gatekeeper" - just like newspaper editors who decide which stories to run, publishing houses that decide which books to print, radio and TV executives who decide which programs to air, and cable TV operators who decide which channels to carry. The gatekeeper model contrasts with the decentralized World Wide Web, in which users themselves decide what information to make available - and correspondingly, what information to look at. Since users can, they do put their content on the Web. This decentralized decision-making has led both to the greater volume of content available on the Web, and to its diverse span - for example, from amateur undergraduate home pages to professional content providers such as The New York Times.
Table 1. Web vs. Original On-line Service Model
Original on-line service model |
Web-influenced on-line service model |
Web model |
Central information choice ("gatekeeper") |
Personal Web pages Central choice of (professional) content providers |
Anyone can provide content |
Closed user interface (proprietary software) |
Pre-selected third-party software, sometimes customized |
Any Internet-compatible software |
Connectivity bundled with content |
Connectivity bundled with content |
Anyone can provide connectivity, separately from content |
The second difference is the choice of user interface. Using the original AOL service meant using AOL's software, period. Using the Internet, in contrast, leaves the user free to choose not only which software vendor, but which type of application to use. As new services are invented (e.g., Internet telephony), the user is free to adopt them (or not). This open user choice is essential to the rapidly flowing stream of competitive innovations that have become so familiar in Internet software, from basic browser capabilities, to third-party plug-ins that add new media formats, to entirely new types of services.
The final difference in user choice concerns network plumbing. On-line services bundle information and communication services together, in contrast to the Internet's specialized, largely independent content and connectivity providers. On-line service customers miss out on the price and service competition that comes with the Internet's diverse array of access providers.
Why don't other communications systems offer as much user choice as the Internet? The
reasons are both technical and social. Technical, because it is not easy to guarantee
universal compatibility if each user is allowed to choose his or her own type of computer,
communications software, and connectivity operator. Social, because the flip side of
choice for the user is lack of control for the system operator. Had the Internet been
designed as a for-profit system, such lack of control might not have been tolerated.
Consider, for example, that as the business model has shifted from the original on-line
service to the Web, control over the process of making content available has shifted from
the on-line service operator to the content owner. This shift has not exactly been
welcomed by on-line service providers, since it has put pressure on the revenues they
receive from content owners.
Technically, what the Internet achieves sounds almost oxymoronic: decentralized interoperation. The Web emerged with many different organizations developing client (browser) and server software, yet any browser can display any server's page. A Macintosh user can exchange e-mail with a PC user, with neither user aware of the difference in machines. There are multitudes of Internet connectivity providers, and they simultaneously compete and exchange each other's traffic, using a wide variety of arrangements for physical interconnection and exchange of payments. At the core of these unusual juxtapositions lies the Internet's design for interoperability - the defining principle that creates a unified Internet out of a collection of disparate networks and services. Interoperability is the system that allows 99 percent of the Internet to run without a manager. We now turn our attention to how this interoperability is achieved, looking first at protocols in general as a coordination tool, then at the open Internet protocols in particular.
Protocols: A Coordination Tool
In its ruling on the initial challenge to the Communications Decency Act, the U.S. District Court for the Eastern District of Pennsylvania included this explanation of the decentralized nature of the Internet:
No single entity - academic, corporate, governmental, or non-profit - administers the Internet. It exists and functions as a result of the fact that hundreds of thousands of separate operators of computers and computer networks independently decided to use common data transfer protocols to exchange communications and information with other computers (which in turn exchange communications and information with still other computers). There is no centralized storage location, control point, or communications channel for the Internet . . . .
A communications protocol is a set of rules governing how computers exchange information with each other. The rules spell out how the data to be exchanged must be formatted and in what sequence any exchange of information must take place. For example, the interoperability of Web clients and servers that we remarked on above relies directly on two protocols: the Hypertext Markup Language (HTML), which specifies the format of documents to be exchanged, and the Hypertext Transfer Protocol (HTTP), which governs the order of conversations between browsers and servers. Indirectly, the Web's interoperability also stems from a number of other protocols, including the Internet Protocol and Transmission Control Protocol (together known as TCP/IP), that HTTP relies on for interoperable lower-level services.
Protocols by their very nature constitute a coordination tool - exactly the kind of system that can automate the routine 99 percent of computer-to-computer interactions. But there is a catch. Protocols automate interoperability only if all computer operators agree to use the same ones. How can such uniformity be achieved without a central authority mandating the adoption of particular protocols?
The Internet Protocols: Open Standards
The Internet protocols became widely accepted standards in an unconventional way. Unlike the Open Systems Interconnect (OSI) protocols developed by the International Standards Organization (ISO), TCP/IP did not have the official imprimatur of an internationally recognized standards authority. Unlike commercial networking protocols developed contemporaneously, such as IBM's SNA, Digital's DECNET, and Xerox's XNS, they did not have the marketing resources of a large company behind them, nor was their design oriented toward any particular vendor's hardware. Instead, they were developed by researchers funded by the U.S. government, and consequently made freely available to anyone who wanted to use them - in other words, they became open standards. They were developed in an iterative fashion and improved over time in a process that was not controlled by financial interest, leading to a free, quality product that people wanted to adopt. The seemingly ironic outcome of this process is that the free choices of millions of individuals led to much more universal adoption of the common Internet protocols than any of the other more centrally mandated alternatives.
Those who have recruited volunteers or raised funds will intuitively understand why this outcome is not really so ironic. People are most willing to contribute toward a collective goal or system when they do not feel coerced, when their participation is perceived to be in their individual interest, and when the requests made of them are small. Given that TCP/IP was free, solved real-world, cross-platform communication problems, and was readily available without needing to get anyone's permission, the decision to adopt it satisfied all of these criteria.
Open standards are key to the Internet's juxtaposition of interoperability with distributed power and control. For example, anyone who wants to create a Web site can freely use the relevant document and network protocol formats (HTML and HTTP), secure in the knowledge that anyone who wants to look at their Web site will expect the same format. An open standard serves as a common intermediate language - a simplifying approach to the complex coordination problem of allowing anyone to communicate successfully with anyone else.
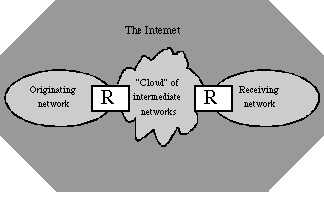
The common intermediate language approach is embedded in the fundamental design of the Internet. The researchers working on the Advanced Research Project Agency's internetworking program in the early 1970s faced a basic design decision: should they follow the model of the telephone system and tightly integrate multiple networks into a centrally managed system, or build a loose confederation of independently managed networks? The confederation approach they adopted met several needs. First, it recognized diversity: a network constructed out of noisy mobile radios has different technology and management needs than a fixed network of high-quality circuits. Second, it recognized practical reality: existing networks represent administrative boundaries of control that are easier to respect than to cross. Finally, it avoided single points of failure to create a robust, survivable network.
