The previous chapters presented a process for developing software
applications by combining existing components. The purpose of
this chapter is to provide empirical evidence for the feasibility
of the proposed approach, and explore different aspects of its
usefulness in facilitating software reuse at both the code and
architectural level. The chapter begins by presenting SYNTHESIS,
a prototype implementation of the concepts and processes described
in Chapters 2-5. SYNTHESIS has proven that the ideas presented
in this thesis can indeed form the basis of a component-based
software application development environment. The rest of the
chapter is devoted to a detailed description and discussion of
four experiments, performed using SYNTHESIS, that explore different
aspects of the system.
6.1 SYNTHESIS: A Component-based Software
Application Development Environment
SYNTHESIS is a prototype implementation of the concepts and processes
described in Chapters 2-5. It provides an integrated environment
for developing software applications by combining existing components.
The system provides support for:
Creating and editing software architectural diagrams written in the SYNOPSIS language
Maintaining repositories of SYNOPSIS entities (activities, dependencies, ports, resources), organized as specialization hierarchies.
Transforming SYNOPSIS diagrams into executable code by applying
the design process described in Section 5.3
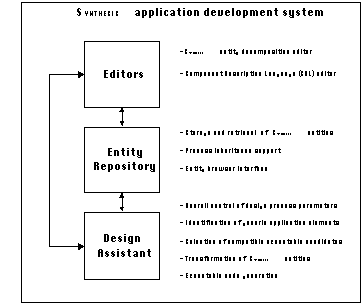
The high-level structure of the SYNTHESIS system is shown in Figure
6-1.
Figure 6-1: A high-level overview of the main
pieces and functions of the SYNTHESIS prototype system.
The current implementation of SYNTHESIS runs under the Microsoft
Windows 3.1 and Windows 95 operating systems. SYNTHESIS itself
has been implemented by composing a set of components written
in different languages.
Kappa-PC provides an interpreted object-oriented programming language
called KAL. It allows other applications to remotely invoke KAL
statements using a Windows interapplication communication protocol
called Dynamic Data Exchange (DDE). Likewise, Visual Basic
supports the definition of subroutines that can be invoked from
other applications using DDE. DDE has been used to implement the
two-way communication between the Kappa-PC and Visual Basic parts
of SYNTHESIS.
VISIO can act as a graphics server for other applications through
a Windows protocol called OLE automation [Microsoft94].
OLE automation allows an application to act as a globally accessible
object, offering a set of methods to other applications. Other
applications can control the server by invoking the methods of
its associated OLE object. OLE automation has been used to implement
the communication between Visual Basic and VISIO.
6.1.2 SYNOPSIS Language Editors
SYNTHESIS supports all features of the SYNOPSIS architecture description
language described in Chapter 3. It provides a graphical editor
for creating and editing SYNOPSIS entities, implemented using
the VISIO drawing tool. Composite entities can be exploded
in place, in order to show their decomposition, and SYNOPSIS
diagrams can be zoomed in and out to show lower-level elements
in more detail. Exploding an atomic activity (i.e. an activity
with no decomposition), brings up a component description language
(CDL) editor for specifying the details of a code-level component
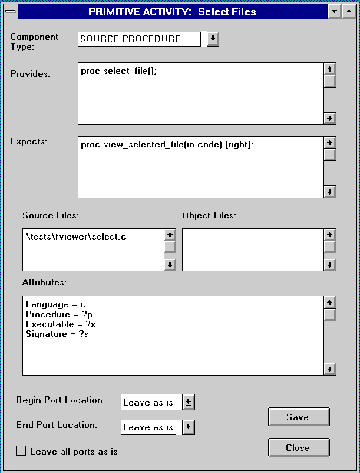
to be associated with that activity (see Section 3.3.1.2).
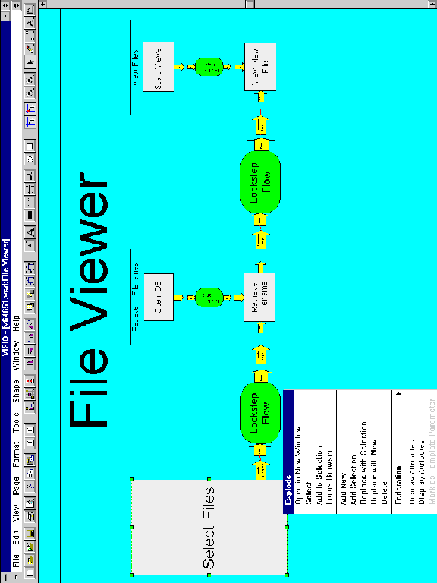
Figure 6-3: Component Description Language Editor
The currently supported code-level component types are listed
in Table 6-1. As explained in Section 5.2.3, support for additional
components can be built by specifying caller and wrapper activities
for decoupling their interfaces into sets of independent local
variables. SYNTHESIS allows designers to define a new component
type, simply by adding an instance of a simple class, containing
information such as the CDL keyword used to specify the component
kind, and the names of caller and wrapper activities.
| Component Type | CDL Keyword | Description |
| Source procedure | proc | A source code procedure or equivalent sequential code block (subroutine, function, etc.) |
| Source module | module | A source code module, consisting of one or more source code files and containing its own entry point (main program). Module components interact with the rest of the application through expected interfaces only. |
| Filter | filter | A source code procedure that reads its inputs from and/or writes its outputs to sequential byte streams |
| Executable | exec | An executable program |
| DDE server | ddes | A DDE server embedded inside an executable program |
| OLE server | oles | An OLE server embedded inside an executable program |
| Gui-Function | gui | A function provided by the graphical user interface of some executable program, typically activated through a key sequence |
SYNTHESIS stores all SYNOPSIS entities created by users in specialization
hierarchies, implemented using Kappa-PC's dynamic class hierarchies.
All new entities are created as specialization children of some
other stored entities. As described in Section 3.2, new entities
inherit the decomposition and all attributes of their specialization
parents and can differentiate themselves by subsequent modifications.
SYNTHESIS supports multiple inheritance, that is, an entity
can have more than one specialization parent. It that case, the
entity inherits the union of the decomposition and attributes
of all its parents.
Specialization hierarchies can be accessed and manipulated through
an entity browser interface, providing tree-like views
into the hierarchies (Figure 6-4). To facilitate browsing and
navigation, specializations of a given entity can optionally be
grouped together under a set of bundles. The entity browser
distinguishes bundles from specialized entities, by enclosing
the latter inside an oval. Browser elements without an oval are
bundles.
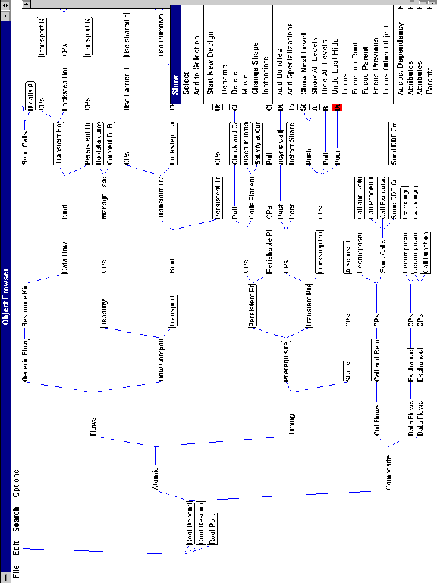
Figure 6-4: Entity browser interface showing part
of the dependencies hierarchy. Dependencies close to the root
are unmanaged. Dependency specializations with associated coordination
processes are organized under bundles named "CPs".