Confederation is accomplished through the Internet Protocol (IP), an open standard
designed to layer between the protocols (such as HTTP) that are specific to particular
applications, and the technologies (such as Ethernet) that are specific to particular
physical networks. A small amount of Internet Protocol information is added to each
network message, and used to deliver the message to destinations beyond the local network.
The necessary processing is accomplished by special-purpose computers placed at the
logical "edges" of networks and referred to as gateways or routers (labeled as
"R" in Figure 1).
Figure 1. The Internet's Confederation Approach
The separate router box represents the cost of confederation. Compared to integrating the functions of this box directly into a physical networking technology, a separate box is an inefficient approach. Especially as computing price-performance has continually increased over the long term, however, the technical inefficiency of this design has turned out to be more than counterbalanced by its social benefits - for example, that it can be adopted without requiring users to replace their existing networks. We now look at these benefits. In the language of design, we are examining the affordances and constraints of IP. By affordances, we mean the characteristics of an object's use that are readily promoted by its design; by constraints, we mean the uses that the design makes difficult, if not impossible.
Affordances of the Internet's Design
Re-use of Investment. Confederation means that if you already have a network connecting your internal computers, you do not have to replace it to connect to external computers. You just have to add a gateway and run IP on top of what you already have. Because the IP approach affords reuse of existing networks, existing investments are protected - leading, of course, to greater adoption.
Easy Change. The modular design of the Internet affords the evolution and adaptability that have been so critical to its long-term survival. This change is evident throughout all layers of the Internet. We start with physical layer examples and work our way up to applications.
Because IP is minimal and general-purpose, it has proven able to ride on top of an enormous diversity of networking technologies. Local Area Networks (LANs), for example, were not yet in use when IP was designed, yet IP worked over the very different types of physical networks that emerged as LANs became commonplace. As network technologies continue to evolve (e.g., Asynchronous Transfer Mode, or ATM), network engineers continue to adapt IP to them. The design of IP does not constrain the deployment of newer, faster, better, or cheaper physical networks. Without this property, the Internet could not have supported the growth rate that it has.
The Internet's modularity has even permitted IP itself to change (although not without the pain associated with changing something that has now been widely deployed). The layering built in to Internet protocols allows not just IP (and friends) but also other protocol stacks, such as ISO's OSI, to be used in the Internet. The same mechanisms that afford such multiprotocol support are being pressed into service to allow a transition to a new version of IP, needed to cope with the Internet's successful growth.
Finally, IP's generality affords the emergence of new applications. The Internet's designers did not really know what the network would be used for. Their best guess, that people would use it to access computing resources located elsewhere (i.e., remote login), was supplanted by the popularity of applications, such as electronic mail, that allow people to communicate with each other. Had they oriented the network toward remote login applications, the Internet would have turned out to be an interesting historical footnote. Instead, they created a general-purpose platform that enabled the emergence, nearly two decades later, of the graphical World Wide Web, catapulting the Internet into prime time.
Minimally Coercive Decision-making. IP's confederation approach achieves a collective system with a minimum of coercion. All the benefits of universal intercommunication can be had with only one decision forced on users: they must use the freely available IP somewhere in their protocol stack. All other choices are left to users.
Among these local choices are many that we are not used to seeing so widely distributed. Newcomers to the Internet are usually surprised to learn that no central body decides what applications or content will be developed, or assumes overall responsibility for the functioning of the Internet's constituent networks. We now look in more detail at each of these aspects of the Internet's decentralized decision-making. We start with the role choice that lets any user be an information or service provider, and move on to the operational choice that allows the Internet to function as a network of independently managed networks.
IP does not make any distinction between the users and providers of the Internet. If a computer runs IP, it can run any service that layers on top of IP. Higher-level protocols may distinguish - for example, a Web browser is a different software package from a Web server - but at the universal protocol layer, there is no distinction. Anyone whose computer runs IP can run either a Web browser or a Web server. In other words, anyone who is part of the Internet can function as either a user or a provider of Web services.
IP's egalitarian design affords choice to users over what role to play on the Internet. Do they want only to be a user, or do they want to provide networking, application, or content services to others? If they choose to provide new applications or content, which kind?
Putting these choices in the hands of individual users - instead of corporate or governmental gatekeepers - radically distinguishes the Internet from other communications media. It is much harder to imagine ordinary people creating their own cable TV programs than their own Web pages. Few companies have created new on-screen TV guides, but many have been able to create their own on-line search or indexing pages for the Web. Large telephone companies, fearing cannibalization of their existing businesses, were unlikely to develop Internet telephony products, but no such concerns hindered the startups that originated them instead.
More than any other affordance of the Internet's design, individual role choice has given the Internet its characteristic information abundance and diversity, as well as its entrepreneurial dynamism. Not surprisingly, it is also the aspect of the Internet's design that most threatens organizations accustomed to controlling the flow of information or the pace of innovation.
Individual choice also applies to the operators of Internet connectivity services. IP is deceptively simple: it defines a delivery service, known as datagrams or packets, and an identification scheme, known as IP addresses. What it does not define is just as important. One of the Internet's design goals was to create a system with no single points of total failure - components that, if disabled, would also disable the rest of the system. Making one network of the confederation into a special or privileged network would run counter to this principle. By not including features that would enable or force one network to control or manage another, IP embodies the assumption that networks will relate as peers. Thus, IP's design constrains the emergence of "chief" networks.
Peer networking contrasts with the norm in more centrally oriented systems, such as the U.S. telephone network before full-fledged long-distance competition. AT&T's network was the king: if a caller wanted to use a different long-distance service, s/he was forced to dial extra digits. The dominant network was also the control network, and this assumption was so built in to the design of the system that leveling the competitive playing field required technical changes to remove the implicit default.
No such control network or implicit routing default is built into today's Internet. In fact, Internet routing is only one of many operational details that is controlled in a decentralized fashion by thousands of independent connectivity providers. For example, each provider independently decides:
whether to enter the business in the first place;
which other providers to interconnect with, whether bilaterally or through a multilateral exchange point;
whether, on what basis, and how much to (try to) charge for any exchange of traffic (such charging is referrred to as "settlements");
how much capacity to provide today and in the future;
which user segments to target with what pricing scheme;
what level of service quality to provide; and so on.
The result is a decentralized mesh of interconnection, with a wide variety of institutional arrangements and consumer choice in Internet access, and a dynamism that makes the industry exciting and innovative as well as bewildering.
Because they are selling the ability to communicate across a network, providers depend on each other for interconnectivity. In all other respects, however, they compete with each other just like providers of other services, from barbers to bankers. There is a tension inherent in this so-called "co-opetition." As in any industry, Internet connectivity operators vary not only in size, but in how well they execute different aspects of their business. The interdependence forced by interconnectivity means that lower-quality operators may detract from the service provided by higher-quality operators, while higher-quality operators may end up providing a free ride to others.
Looking at such tensions from a centralized mindset directs people to the conclusion that the connectivity industry will eventually consolidate into a centrally managed system. The economies of scale that will lead to consolidation, however, should not be confused with the need for centralized control. While the number of providers will likely decline, IP's constraint against "king" networks suggests that quality control may well remain decentralized - for example, by providers agreeing to adhere to a common set of service quality standards. In other words, Internet connectivity might one day more closely resemble the accounting industry, in which competing companies follow the same set of accounting rules, more than the telephone system in the days of Ma Bell. How such standards can be developed, especially given the challenges of today's commercial, international Internet, is discussed later in this volume.
An Open, Layered Platform. As the common intermediate language of the Internet, IP hides the details of the networks it confederates from the applications that run on top of them. From the application developer's perspective, IP replaces the real-world heterogeneity of networks with a virtual universal platform.
IP is a basic building block, intended to be supplemented by higher-level protocols more oriented toward the needs of particular applications. Application developers do not interface directly to IP, but to the layers above it. The higher the layer, the more specific the purpose of the protocol. For example, IP delivers packets with no reliability guarantees, and all Internet traffic uses it. TCP, which layers directly on top of IP, reliably delivers ordered streams of data; most, but not all, Internet traffic uses TCP. HTTP, which layers on top of TCP, delivers Web pages; all traffic between Web browsers and servers uses HTTP, but none of the traffic for non-Web services does. All of these protocols - IP, TCP, HTTP - are freely available, openly published standards, enabling any application developer not only to build on top of them, but to give away the resulting programs if they so choose.
The open, layered platform architecture means that a software engineer trying to develop an interoperable Web browser does not have to think about whether the software will run on Ethernet or ATM networks; s/he only needs to make sure it runs over IP and interoperates with the Web client at the other end. As a practical matter, the platform architecture greatly simplifies - and therefore expedites - the development of interoperable Internet applications.
By creating a business environment with unusually low barriers to entry, the platform architecture affords the specialization and rapid innovation that are so characteristic of the Internet. The general-purpose nature of IP means that many different applications - including those not yet invented - can layer on top of it. This layering leaves application developers free to concentrate on their portion of the problem, such as publishing documents (e.g., the Web) or managing messages (e.g., e-mail and news). Lower layers - with interfaces that are openly specified and freely available to all - take care of the rest. Since an entrepreneur with a new application idea does not have to first build a network to deliver it, more entrepreneurs can build more applications, creating more value from the network. The open, layered platform thus affords faster, broader, and more competitive value creation than more conventional, vertically integrated communications systems.
The Culture of Interoperability
We have discussed how the Internet's technology affords its decentralized operation. But technology is only part of the picture. The other part is people. All the clever design in the world cannot create an interoperable system unless enough people hold interoperability as a shared goal. Interoperability is like Tinkerbell: it only works if everyone believes in it.
Where technology ends, cultural values begin as coordination mechanisms. Two deeply held cultural values make the collective Internet work. The first is that interoperability is sacrosanct - it is the defining characteristic of the Internet. The second is that to achieve interoperability, protocol implementations must be conservative in what they send and liberal in what they receive.
The liberal/conservative rule is needed to deal with imperfection, incompetence and malice. Protocol specifications contain unintentional ambiguities, and their implementations may contain mistakes. By receiving liberally, implementations automatically become tolerant of the errors that are bound to occur in the open environment of the Internet. Instead of depending on centralized quality control or licensing of service providers to guarantee compatibility, errors are simply expected and, to the extent possible, gracefully dealt with.
This approach has worked in the Internet because so far errors have not been overly costly. As people and businesses come to depend on the Internet as critical infrastructure, the limits of this approach will certainly be tested. This is one aspect of the Internet's decentralized organizational structure that we would not expect to be emulated in an environment in which mistakes could be extremely expensive or life-threatening. A malformed protocol header can be ignored, usually without grave consequences; a malformed voltage on a communications circuit, on the other hand, could end up sending 10,000 volts through a telephone repair person.
Liberal reception is also a way to deal with people who try to subvert interoperability. Because of interoperability, an application may be stuck with what it considers to be lowest-common-denominator services. A vendor may choose to unilaterally enhance some services, potentially sacrificing interoperability. But if receiving protocol implementations gracefully ignore new features that they cannot understand, interoperability can still be maintained. To illustrate with a hypothetical example: if vendors of Web servers each choose their own nonstandard ways of marking "all-singing, all-dancing" text in HTML, then a Web browser that ignores this format and simply displays plain text will still interoperate, while one that rejects the entire page will not.
Summary: Principles of the 99 Percent
In summary, day-to-day coordination of the Internet is informed by the following principles:
Value interoperability. The success of the Internet depends on a shared belief in the importance of interoperability. Erosion of this belief could be the single biggest threat to the Internet's future. More widespread understanding of the importance of this shared value is therefore critical.
Automate coordination. Use protocols whenever possible to automate interactions. Automate conformance monitoring and error handling as well.
Distribute power, control, initiative, and authority - but still interoperate. The philosophy of IP is that minimally coercive collective systems work best. The art of IP is designing the right interface so that standardized interaction and local control can comfortably coexist.
Expect change. Adapting to change is the norm. Build systems that will be flexible in the face of change, even though this approach has short-term costs.
Coordination of the One Percent: Internet Administration Today
The previous section explained how open standard protocols and the culture of interoperability automate the coordination of 99 percent of the Internet. Now we turn our attention to the exceptional one percent. Exceptions arise when protocols are not mature enough to fully automate what needs to be done, when reaching common agreement is part of the coordination process, and when resources have to be unique. In this section we first list the specific exceptions, then explain in more detail how each is managed today and where the stresses lie in the current system.
Routing. Each connectivity provider operates routing tables that direct traffic within the Internet. The data in these tables are based partly on the computations made by distributed routing algorithms, and partly on manually specified configurations. Errors in one provider's manual configurations can cause problems for traffic from other networks. The coordination problem is figuring out ways to either prevent or contain the damage from misconfiguration.
Service Quality Standards. As discussed above, these do not currently exist for the Internet. If they did, individual providers could characterize the level of service offered to users. To be useful, such standards would have to be commonly agreed to by all providers. Processes to secure such agreement lie outside the realm of automated coordination by protocol.
Protocol Standards. Similarly, protocol standards only work if they are universally agreed on. The processes by which Internet protocols are developed and standardized lie outside the day-to-day Internet coordination mechanisms.
Unique Identifiers. All communications systems need some way to uniquely identify their communicating entities. The telephone system uses telephone numbers. The postal system uses addresses. Each of these, when fully formed with country codes or names, uniquely differentiates every communicating entity in the world.