The most important use of the entity repository in the current
implementation is for maintaining a "design handbook"
of increasingly specializaed dependency types. The "design
handbook" is used by the design assistant, in order to semi-automate
the process of generating executable applications, as described
in Chapter 5.
Chapter 4 presented a general design space for dependencies and
coordination processes. The current implementation of SYNTHESIS
contains a repository based on translating a subset of that design
space into a specialization hierarchy. The current repository
contains coordination processes specialized for handling flow
and timing dependencies among components written in C and Visual
Basic, and running under UNIX or Windows.
It is emphasized that the entity repository can also be used for
building specialization hierarchies of composite activities, representing
alternative software architectures for solving frequently occurring
problems. These architectures can be easily specialized and reused
inside other activities using the SYNOPSIS machinery. In that
manner, SYNTHESIS can potentially be useful as a tool for architectural-level
reuse. A related project, which pursues similar concepts for
the storage and reuse of business processes is described in [Malone93,
Dellarocas94].
The end-goal of SYNTHESIS is to assist users in transforming SYNOPSIS
architectural diagrams into executable applications. Once a designer
has completed entering and editing a SYNOPSIS application architecture
(represented as a composite activity), he or she may enter the
tool's design mode.
During design mode, the tool arranges its various windows as shown
in Figure 6-5. The SYNOPSIS decomposition editor (in the lower
half of the screen) displays the current state of the architectural
diagram and updates it automatically whenever a new transformation
(replacement of activity or management of dependency) takes place.
The entity browser (in the upper left part of the screen) is used
for displaying and selecting compatible specializations for application
design elements. Finally, a new window, the design manager
(in the upper right part of the screen), summarizes the status
of the design process and allows users to control its parameters.
During the first stage of the design process, the design assistant
scans the target application architecture, augments primitive
activities with callers and wrappers (as described in Section
5.2.3), and collects all generic elements into a to-do list
displayed in the design manager window.
The design process (see Section 5.3) then proceeds as follows:
The design assistant picks the next element of the to-do list.
It zooms in that element in the decomposition window and scans
all corresponding specializations that exist in the repository.
For each of them, it optionally applies the compatibility checking
algorithm of Figure 3-15, in order to determine whether it can
be used in the current context. Finally, it presents the results
of that search in the entity browser window (with compatible elements
highlighted) and prompts the user to select one of the candidates
(Figure 6-5). If no compatible candidate could be found, it prompts
the user to enter a compatible specialization of the corresponding
element and continue the process. This process continues until
the to-do list becomes empty. The system then automatically generates
code, as explained in Section 5.2.4.
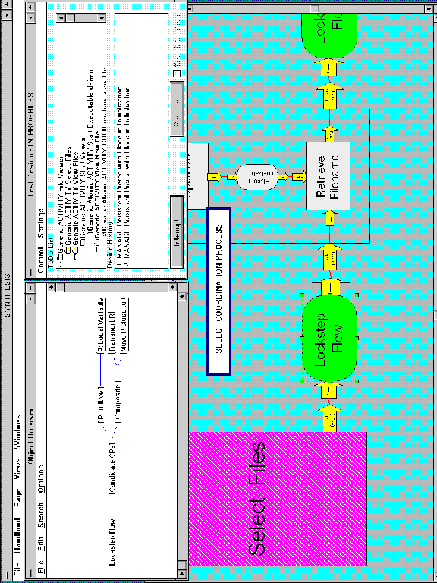
The design process can be customized in a variety of ways.
The design assistant is currently performing a simple exhaustive
search of all candidate elements for a given transformation. For
large repositories of processes, this may be prohibitively expensive.
Additional filtering and pruning methods (e.g. based on attribute
values) should be developed to speed up the search in such cases.
The code generation component is currently capable of generating
Visual Basic and C code only. However, as explained in Section
5.2.4, most of the code generation machinery is language independent.
SYNTHESIS allows designers to add support for additional languages
simply by defining a new instance of a class containing a few
relatively simple language-specific methods (Table 6-2).
| Method | Arguments | Description |
| MakeArgumentDecl | name, type | Generate a declaration for a procedure formal parameter |
| MakeCall | name, type, parameter list | Package a name and list of actual parameters into the correct syntax for a local procedure call |
| MakeCondBranch | condition list | Generate the correct language-specific syntax for a conditional branch |
| MakeFileFooter | name | (Optional) Generate language-specific source code file footer statements |
| MakeFileHeader | name | (Optional) General language-specific source code file header statements |
| MakeProcFooter | name | Generate the syntax for ending a procedure call of given name |
| MakeProcHeader | name, type, parameter list | Generate a header statement for a procedure of given name, type, and formal parameter list |
| MakeLabel | label number | Generate a label (branch target) |
| MakeLocalDecl | name, type | Generate a local variable declaration of given name and type |
Table 6-2: Set of methods that must be defined in order to be able to generate code for a new language.
6.2 Experiment 1: A File Viewer Application
6.2.1 Introduction and Objectives
The purpose of our first experiment was to investigate how well
our system can integrate a set of heterogeneous components in
a relatively simple application. We were also interested in testing
the exploratory design capabilities of our approach. More
specifically, our objective was to demonstrate how the system
can assist designers integrate the same set of components in a
number of different ways, by selecting alternative coordination
processes for managing the specified dependencies.
The target application is a simple file viewer, whose purpose
is to repeatedly ask users for code numbers through a simple user
interface, retrieve filenames corresponding to each user-supplied
code number from a database, and display the contents of the retrieved
filenames using a text editor. The file viewer application has
already been introduced as a vehicle for explaining various aspects
of the system in Chapters 3 and 5.
The components used were source modules written in different programming
languages (C and Visual Basic), as well as one executable program.
6.2.2 Description of the Experiment
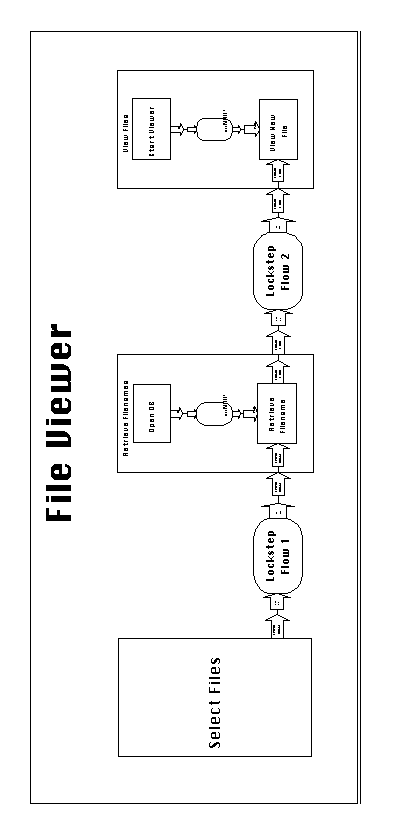
Figure 6-6 depicts a SYNOPSIS architectural diagram for the File
Viewer application. The diagram is explained in detail in Section
3.2, where it was used to give an overview of the SYNOPSIS language.