The Internet has two forms of unique identification for the computers connected to it. The first is the computer's IP address, a numeric identifier generally meaningful only to other computers. The second is its domain name, intended to be meaningful to people. The domain name flowers.com, for example, is much more memorable than 192.18.13.1, just as 1-800-FLOWERS is more memorable than 1-800-356-9377.
Because these identifying names and numbers have to be unique, their assignment has to be coordinated in some fashion. How that coordination should take place in the future is one of the key questions discussed in this volume.
Like addresses and names, protocol parameters have to be unique. Unlike addresses and names, though, these identifiers are purely internal to Internet technology (i.e., completely invisible to users). They include numbers that indicate which version of a protocol is in use, which higher-level protocol's data is being sent in an IP packet (e.g., the Transmission Control Protocol or the User Datagram Protocol), which type of program should process that packet on the receiving host (e.g., a file transfer server or a Web server), etc.
Now that we know what the different types of exceptions are, we are ready to examine in more detail how each is coordinated today, and what is perceived as wrong with the current system, if anything.
Controversy surrounds the question of whether routing configuration information is subject to sufficient quality control today. Each provider implements its own filtering and sanity check mechanisms. Developing a scalable, dynamic mechanism for performing quality control on routing configuration information is an open research problem. Further consideration of this issue is beyond the scope of this volume.
These are not coordinated today, but would need to be developed by common agreement. When IP was commonly agreed to, the number of networks was very small. The challenge for quality metrics is to reach agreement in an environment with large numbers of commercial providers with vested financial interests in how quality gets defined. Since the provider base is international, enforcement of standards could also become an issue if it cannot be automated.
In the canon of Internet mythology, Internet protocols are developed by the Internet Engineering Task Force (IETF). This statement is true, but it is far from the whole story.
Certainly, the IETF plays a major role. It develops Internet protocols as well as standardizing what has already been developed elsewhere. But it would be wrong to think that the IETF has any kind of monopoly on the development of Internet standards. If a protocol is useful and made widely (usually freely) available, it can easily become a de facto Internet standard before being touched by the IETF - as the Web's protocols did. And nothing stops companies from inventing their own protocols and attempting to turn them into universal standards through marketing genius, instead of through the IETF (at least initially). This dynamic has been observed many times, for example in Sun's development of NFS and Netscape's enhancements to HTML.
Standards that affect the Internet are also developed in other fora, such as the ATM Forum, the World Wide Web Consortium, and so on. The IETF focuses less on physical communication and application-level standards, and more on the interoperability that sits in between: IP, the routing protocols that work with it, the domain naming utilities that translate names into IP addresses, the mappings between IP and different physical infrastructures (e.g., how to run IP over ATM, mobile networks, or dial-up lines), etc.
Nothing needs fixing about what we have described so far. To be sure, de facto standards setting is a less-than-perfect process. Internet telephony is a case in point: the first vendors kept their protocols proprietary and failed to make their software ubiquitous through some sort of give-away strategy. The predictable result: non-interoperable Internet telephony applications, inhibiting growth. This outcome is not stable, however, since the initial experiment proved the value of Internet telephony. Bigger players, such as Netscape, will add telephony functionality to their software, and better interoperability will emerge.
The bottom line is that even with de facto standards, the drive toward ubiquity is strong enough to keep interoperability a business requirement. The alternative - of no de facto standards - is neither practical nor desirable. Much of the innovation and dynamism of the Internet results from just these kinds of experiments.
What is perceived as needing change is a small piece of this bigger picture. The IETF originated in the nonprofit, government-funded research community. Even as commercial interests have come to play much larger roles, the IETF still receives on the order of $0.51.5 million per year from the National Science Foundation (NSF) of the U.S. government. This funding pays for the secretariat function - the staff and equipment needed to administer the IETF mailing lists, Web server, meeting arrangements, and so on - and keeps the meeting attendance fees to a nominal level. The open question, then, is how should this function be paid for if the U.S. government wants to get out of the Internet coordination business?
The amount of money involved is quite small by corporate standards, especially compared to the indirect corporate support for employee's time and travel that already goes into much IETF work. Even $1.5 million spread across the thousand or so people who attend each of the three IETF meetings per year comes out to only about $500 per meeting attendance. The IETF process has managed to preserve its highly valued open process even as indirect corporate support for its activities has increased. Presumably, the remaining expense is small enough that it too could be distributed in some fashion across attendees while still maintaining that openness.
From standards, we now turn our attention to numbers. We start with the numbers that are not controversial - the numeric identifiers internal to Internet protocols. These protocol parameter values are currently assigned by the Internet Assigned Numbers Authority (IANA). IANA is a virtual name that currently refers to a group of people who work at the University of Southern California's Information Sciences Institute (USC ISI) under the direction of Jon Postel. Their main function is networking research, and their existence is predominantly funded by U.S. government research grants. Their performance of this function is a product of history, not design. Postel picked up the role of number coordinator because it needed to be done when he was a graduate student involved in the birth of the ARPANET, and he never quit doing it.
There is no current movement for this system to change as far as protocol parameters are concerned, and it is instructive to understand why not. First, protocol parameters are not perceived as scarce, so there are no political pressures involved. Second, they are an extremely low-volume operation. Assigning them takes more effort to discuss than to do, so tacking them on to network research is not unreasonable.
These characteristics are not expected to change for protocol parameters. IP addresses and domain names, though, are a different story. If they shared these characteristics with protocol parameters today, there would have been little impetus for this volume.
We treat addresses and names separately, since they have some very different attributes. IP addresses are meaningful to connectivity providers and have strong technical (i.e., routing) implications; domain names, on the other hand, are meaningful to users and have strong trademark (i.e., legal) implications. Since there are orders of magnitude more users than providers, domain names are potentially the more difficult issue.
A user who wants to add a network to the Internet today experiences the following process for obtaining a guaranteed-unique IP address:
What is potentially wrong with this picture? A few things:
Current Internet Protocol (version 4) addresses are perceived as scarce. Based on extrapolation of past growth rates, the registries feel compelled to allocate remaining IPv4 address space conservatively. In addition, in an effort to simplify the Internet routing system, registries prefer to allocate larger contiguous blocks of addresses, which are of course less plentiful than smaller blocks. These policies together contribute to a perception of address space scarcity. Whether such conservation is actually creating hardship for providers and users does not appear to have been authoritatively researched; it should be. Clearly, though, the conservation policy puts the registries - organizations whose origins lie in the research community - into the unfamiliar and uncomfortable position of having to weigh competing commercial claims. As David Randy Conrad describes the situation:
The current mechanisms by which addresses are allocated fundamentally [rely] on trust. The allocation authorities must trust the requesters to provide an accurate and honest assessment of their requirements in order for appropriate amounts of address space to be allocated and the requesters must trust the allocation authorities to be fair and even handed. In the past, this trust-based model was both efficient and effective as, by and large, there were no particular constraints on the amount of address space which might be allocated and the community requesting the space was more academically oriented than commercially reliant on obtaining those resources. However, with the rapid ascendancy of commercial networks on the Internet, the trust model for resource allocation is under severe pressure.
It is also unclear how much conservation is truly necessary. Only a small fraction of the already allocated space is actually utilized. A new version of the Internet Protocol, IPv6, has been standardized with a much larger address space, although of course no one can predict when (if ever) it will become widely deployed. In addition, several technologies are emerging to make more efficient use of IP address space, whether version 4 or version 6. The bottom line is that uncertainty in the future growth rate combines with uncertain user adoption of technical changes to make it impossible to predict whether there are enough IPv4 addresses to satisfy demand.
The ultimate authority, and therefore chain of appeal, is not clear. If a user or provider is not happy with the allocation received, to whom should s/he appeal? Conrad describes three possible answers to the question of who has ultimate authority for IP address allocation, and different communities that view different answers as correct. His three models beautifully illustrate the problem with IANA's historical authority: it may not survive challenges to its legitimacy. After considering whether IANA's authority derives from the U.S. government, the Internet Society, or Internet connectivity providers, he writes of the latter option:
This model works as long as the ISPs [Internet Service Providers] and the IANA/RIRs [Regional Internet Registries] can cooperate. Should the historical cooperation between these two sets of organizations break down, the ISPs, again working in concert, could conceivably create an 'Anti-NIC' allocating new addresses from the unused pool without regard to IANA/RIR policies.
In other words, IANA's authority depends on how close Jon Postel comes to performing this role with the wisdom of King Solomon.
The U.S. government is still funding the InterNIC. This creates two problems. First, the National Science Foundation would like to get out of the Internet coordination business. Second, long-term government funding is well known to have a "sugar daddy" effect on efficiency incentives for its recipients; why strive for greater efficiency when that might make next year's funding levels go down? The incentives look better in the provider consortium funding models of RIPE NCC and APNIC, since the providers can always create a new consortium to take their business elsewhere if enough of them are not happy with the registry's performance. The provider consortium model appears to work well for these regions. Before rushing to adopt it for the InterNIC, however, we note two observations. First, RIPE NCC and APNIC have been well represented and heard from at the various workshops convened to discussed Internet coordination, but less has been heard from their customers, whose perspective might be different. (We are not trying to say that it is, only that it might be, and that this possibility should be checked.) Second, RIPE NCC and APNIC currently deal with fewer providers than InterNIC; what works for 20 or 200 might not necessarily work for 2,000, or when the disparities in scale among the provider population are quite large. The latter factor could make a provider consortium into a playing field that is anything but level. A consortium may turn out to be the best solution, but we should at least be aware of its potential problems.
Address allocation is technically nontrivial. The continued exponential growth of the Internet puts intense pressures on the routing and addressing systems. There are now many constraints on which addresses can be allocated and still be universally routable. Providers that operate across multiple regions complicate the picture further. The bottom line is that successful address allocation requires administrators with strong technical skills, not just political or legal expertise.
Naming is technically simpler than addressing, but it is much more visible and meaningful to users, creating even more stresses on the current system of name assignment.
From the user's perspective, getting a domain name looks much like getting an IP address: most users apply through their Internet connectivity provider. Beyond that, though, domain names look different. Unlike IP addresses, domain names are not part of a finite space, and providers do not have a chunk of them to allocate. Instead, users request names that are meaningful to them, and providers forward their requests to the appropriate Internet naming registry.
There are many such registries, each with responsibility for different Top Level Domains (TLDs). The TLD is the name after the last dot; it may be national (such as .au, for Australia) or international in scope (an iTLD), such as .com, .edu, .net, and .org. The appropriate registry to apply to depends on which of these TLDs the user wants a name in.
National domains are administered specifically to each country, for example by a university, a national telephone company, or a branch of the government. According to Jon Postel, he is the person who approves or denies the infrequent requests from organizations wishing to manage a country's name space. Generally, he grants the request to whoever applies first. He uses the ISO country code list to determine what is a country, sparing him from entering the realm of international geopolitics.
Each registry sets its own policies. For example, in Australia an entity has to be a registered corporation to get a name in .com.au. The InterNIC, which administers the iTLDs .com, .edu, .net, and .org for the whole world, imposes no such restriction on the .com domain. (RIPE NCC and APNIC do not administer any TLDs, although they do forward requests to the appropriate registries. They also run backup name servers for their regions.)
Fortunately for the InterNIC, the Domain Name System (DNS) is hierarchical. Once a TLD is given out (e.g., mit.edu), it is up to the recipient to manage it further. Since most of the changes to the name space happen at these lower levels, most of DNS is effectively self-administered.
Still, the runaway growth of the .com domain has put intense pressure on the InterNIC. In the fall of 1995, the InterNIC began charging an annual fee of $50 to maintain .com registrations, in order to supplement NSF funding that had been allocated based on a much smaller Internet. This action sparked much protest in the Internet community. Ignoring the inevitable complaints from people accustomed to receiving free service as a guest of Uncle Sam, the gist of the protest was that the InterNIC was in a monopoly position with respect to commercial domain name assignments, and was perceived as acting like a monopolist by providing poor service for excessive fees.
Since monopolies are generally considered to be bad things, especially by the Internet community, we have found it instructive to ask why the InterNIC ended up in this position. The answer is partly technical and partly historical. DNS is implemented as a distributed and replicated database, logically organized in a hierarchical fashion. Translating the name foo.mit.edu into an IP address may involve as many as three name servers: a root (or ".") server, a TLD server for .edu and an MIT-operated server containing the address of foo in mit.edu. Each name server gets its data from a "zone" file, which is maintained centrally but replicated to all the servers at the same level in the hierarchy. Thus the InterNIC's monopoly on commercial name registrations arises from it being the only organization that makes changes to the .com zone file, and from the implicit agreement among lower-level server operators to point only to servers supplied by this file.
Today's technology could, however, allow multiple organizations to cooperatively maintain a single file if they want to, or to create more commercial TLDs beyond .com. But .com is contentious for reasons that go beyond the InterNIC's monopoly, and these have slowed the process of change by engendering a broader debate about what changes to make.
Domain name space is flatter than real-world identifiers. This problem is often stated as "the good names are all taken." For example, in the physical world, there can be multiple entities named Acme - Acme Research, Acme Computer, Acme Explosives, Ltd., and Acme Explosives, Inc. But on the Internet there can only be one acme.com. When Acme Explosives, Inc. finds that Acme Computer got there first, it can sue for trademark infringement, try to buy out the name, or become acme-explosives.com - assuming, of course, that Acme Explosives, Ltd. did not get that one first, in which case it could sue, buy out, or pick something yet longer . . . and so on. Since shorter names are easier to guess, remember, type, and fit on a business card, being forced to lengthen your name is not perceived as a good thing.