The components used to implement each of the activities shown
in the architectural diagram were the following:
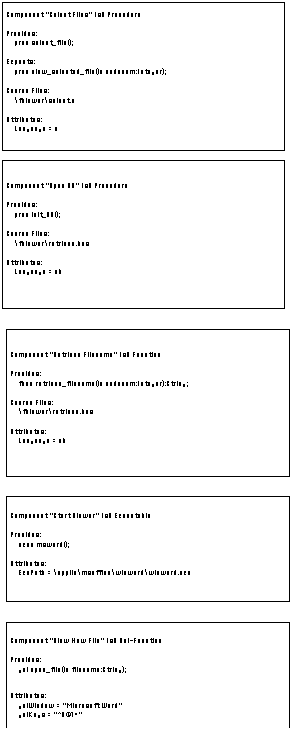
Figure 6-7 depicts the SYNOPSIS definitions linking executable
activities to their associated implementation-level components.
Section 5.4 gives a detailed, step-by-step account of how SYNTHESIS can generate an executable implementation of an integrated file viewer application by successively transforming the architectural diagram of Figure 6-6. The generation process is based on successively replacing unmanaged dependencies with specializations associated with a compatible coordination process.
In several cases, more than one compatible specializations might
exist for a given dependency. In those cases, users can eliminate
some alternatives by using common sense or design heuristics built
into the system. If the remaining alternatives are still more
than one, users can explore the use of more than one processes,
thus creating several implementations of the same application.
They can then compare their run-time efficiency, or other performance
criteria, and select the one that performs best.
In the file viewer application, there were two cases where more
than one compatible coordination processes could have been selected:
When managing Persistent Prerequisites 1 and 2, there were three
compatible choices (Figure 5-18):
Of the previous three processes, choice 3 is clearly too heavyweight
for the application at hand. However, choices 1 and 2 could be
equally efficient.
Likewise, when managing Flow 1, there were two compatible choices
(Figure 5-17):
Choice 1, based on operating system support for transferring data
and control between two different executable programs residing
in the same Windows-based machine, is more efficient when transmitting
small pieces of data, like we do in this example. However, for
large data transfers, choice 2 might also become a viable alternative.
In the implementation described in Section 5.4, we have selected
choice 1 for managing each of the above dependencies. We also
tested the use of choice 2 for both the prerequisites and the
flow dependency. Appendix A.1 lists the coordination code generated
by SYNTHESIS in each of the two cases.
This experiment has demonstrated that SYNTHESIS can resolve low-level
problems of interoperability, such as incompatibilities in programming
languages, data types, procedure names, and control flow paradigms.
The components used in this example were written in different
languages and forms (source and executable). However, their interfaces
were essentially compatible. For example, the component to which
activity Select Files expects to send each user-supplied code
number (a procedure call accepting one argument), was essentially
compatible with that provided by activity Retrieve Filename (a
procedure call accepting one argument). The mismatches were all
of a low-level nature (different procedure names, different languages,
different executables), and SYNTHESIS was able to resolve them
completely automatically. The next experiment will focus on components
which have some more fundamental architectural mismatches
in their interfaces and assumptions.
The experiment has also demonstrated the exploratory mode of design
encouraged by the system. The system is able to use the compatibility
checking mechanism described in Section 3.4 to automatically eliminate
some of the candidate coordination processes for a given dependency.
For example, when managing Flow 1, it was able to eliminate all
processes of Figure 5-17 which were not suitable for managing
flows between Windows-based components that will be packaged in
different executables. However, even after this elimination has
taken place, more than one compatible alternative processes typically
remained. Currently, designers are responsible for selecting among
alternative processes by using their experience and common sense
judgment. A promising path of future research is to codify design
rules for selecting coordination processes. The development of
successful design rules will enable the complete automation of
application generation from SYNOPSIS diagrams.
6.3 Experiment 2: Key Word In Context
6.3.1 Introduction and Objectives
In an influential 1972 paper [Parnas72], David Parnas described
the Key Word in Context (KWIC) index system and used it
to compare different approaches for dividing systems into modules.
Recent papers on software architecture [Garlan88, Garlan94] have
used the same application to illustrate and contrast different
software architectural styles.
Parnas described his Key Word in Context (KWIC) example application
as follows:
The KWIC [Key Word in Context] index system accepts an ordered
set of lines, each line is an ordered set of words, and each word
is an ordered set of characters. Any line may be "circularly
shifted" by repeatedly removing the first word and appending
it at the end of the line. The KWIC index system outputs a listing
of all circular shifts of all lines in alphabetical order.
In this experiment, we made yet another use of Parnas's
KWIC example. Our objectives were the following:
6.3.2 Description of the Experiment
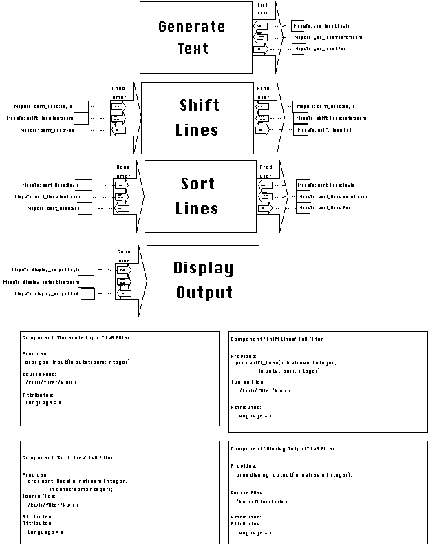
It is easy to construct a SYNOPSIS architectural diagram from
Parnas's description of the KWIC system (Figure 6-8). In this
experiment we used three sets of alternative component implementations:

Figure 6-8: SYNOPSIS description of the Key Word
in Context system.
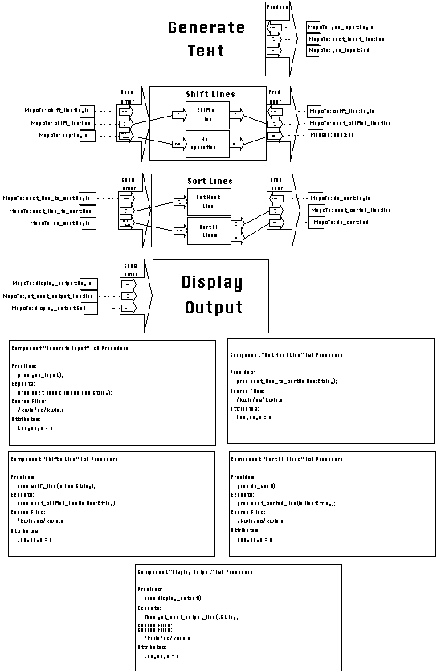
In [Garlan94], Garlan and Shaw examine three different architectures
for implementing the KWIC system:
In this experiment, we used the SYNTHESIS system to generate an
implementation of the KWIC example for each of the above three
sets of components and each of the three different architectures.
Overall, our objective was to construct 9 alternative implementations.
SYNTHESIS was able to generate all 9 implementations. In 7 out
of 9 cases the results were of comparable efficiency with hand-written
code. In the two cases where the system was not able to generate
an efficient solution, the components used could not efficiently
be integrated in the desired organization because of conflicting
assumptions embedded in their code. The results of the experiment
are summarized in Table 6-3. Appendix A.2 contains the coordination
code generated by the SYNTHESIS in each case.
The following is a description of the most interesting aspects
of each experiment:
Set A: Filter Components
| Components | Architecture | Lines of automatically generated coordination code * | Lines of manually written coordination code * | |
| Set A (Filters) | Pipes | |||
| Set A (Filters) | Main Program/Subroutine | |||
| Set A (Filters) | Implicit Invocation | |||
| Set B (Servers) | Pipes | |||
| Set B (Servers) | Main Program/Subroutine | |||
| Set B (Servers) | Implicit Invocation | |||
| Set C (Mixed) | Pipes | |||
| Set C (Mixed) | Main Program/Subroutine | |||
| Set C (Mixed) | Implicit Invocation |
* Line count does not include blank lines or comments.
** Makes use of manually written code for implementation
4.
Implementation 1: Pipe architecture
Pipe coordination processes are the most natural mechanism for
integrating filter components. Filters are examples of components
that embed part of the support for managing their associated flows
into their code. Their abstract producer and consumer interfaces
decompose into identifiers of the carrier resource (a byte stream
resource, such as a pipe or file). The actual statements for writing
and reading data into (from) the carrier resource are embedded
inside the components. Coordination processes for managing flows
between two filter components can be derived from the generic
data flow coordination model presented in Figure 4-21 by removing
the Write and Read activities, which are now part of the component.
It is also assumed that there are no usability considerations.
The resulting generic process is shown in Figure 6-11(b) and forms
the basis for a set of coordination mechanisms for managing data
flows among filters.
The specialization that uses UNIX pipes as the carrier resource
is shown in Figure 6-11(c) Since a UNIX pipe is only accessible
to processes created by a common ancestor, the process manages
the accessibility dependency for the pipe by forking a child process
to execute the data flow consumer activity. The data flow producer
activity is executed by the same thread that opens each pipe.
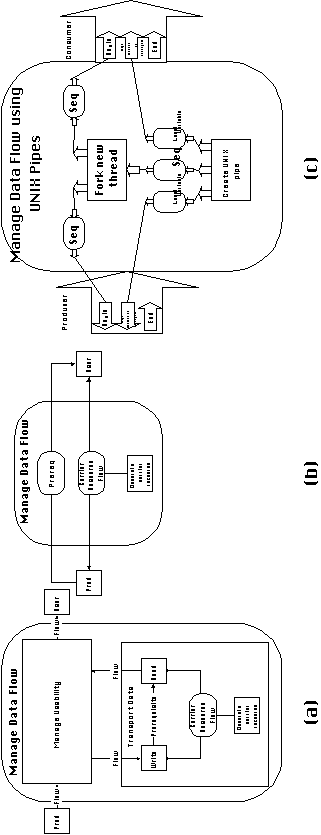
Figure 6-11: A coordination process for managing
flows between UNIX filters and its relationship to the generic
flow coordination process of Figure 4-21.
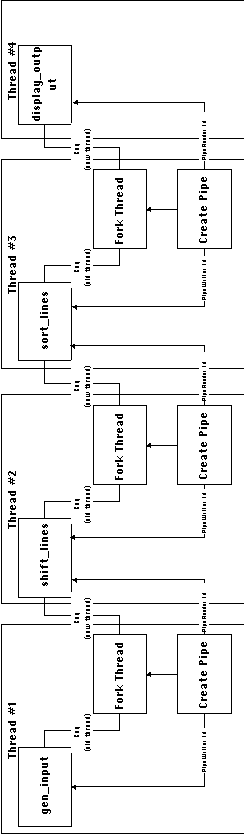
Figure 6-12 shows the resulting organization of Implementation
1.
Implementation 2: Main program-subroutine architecture
Although filter components are designed with pipe architectures
in mind, they can also be used in sequential main program-subroutine
architectures by using explicit sequentialization to manage the
prerequisite between writer and reader. In this case, each filter
reads (writes) its entire input (output) stream before control
is passed to the next filter. Sequential files, rather than pipes,
are used to implement the carrier resource, to avoid deadlock
problems with finite capacity pipes. The resulting organization
is shown in Figure 6-13.
This combination might be useful for reusing filter components
in environments which do not support pipes or concurrent threads.
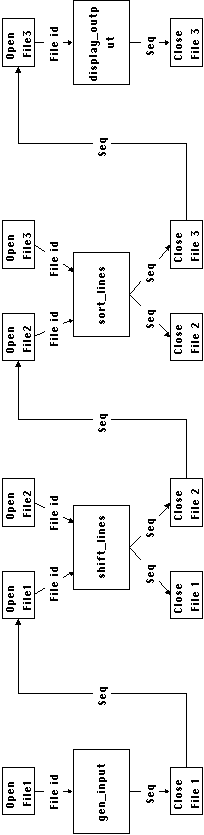
Figure 6-13: Implementation 2 (Filter components
organized in a main program-subroutine architecture)
Implementation 3: Implicit invocation architecture
In implicit invocation architectures, as defined in [Garlan88],
interacting components are being executed by independent threads
of control and synchronize using shared events. In the coordination
process design space of Chapter 4, this definition corresponds
to managing flows and prerequisites using peer coordination processes
(see Figures 4-10 and 4-11).
Filters contain built-in support for pipe communication protocols,
which have many features in common with implicit invocation protocols.
Any other interaction protocol for connecting a filter to other
components must be built on top of the pipe protocol: Values written
to a byte stream by a writer filter must first be read from the
stream, possibly assembled into other data structures, and subsequently
passed to the new interaction protocol. At the other end of the
protocol, values have to be disassembled into byte sequences and
fed into another stream that will transport them to the corresponding
reader filter.
Although possible in theory, such an approach achieves nothing
except to introduce a redundant additional layer of communication
and synchronization. Nevertheless, SYNTHESIS was able to generate
a solution even in this case. No sensible designer would select
such a solution however, because of its unnecessary complexity
and inferior performance relative to the previous two implementations.
The resulting organization and detailed code generated by SYNTHESIS
in this case are given in Appendix A.2 (Implementation 3).
Set B: Server Components
Implementation 4: Pipe architecture
The generic data flow coordination process of Figure 4-21 can
be specialized to handle this combination as follows:
select pipe protocol process to manage Transport Data
specialize conversion activities of Manage Usability to convert
line input to and from byte streams.