Domain names conflict with trademarks. Some names are trademarked, and the trademark owners expect the legal protections they experience in the physical world to extend to the electronic world. To these users, who got a domain name first is irrelevant if the use of that name is perceived as violating a trademark that they wish to protect.
As with IP address allocation, the ultimate authority for domain name assignment, and therefore the chain of appeal, is murky. The authority of registries to decide who gets which name was not conferred in the ways people usually think of as legitimate, such as through legislation or treaties. When authority arises as an accident of history - and its exercise has financial implications - lawsuits are bound to occur. When they do, there is significant uncertainty about whom to sue and in what venue. This problem is especially acute for disputes involving iTLDs. If, for example, the parties disputing the name and/or the InterNIC are in separate countries, redress may be hampered by the very real limits of the international legal system.
Evaluating Proposals for Change
Having described how the Internet is coordinated today, we now propose a series of questions to ask about suggested changes. These questions are based on our analysis of the factors that have made the Internet's unconventional organizational model perform well in some ways but poorly in others. Internet old-timers may find that the factors are familiar, but that in some cases we offer a different interpretation of their application to the current situation.
Does the Proposed Change Create Abundance, Instead of Just Managing Scarcity?
Scarcity is a key characteristic that distinguishes administrative from political processes. If there is enough pie to go around, people focus on whether the process for giving out pieces is efficient. If there is not enough pie, then they ask whether the allocation process is fair. For example, it is a political process to decide who can attend MIT, but an administrative one to hand out an identification card to each person who ends up attending. Plenty of groups will challenge the former process, but few will challenge the latter.
Before we undertake the design of political processes or institutions to manage scarce resources, we should first ask ourselves whether the resources really have to be scarce. If they do not, a less controversial technical or administrative solution may be much easier to design and implement.
We base this question on our observation of events surrounding the NSFNET transition, when the Internet went from having a default backbone network managed by the U.S. National Science Foundation (NSFNET) to a mesh of networks with no default. Around the time of this transition (spring 1995), economists predicted that for the Internet to remain usable once the government subsidy was removed, long-haul Internet bandwidth would have to be allocated more efficiently. Bandwidth allocation has not changed, however, and although the Internet certainly has points of congestion today, long-haul bandwidth is rarely among them. Instead, more bandwidth has become available to meet the demand. Long-distance telecommunications is now a competitive industry, at least in the United States. As long as no fundamental limits are being hit, capacity tends to emerge in response to revenue opportunities such as new Internet traffic. A similar dynamic is currently under way in the construction of new interconnection points.
For this dynamic to apply to other Internet coordination problems, the relevant resources must not be hitting fundamental limits. Domain names clearly fall into this category: serious barriers to expansion of the name space are social, not technical. The IETF process has produced many proposals for change, but few (if any) have been implemented because of the perceived need for consensus, which is highly valued but notoriously slow to achieve. After circulating for close to a year, Internet Drafts in this debate appear to be gradually heading toward a consensus for the creation of new TLDs, a step in the right direction.
A recent development that deserves mention is an experimental effort, in the spirit of the Internet's "anyone can" philosophy, to simply add a new TLD, .biz, to an extended root nameserver, and try to get connectivity providers to point their DNS servers at it. This bottom-up approach can create problems: if your network provider does not point to the extended database, you will not be able to send e-mail to foo@bar.biz. But if this approach catches on, it has the positive potential to broaden the name space rapidly.
As discussed above, it is less clear how close we are to reaching fundamental limits to the IP address space. We should be cautious about introducing new allocation mechanisms predicated on a scarcity that is more a matter of debate than fact. If more than anecdotal research reveals that current allocation mechanisms are truly harming providers and users, then we should at least be careful to make any new allocation mechanisms as temporary and narrowly limited in scope as possible, while we focus energy on using new technologies to extend the address space. The worst outcome would be to institutionalize an allocation process that stays in use long after the rationale for it has disappeared.
Are Functionality and Authority Distributed?
Technically, the history of Internet coordination is a story of increasing decentralization, afforded by the development of distributed algorithms robust enough to work on a large scale under hostile, real-world conditions, and their modular insertion into the operational Internet. For example, the Domain Name System was introduced in 1983 as follows:
Currently hosts in the ARPA Internet are registered with the Network Information Center (NIC) and listed in a global table (available as the file <NETINFO>HOSTS.TXT on the SRI-NIC host). The size of this table, and especially the frequency of updates to the table are near the limit of manageability. What is needed is a distributed database that performs the same function, and hence avoids the problems caused by a centralized database.
DNS has come a long way since 1983, but it has not yet hit the limits of decentralization.
The ultimate in decentralization is to put users in control. On the Web, for example, users decide what content to make available. What if they could also participate in a distributed database that would let them decide their domain name in an automated fashion, instead of having to register it through a centralized authority?
Control that is fully distributed to users is not always practical or desirable, as in the case of Internet routing. But what is practical changes over time, and it is better to consider and reject the possibility of user control for a good reason than not to think of it at all.
Adopting a decentralized mindset may also bring out intermediate scenarios that would otherwise not come to mind. For example, what if there were multiple name registries? The ad hoc, e-mail based coordination of the InterNIC, RIPE NCC, and APNIC on IP address allocation policies demonstrates that multiple organizations can successfully share authority. We need not always seek a single institution in which to vest authority. In fact, given the international nature of the Internet, authority is more likely to be workably legitimate if it is distributed. For example, allocations of country-based domain names, which are administered by locally selected authorities according to locally determined policies, have been much less controversial than allocation of names in the international domains.
We should also avoid the temptation to seek a single authority for both naming and addressing. They are different problems, and may be best taken care of by different organizational and technical approaches.
At the CIX/ISOC Internet Infrastructure Workshop held in February 1996, one of the participants argued that operation of DNS registries is fundamentally different from Internet connectivity: it needs a chartering (read: licensing) process and cannot be done by just "anyone with a PC and three modems." This statement may be true, but before accepting it, we would first ask, "Why not?" Operating Internet routing appears much more complex than registering domain names, and it is fully distributed among connectivity providers. If tighter control is seen as essential to DNS reliability, then at the least the gain in reliability should be weighed against the creativity and innovation lost by not widely distributing power.
How Well Does the Proposed Change Afford Technical Evolution?
Ever since journalists began to notice the Internet, they have been reporting the fatal flaws that are going to stop its growth. The list of flaws keeps changing, however. The Internet has survived as long as it has by adapting, and there is no reason to expect this evolution to stop. The Internet's modular architecture allows it to embrace technical change one component at a time. If anything, the pace of change has accelerated as the Internet has become attractive to venture capitalists.