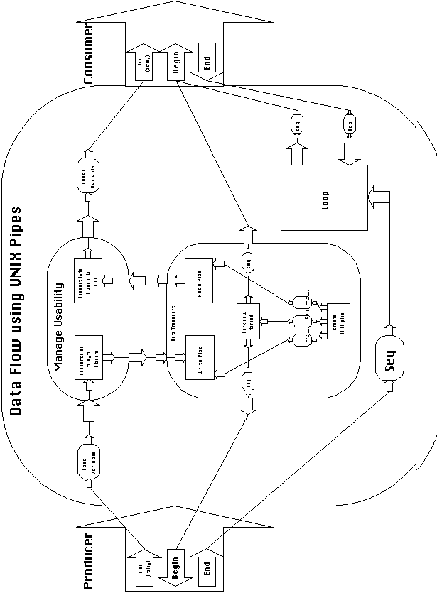
Figure 6-14: Decomposition of a data flow coordination
process using UNIX Pipes
The resulting process is shown in Figure 6-14. In this particular
experiment, the SYNTHESIS library contained the generic process
of Figure 4-21 and a specialization of Transport Data using pipes.
It did not contain specializations of conversion activities to
transform lines to and from byte streams. During design, SYNTHESIS
asked the user to manually add such specializations.
Figure 6-15 shows the resulting organization of Implementation
4.
Implementation 5: Main program-subroutines architecture
The first two flows can be trivially managed by local variables. The interest in this experiment concentrates on the management of Flow 3. In this case the interfaces at both ends of the flow are client interfaces (The sorting component calls next_sorted_line in order to output a line of text. The display component also calls get_next_output_line in order to retrieve the next line to display). This rules out the possibility of using push or pull organizations to manage the flow (in those organizations, one of the flow participants must play a client role and the other a server role).
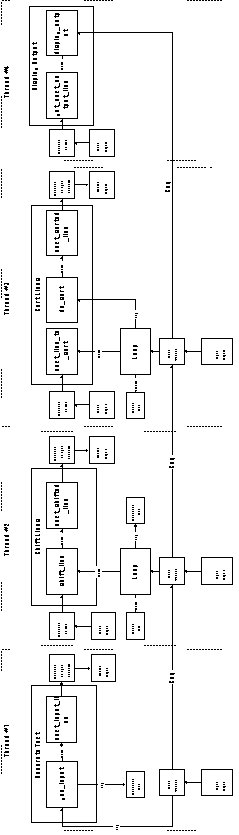
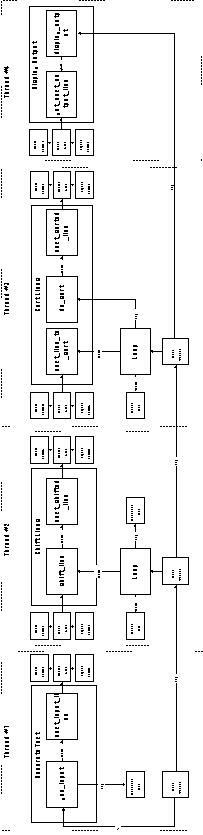
* semaphore initialization is omitted for clarity
Figure 6-16 summarizes the overall organization of this implementation.
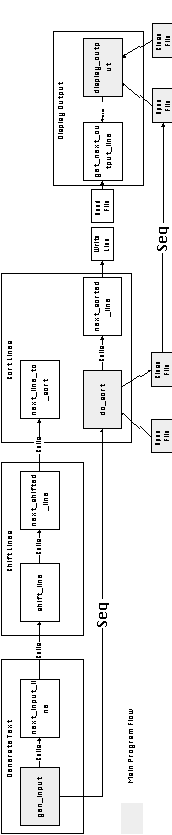
Figure 6-16: Implementation 5 (Server components
in main program-subroutine organization)
Implementation 6: Implicit invocation architecture
An implicit invocation architecture can be generated by managing
all flows by coordination processes using peer organizations.
This requirement translates into managing the prerequisite embedded
inside each flow using shared events (see Figure 4_11). In this
experiment, we have implemented all flows using a lockstep flow
coordination process (specialization of cumulative flow). We have
selected a global string variable as our carrier resource and
implemented the shared event lockstep prerequisite using semaphores
(two semaphores for each prerequisite).
Figure 6-17 shows the resulting organization of Implementation
6.
Set C: Mixed components
Implementation 7: Pipe architectures
We will explain the management of Flow 1. The other two dependencies
can be similarly managed. In Flow 1, the producer side is implemented
using a filter and the consumer side has a server interface. As
explained above this implies that the statement for writing data
into the carrier resource is embedded inside the producer. A specialization
of a flow with this assumption can be easily constructed from
the generic model of Figure 4-21. The specialization which has
been selected in this example is shown in Figure 6-18.
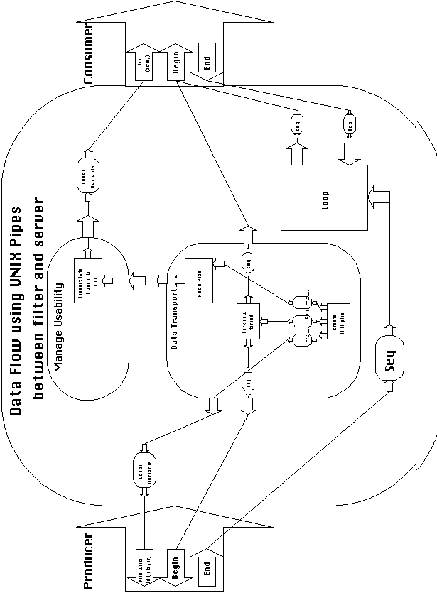
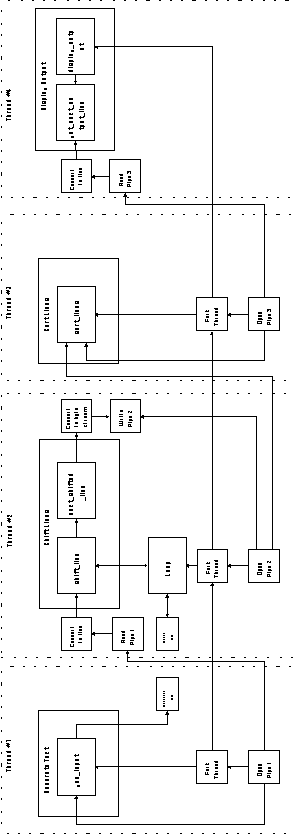
The overall organization of the resulting implementation is shown
in Figure 6-19.
Implementation 8: Main program-subroutine architecture
By using sequential files, rather than pipes, as the carrier resource,
filters and server components can be combined into a main program-subroutine
architecture using a coordination strategy similar to that of
Implementation 2. The resulting organization is shown in Figure
6-20.
Implementation 9: Implicit invocation architecture
As explained in the description of Implementation 3, filters have
embedded support for pipe communication protocols and assume that
their flow partners will also be using the same protocol. Any
implicit invocation protocol must be built on top of the pipe
protocol. This results in an additional, redundant layer of communication
and synchronization. For that reason, filter components cannot
efficiently be integrated into implicit invocation architectures.
Nevertheless, SYNTHESIS was able to generate a solution, even
in this case. No sensible designer would select such a solution
however, because of its unnecessary complexity and inferior performance
relative to the previous two implementations. Interested readers
are referred to Appendix A.2 (Implementation 9) for more details.
The first experiment (Section 6.2) has shown that SYNTHESIS is
able to integrate components with mismatches in expected and provided
programming languages, procedure names, and parameter data types,
but essentially compatible architectural paradigms and interfaces.
This experiment went one step further to demonstrate that the
system can resolve more fundamental architectural mismatches
between components. Architectural mismatches are mismatches in
the assumptions each component makes about the structure of the
application in which it will be used. The practical consequence
of this ability is that it gives designers the freedom to select
components independently of their interfaces.
At the same time, the experiment has demonstrated that the overall
architecture of an application can be selected to a large degree
independently from the architectural assumptions of each individual
component. The same set of components can be organized into a
set of different architectures, simply by selecting different
coordination processes. In this experiment, the choice of coordination
mechanisms, rather than the component implementation, was the
defining factor in the resulting software architecture. One
of the practical benefits of this observation is that it enables
designers to use the system in order to port the same set of components
to different environments, which might support different interaction
and communication mechanisms.
Finally, the experiment has shown that the flexibility of integrating
a component in a given overall organization is inversely proportional
to the amount of interaction assumptions that are already built-into
the component. For example, filter components, which contain more
assumptions about their interaction partners than simple procedures,
could not be efficiently integrated into implicit invocation (peer)
architectures other than pipes. Approaches, such as ours, are
very good at adding additional coordination machinery around components.
They cannot always undo the effects of coordination assumptions
already embedded inside components.
In the current implementation of SYNTHESIS, responsibility for
selecting the coordination processes which result in the desired
overall architecture falls to the designer. One interesting path
for future research would be to investigate how different commonly
occurring architectural styles can be expressed as constraints
on the design dimensions of our coordination process design space.
In the preceding description of this experiment, we have informally
hinted at some of those constraints (e.g. that implicit invocation
architectures constrain the management of flow and prerequisite
dependencies by peer organizations only). If we can successfully
express architectural styles as coordination design space constraints,
our multi-dimensional design space of coordination processes can
provide a useful vehicle, both for defining styles as points in
our space (combinations of design choices), and for providing
more specific guidelines as to which design choices are consistent
with a desired architectural style. Finally, our design space
could help invent and characterize new styles, for which
widely-accepted names do not yet exist.
6.4 Experiment 3: An Interactive TEX-based
Document Typesetting System
6.4.1 Introduction and Objectives
TEX is a popular document typesetting system, originally developed
by Donald Knuth in the late 1970s [Knuth89].The original TEX system
was developed for UNIX machines. Today however, there exist versions
of TEX for most popular platforms.
TEX was developed at a time when graphical user interfaces and
what-you-see-is-what-you-get (WYSIWYG) systems did not
yet exist. As a result, it was built as a set of independent executable
components that are individually invoked from the command line
interpreter. TEX components communicate with one another using
shared files with standard extensions. The procedure for processing
a document using the TEX system can be summarized as follows:
Users initially create a text file (with the standard extension
.tex), containing the text of the document interspersed with TEX
formatting commands. The .tex file is then passed to the TEX processor,
which "compiles" all commands and creates a device
independent image file of the typeset document (with standard
extension .dvi). Dvi files can then be previewed by a graphical
viewer. Finally, dvi files can be converted to postscript (filename
extension .ps) and sent to a postscript printer. Figure 6_21 summarizes
the typical invocation sequence of the most important TEX components.
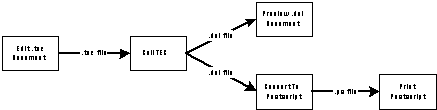
In this experiment, we used SYNTHESIS to combine TEX components
in a way not intended by their original designers. Instead of
sequentially editing the .tex document, invoking TEX, and subsequently
calling the viewer, our aim was to build a system that approximates
the WYSIWYG behavior of modern word processors: While users are
editing the .tex file, the system runs TEX in the background and
automatically updates the dvi viewer. In that manner, the effect
of user modifications on the final typeset form of a document
should be quasi-instantaneously visible.
Our objectives in selecting this experiment were twofold:
6.4.2 Description of the Experiment
In this experiment, we followed a three-step process:
The following is a description of the most interesting aspects
of each step.
a. Define a generic SYNOPSIS architecture
The first-level decomposition of the SYNOPSIS diagram for an Interactive
TEX system is shown in Figure 6-22. Dependencies have been labeled
with numbers for easy reference in the text that follows.
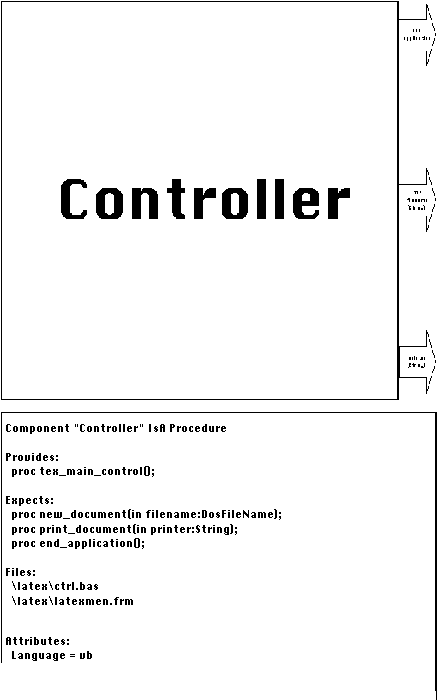
The Controller activity represents a graphical user interface
that offers three functions to users:
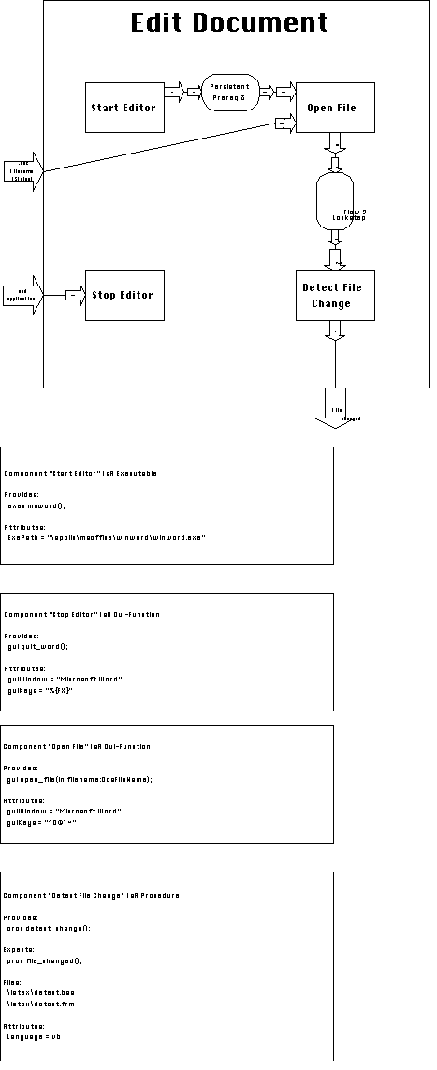
Activity Edit Document is responsible for editing the text of the .tex document. It consumes each new .tex filename produced by the Controller, and generates a File Changed control signal whenever the .tex document is modified. It also provides a port for detecting end of application signals.