Proposed solutions to Internet coordination problems should leave room for change. For example, some of the pressure for "good" domain names comes from people's need to guess email and Web addresses. Internet search and indexing systems have made tremendous progress over the past two years, although they are still not as good as we would like them to be. If a really good, commonly used directory service were to emerge, it would remove a lot of today's pressure on domain names, and we would not then want to be stuck with a big institutional hammer for what has become a small nail.
Institutional solutions that might be appropriate for today's technology could turn out to be burdensome for tomorrow's; at their worst, they might even delay the development of tomorrow's technology. The Internet experience to date suggests that technical evolution should always be considered as a possible solution to coordination problems, ahead of institutionally based arrangements.
Will All Stakeholders Perceive Authority as Legitimate?
Authority can only be readily exercised if it is perceived as legitimate by all stakeholders. IANA derived its authority from the Internet community's shared history and trust in Jon Postel. It would be naive to expect such authority to remain unchallenged as the community grows to encompass large numbers of stakeholders who share neither of those.
This question has different implications for addressing and naming. Addresses are meaningful to the provider community, so it makes sense to propose that authority for addressing end up in organizations that overlap with that community (for example, IANA, and provider consortia such as the CIX, RIPE NCC, and APNIC). But it is fantasy to suggest that authority for the domain name appeals process will be perceived as legitimate if it is assigned to IANA in its present incarnation, the Internet Society (ISOC), or the Internet Architecture Board (IAB). The stakeholder community for domain name assignments is the whole world, and none of these organizations comes close to being representative.
The usual solution when everyone is a stakeholder is to let governments represent them; but governments are notoriously bad at handling highly technical, rapidly changing issues, and intergovernmental organizations are even worse. Practically speaking, the appeals process for Internet coordination disputes is now the same as the appeals process for anything else in the world: the courts. As we have already noted, the courts are less than ideal for resolving international disputes. But in this world of increasingly global business, the Internet is hardly alone with that problem - it is just out in front.
Courts are also less than ideal for resolving disputes of any technical complexity - a realm in which the authority of organizations like the IAB may be perceived as more legitimate. Perhaps an intermediate solution can be found in which Internet technology organizations play a technical advisory role to standard legal proceedings.
In this chapter we have shown how the fundamental Internet Protocol is designed to create a minimally coercive system, in which everyone benefits from collective interaction while retaining as much local choice as possible. We have described the technical and cultural coordination mechanisms used to achieve interoperability, and discussed their organizational affordances - the broadly decentralized decision-making that gives 99 percent of the Internet its characteristic openness, diversity, and bottom-up dynamism. We have put into context the major controversies surrounding the remaining one percent of Internet coordination, having to do with the allocation of IPv4 address space and assignment of domain names. Finally, we have suggested four questions to ask about proposed changes to Internet coordination, and discussed how they apply to some of the current problem cases.
We hope that reading this chapter has caused you to critically examine the mindset you bring to the questions raised in this volume. Since many of the functions under discussion have historically been performed under the funding and direction of the U.S. government, it is not surprising that we tend to focus on institutions of various sorts as their eventual home. But this instinct can lead us astray when dealing with a system that is as fundamentally decentralized as the Internet. It would not surprise us if changes to the current system end up taking place in a bottom-up, "anyone can" manner, or if authority ends up scattered across many different organizations, not concentrated into a single institution. In other words, it would not surprise us if coordination of domain name assignment and IP address allocation eventually looked a lot more like coordination of the rest of the Internet.
Acknowledgments We wish to thank Professor Thomas Malone and our colleagues at the Center for Coordination Science for providing a stimulating environment in which to research and write this paper. This work was supported by a grant from the Kapor Family Foundation.
Bibliography
Clark, David D. 1988. The Design Philosophy of the DARPA Internet Protocols. In 1988 Sigcomm Symposium. (Stanford, CA: ACM Press). 106-114.
Clark, David D. 1996. Interoperation, Open Interfaces, and Protocol Architecture. In White Papers: The Unpredictable Certainty: Information Infrastructure Through 2000, ed. Computer Science and Telecommunications Board of the National Research Council. Washington, D.C.: National Academy Press.
Computer Science and Telecommunications Board of the National Research Council. 1994. Realizing the Information Future: The Internet and Beyond. Washington, D.C.: National Academy Press.
Conrad, David Randy. 1996. Administrative Infrastructure for IP Address Allocation. CIX/ISOC Internet Infrastructure Workshop.
Hafner, Katie and Matthew Lyon. 1996. Where Wizards Stay Up Late: The Origins of the Internet. New York: Simon & Schuster.
Kane, Margaret. 1996. What's in a Name? Lots, If It's a Domain. PC Week Online (July 31).
Mockapetris, P. 1983. Domain Names - Concepts and Facilities. Network Working Group Request for Comments 882.
Nash, Kim S. and Bob Wallace. 1995. Internet Hiccup. Computerworld (September 11): 1, 16.
Norman, Donald A. 1989. The Design of Everyday Things. New York: Doubleday.
Partridge, Craig and Frank Kastenholz. 1996. Technical Criteria for Choosing IP the Next Generation (IPng). In IPng: Internet Protocol Next Generation, ed. Scott O. Bradner and Allison Mankin. Reading, Mass.: Addison-Wesley.
Postel, Jon. 1994. Domain Name System Structure and Delegation. Network Working Group Request for Comments 1591.
Red Herring Editors. 1996. Letter to Bill Gates: ActiveX vs. Java. The Red Herring (August 1996): 34-36.
Rekhter, Y. and T. Li. 1996. Implications of Various Address Allocation Policies for Internet Routing. Network Working Group Request for Comments 2008.
Resnick, Mitchel. 1994. Turtles, Termites, and Traffic Jams: Explorations in Massively Parallel Microworlds. Cambridge, Mass.: MIT Press.
Segal, Ben M. 1995. A Short History of Internet Protocols at CERN. CERN PDP-NS.
U.S. District Court for the Eastern District of Pennsylvania. 1996. Adjudication
on Motions for Preliminary Injunction in ACLU v. Reno, ALA v. U.S. Department of Justice.
1
On January 13, 1997, for example, the AltaVista Web search site reported that it had indexed "31 million pages found on 476,000 servers." See <http://altavista.digital.com/>.2 Such choice is not always considered an advantage. Users without much time, or technical sophistication or interest, may prefer to let someone else package a fully integrated service for them. This is the niche that the on-line service providers are currently filling with respect to the Internet. They are moving away from the old model, in which they were tied to their own versions of each component, toward being able to select what they consider to be the best competitive alternative for each piece on the user's behalf.
3 If this is ever not true, it is considered a bug in the software -- the browser, the server, or both.
4Internet connectivity provision is a highly dynamic industry; estimates at the time of this writing put the total number of commercial providers in the United States in the 2-3,000 range, with approximately six to ten of these having achieved national scope. See the Maloff Company's 1995-1996 Internet Service Provider Marketplace Analysis for more quantitative information about this industry (more information about this report is available at <http://www.trinet.com/maloff/>).