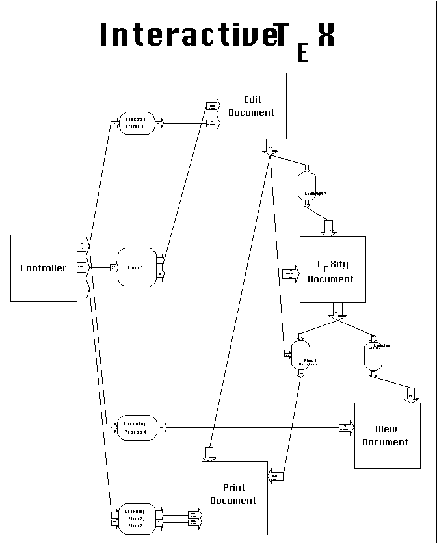
Activity TEXify Document also consumes the .tex filename produced
by the Controller. It depends on the File Changed signal produced
by Edit Document through Lockstep Prerequisite 5: Every time File
Changed is produced (i.e. every time the user modifies the currently
open .tex file), TEXify Document begins execution, processes the
current .tex file, and produces a new version of the corresponding
.dvi file.
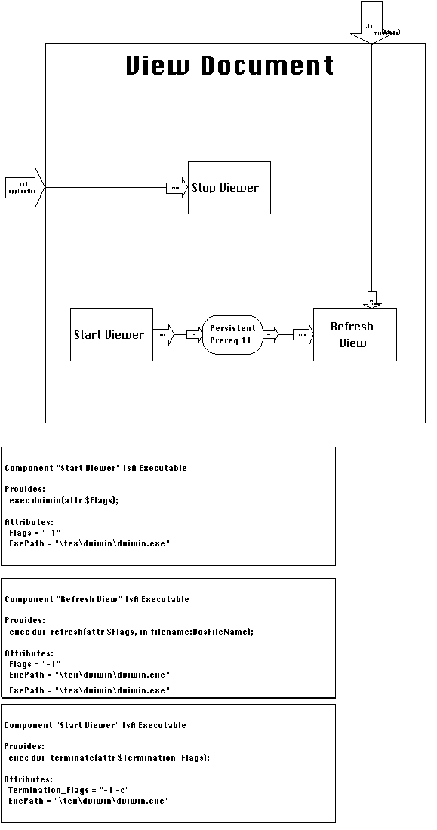
Activity View Document is responsible for graphical viewing of
.dvi files. Each new version of a .dvi file produced by TEXify
Document must flow into View Document and update the graphical
viewer. End of application signals terminate the viewer.
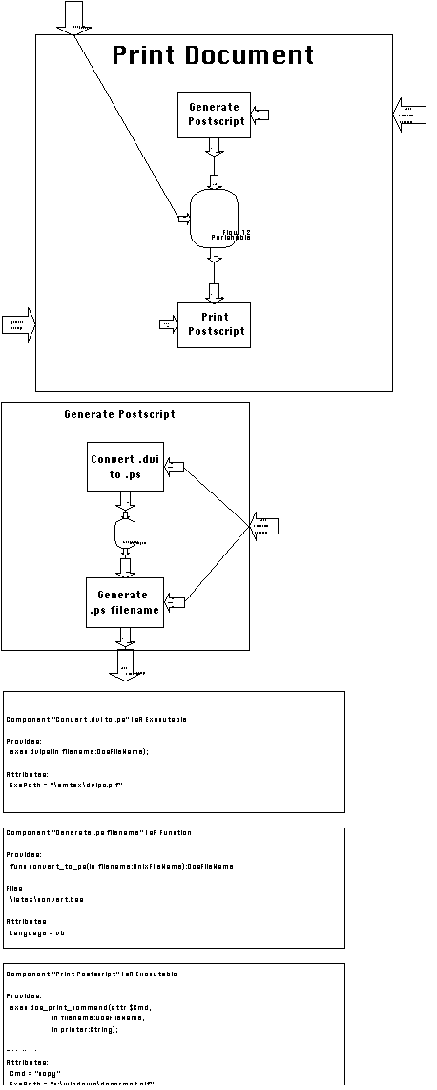
Finally, activity Print Document is responsible for printing the
currently open document at the user's request. Every time it receives
a printer name from the Controller (signaling the issuing of a
Print command), it converts the current .dvi file to postscript
and sends it to the specified printer.
Since TEX components were intended to be used one at a time, they
provide no support for managing sharing or synchronization dependencies.
When attempting to integrate them in an interactive system, a
number of interesting dependencies arise. Some of them are visible
in the top-level decomposition of the diagram:
Activities Edit Document and TEXify Document concurrently use
the .tex file, which remains open in the text editor while TEX
runs in the background. If one of the components restricts access
to the file, special coordination must be installed. This sharing
relationship is captured by using a single flow dependency (Flow
1) connecting both file users. As mentioned in Section 4.5.4,
the management of sharing dependencies is one of the default decomposition
elements of every flow dependency to multiple users.
Modifications in the .tex file invalidate the previous versions
of the .dvi and .ps files, which have to be regenerated before
they can be used for viewing and printing. This is captured by
connecting the File Changed port to the invalidation ports of
two perishable flows (Flow 6, visible in Figure 6-22 and Flow
12, visible in Figure 6-27). The role of those flows will become
apparent when we discuss the decomposition of Print Document.
b. Specialize the architecture
The top-level architecture of our TEX system is independent of
the components that will be used to implement each activity. Lower-level
decompositions and mapping of ports to interface elements must
take into account the nature of the components that will be used.
We performed this experiment on a Windows machine and selected
components available for that environment.
The Controller was implemented using a Visual Basic form showing
a set of buttons for each offered function (Figure 6-23). In this
experiment, we wrote the (minimal) code implementing the component.
However, one can imagine that for such standardized activities,
SYNTHESIS could offer a repository of standard components, organized
as an activity specialization hierarchy.
Edit Document decomposes as shown in Figure 6-24. For this experiment
we selected Microsoft Word as our text editor. MS Word is invoked
as an executable, opens a new file when it receives the key sequence:
CTRL-O, followed by the filename, followed by newline, and quits
when it receives the key sequence: ALT-F, ALT-X.
The most interesting activity is the one that detects file changes.
It is a Visual Basic procedure which, periodically queries Microsoft
Word (using DDE) to check whether the currently open file is "dirty"
(i.e. has been modified since last query). When unsaved changes
are detected, the procedure waits for a pause in user activity
(detected by a series of consecutive queries that return no new
changes). This pause presumably corresponds to the idle time users
typically spend between lines or between sentences. When a pause
is detected, the procedure directs Word into saving the file and
generates the File Changed signal (by calling expected procedure
file_changed).