5U.S. District Court Ofr The Eastern District Of Pennsylvania (1996), paragraph 11.
6 As a practical matter, Internet protocols are organized into levels of functionality, or layers. Lower-layer protocols such as IP provide general-purpose services such as interconnecting networks and exchanging bits, while higher-layer protocols like HTTP provide specialized services such as exchanging documents. Multiple higher-layer protocols, each with its own specialized purpose, can take advantage of the same lower-level services. Layered organization is seen often in computing. Consider, for example, a personal computer which runs a lower-layer, general-purpose program -- the operating system -- to support multiple, task-specialized higher-layer programs -- applications such as spreadsheets and word processors. Instead of each application having to include code to drive, say, the computer's printer, the operating system incorporates this function and provides it as a service to the applications. Layering is also evident in the physical world. For example, many types of delivery services, including documents (e.g., Federal Express), pizza (e.g., Domino's), and furniture (e.g., United Van Lines) layer on top of roads -- a common, general-purpose infrastructure for transporting material goods. See , pp. 146-7 for a historical look at the development of Internet layering.
7 See Segal (1995) for an inside look at the TCP/IP adoption process.
8 These descriptions refer, respectively, to the packet radio network and the terrestrial ARPANET, two of the original networks ARPA wished to interconnect. The needs described here are adapted from and from an interview with David Clark (1988), October 24, 1995.
9 See Clark (1996) and Computer Science and Telecommunications Board of the National Research Council (1994) for more in-depth discussion of the layering issues in IP's design.
10 Interview with Robert Kahn, April 26, 1996.
11 Norman (1989), p. 9, defines affordances as "the perceived and actual properties of the thing, primarily those fundamental properties that determine just how the thing could possibly be used . . . . A chair affords (`is for') support and, therefore, affords sitting." We are not claiming that the uses of technologies are completely predetermined by their technical properties, only that those properties make certain uses easier or harder and therefore more or less likely.
12 Clark (1996).
13 See Resnick (1994) for a discussion of the centralized mindset that leads people to make erroneous assumptions, such as that a flock of geese must have a leader.
14The entrepreneurs who succeed may find it worthwhile to vertically integrate later, but this step does not have to happen at the beginning when money and credibility are in shorter supply.
15Partridge and Kasten holz (1996) , p. 176.
16 The several large routing brownouts reported over the past year can be considered a grand experiment in this regard. See, for example, Nash and Wallace (1995). Routing management is currently performed in a decentralized, ad hoc manner by the network engineers employed by Internet connectivity providers. Providers who perform more manual configuration are generally at greater risk of failure. Keeping routing working properly on a day-to-day basis could well be the most labor-intensive component of Internet coordination today (interview with Jon Postel, May 2, 1996) -- dwarfing the forms of coordination that have institutional components (i.e., naming and addressing)..
17 For a discussion of the tension between making software ubiquitous and restricting it to a single platform (i.e., making it non-interoperable), see Red Herring Editors (1996).
18 Interview with Robert Kahn, May 26, 1996; interview with Tony Rutkowski, November 6, 1995.
19 Unlike the other standards fora mentioned above, the IETF is not a membership organization. Anyone can attend IETF meetings or participate in e-mail discussions. Decisions are made by consensus instead of by vote, and attendees are treated as individuals, not representatives of organizations. The results of the process -- draft and final Request for Comment (RFC) documents -- are freely available to anyone over the Internet.
20 Interview with Jon Postel, May 2, 1996. Postel's official title at ISI is Associate Director for Networking. The name IANA is intended to refer to a role, not an institution or person. People often blur this distinction, however, since the person behind the role has always been Jon Postel.
21 The U.S. government funding comes from NSF because Network Solutions started doing the Internet registry job in the NSFNET days.
22 This description is based on an interview with Jon Postel, May 2, 1996. See Conrad (1996) for a more in-depth discussion of IP address allocation. See also the Web pages for RIPE NCC <www.ripe.net>, APNIC <www.apnic.org>, and InterNIC <rs.internic.net> for more details on each organization's historical origins and evolution, as well as <www.isi.edu/div7/iana> for more information about IANA.
23 Conrad (1996).
24 Personal communication with Randy Conrad of APNIC, September 1996.
25 These technologies include: address translation, which would allow large networks to be represented by a small number of external addresses; and automated network renumbering, which would make it more reasonable for registries to allocate smaller blocks of addresses.
26 Conrad (1996).
27 See Mockapetris (1983) and Rekhter and Li (1996) as starting points to gain a deeper appreciation of the linkage between routing and addressing. Renumbering of existing networks may also be required to contain routing table explosion.
28 Users can also apply directly to registries if they know to whom to apply. The necessarily brief description in this section is mainly based on an interview with Jon Postel, May 2, 1996. Among the many RFCs with more information about the domain naming system, good places to start are Postel (1994) and Kane (1996).
29 This job is not without its humorous moments. Postel relates that he once got letters from two different branches of one country's government, each proclaiming a different entity to be the authority. He handled it by exchanging the letters between them and telling them to "get back to me when you decide."
30 See the notes from MIT's workshop on Internet Economics, held in March 1995 and available at <http://rpcp.mit.edu/Workshops/iew-notes.txt>. Fundamentally different assumptions regarding scarcity, and the differences in outlook to which they lead, were quite evident in discussions between economists and technologists at the workshop. Economic education often involves studying the optimal allocation of scarce resources. The Internet confounds the resulting economic worldview by suboptimally allocating abundant resources and still working well enough. Papers from the workshop are available at <http://www.press.umich.edu:80/jep/econTOC.htm>.
31 Servers and local access infrastructure are much more likely to be at fault. See also "Internet Meltdown!: Imminent or Unlikely?" by Stuart Feldman of IBM Research, available at <http://www.alphaWorks.ibm.com/>.
32 See and <http://www.alternic.net>. This effort is independent of IANA and the InterNIC, illustrating the practical limits to their authority imposed by the Internet's architecture. One could get the impression from reading RFCs and Internet Drafts that some constellation of the IETF, Internet Architecture Board (IAB), and/or Internet Society (ISOC) has the authority to decide what will happen to the domain name space. AlterNIC's initiative demonstrates the more bottom-up reality of the change process.
33 This problem is similar to what employees experience when their organizations' internal telephone systems have not yet been updated with new area codes: they cannot place calls to certain telephone numbers.
34 Mockapteris (1983), p.1.
35 See Clark (1988).
36 Some would reverse this argument to claim that routing brownouts over the past year point to the need for licensing connectivity providers. We have heard this argument from some existing providers, who certainly understand the technical issues involved better than we do, but who would also clearly benefit from higher entry barriers.