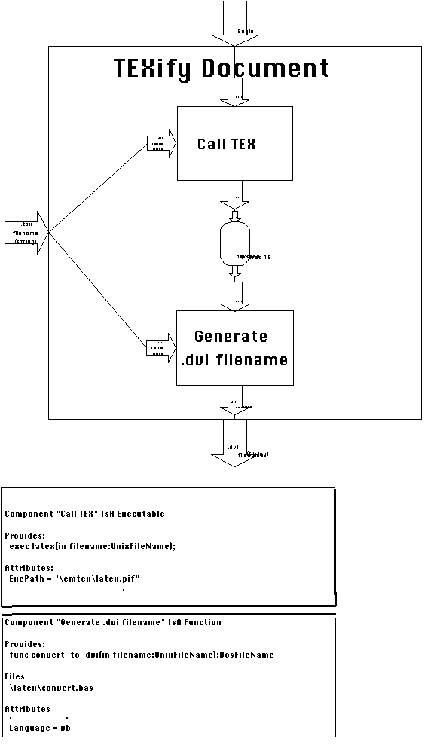
TEXify Document (Figure 6-25) simply calls the TEX program, passing
it the .tex filename, and subsequently generates the corresponding
.dvi filename, to be used by the following activities in the chain
of events. It is interesting to note that the Generate .dvi filename
activity is required to bridge a "mismatch" between
the top-level description of TEXify Document and its lower-level
decomposition into executable components. At the top-level, TEXify
Document is viewed as a black box that consumes a .tex filename
and generates a .dvi filename. The actual TEX program, however,
does not generate any output filename. In order to "fit"
the generic architecture to the components at hand, the conversion
activity had to be inserted.
The decomposition of View Document (Figure 6-26) is similar to
that of Edit Document. In this experiment we used a publicly available
dvi viewer for windows called dviwin [Sendoukas94]. dviwin provides
command line interfaces for starting, refreshing, and terminating
itself: Executing the command line:
dviwin -1 <filename>
starts dviwin and makes it display the specified filename. If
dviwin is already running, the previous command line makes it
refresh its display from the current contents of the specified
filename. To terminate dviwin, users execute the command line:
dviwin -1 -c
Print Document (Figure 6-27) converts .dvi files to postscript
and sends them to a user-specified printer. It is implemented
using the DOS command:
copy <filename> <devicename>
If filename is a postscript file and devicename
is the device name of a connected printer (e.g. lpt1:),
the above command directs the postscript file to the specified
device, without further processing.
Print Document has a number of interesting timing dependencies
with the rest of the system. First, a user might request multiple
printouts of the same version of a .dvi file. Since conversion
of dvi to postscript (performed by a program called dvips) takes
considerable time, it would not be efficient to repeat it for
every print command. For that reason, dependency Perishable Flow
12 was inserted between Generate Postscript and Print Postscript:
After a .ps file has been generated for a given .dvi file, it
can be used by an arbitrary number of Print Postscript activities.
However, every time the .tex file gets modified, the .ps file
becomes invalid and must be regenerated from the updated .dvi
file. This condition is captured by connecting the File Changed
signal coming out of activity Edit Document to the invalidation
port of Perishable Flow 12.
There is another, more subtle timing dependency related to the
previous one. Whenever a .ps flow becomes invalidated, Generate
Postscript must be executed again before further printing can
take place. However, Generate Postscript itself reads a .dvi file
which has been made invalid by the .tex file modification. Therefore,
it also must wait until the latest version of the .dvi file has
been generated by TEX. This dependency is captured by the insertion
of Perishable Flow 6 between TEXify Document and Print Document
at the top-level decomposition of the system (see Figure 6-22).
This dependency also ensures that TEX (which writes the .dvi file)
and dvips (which reads it) do not overlap (Prerequisite dependencies
are a specialization of mutual exclusion, see Figure 4-28).
c. Generate an executable application
The next stage in application development using SYNTHESIS involves
managing the specified dependencies. Most of the dependencies
in this example were easily managed by the coordination processes
we have presented in the previous chapters. The following paragraphs
discuss the most interesting cases.
The most interesting dependency in this example is the sharing
of the .tex file between its two users (Microsoft Word and TEX).
Microsoft Word keeps the file open during the background invocations
of TEX and, unfortunately, locks it for write access. This behavior
is encoded in the filename consumer port of Open New File activity
by setting the attribute Concurrent_Use = False. The DOS implementation
of TEX used in this experiment (emtex) for some reason also opens
the .tex file for write access. This creates a sharing conflict
which cannot be managed by sequentializing access because Word
never releases the file lock. One approach that can solve the
problem in this case is replication: Each user opens a separate
private replica of the file. Before opening a replica, its contents
are updated from the most recently modified replica in the set.
For two users, only one replica needs to be created (the other
user can open the original file).
Another subtle mismatch in managing Flow 1 of the .tex filename
arose from the fact that the command line interface of emtex,
although written for DOS, receives filenames in the UNIX format
(with slashes instead of backslashes). This behavior was indicated
to the system by defining two subtypes of String, DosFileName
and UnixFileName, and using them in the interface descriptions
of the components. The mismatch is handled by the management of
the usability dependency. When managing this dependency, SYNTHESIS
could not find a conversion activity from DosFileName to UnixFileName
and prompted the user to input one.
The selection of alternatives for managing Perishable Flow 12
inside Print Document (see Figure 6-27) is an interesting example
of how SYNOPSIS diagrams and the coordination process design space
can help designers visualize and reason about alternative implementations.
A Perishable flow can be managed in two general ways: using a
consumer pull (lazy flow) organization or using a peer organization,
based on shared events (see Section 4.5.3.2). In pull organizations,
the producer activity does not take place unless explicitly requested
by the consumer. In this example, this would mean that dvips (a
relatively time consuming process for large documents) would not
be executed unless the user needed to print the resulting postscript
file. In contrast, in peer organizations, producer activities
are executed as soon as their inputs become available and then
generate some event to signal their completion. Consumers proceed
asynchronously and detect that event if and when they require
to use the data. In this example, a peer organization would result
in an execution of dvips following each execution of TEX.
Clearly, the pull solution is preferable in this system.
Since all source components in this experiment were written in
Visual Basic, SYNTHESIS was able to integrate them by generating
65 lines of Visual Basic coordination code, listed in Appendix
A.3.
Our previous two experiments focused on testing the power of the
coordination process library in resolving interoperability and
architectural mismatches between components interconnected through
relatively simple dependency patterns. In both cases the architectural
descriptions of the target applications were very simple.
The primary objective of this experiment was to test the expressive
power of SYNOPSIS and the adequacy of the proposed vocabulary
of dependencies in specifying non-trivial applications. After
all, the coordination process library can only be used to manage
what has already been specified by the designer.
Although judgments of this nature are by necessity subjective,
we believe that SYNOPSIS was able to represent the activities
and dependencies of this application with clarity and completeness.
The generic decomposition of flow dependencies (see Section 4.5)
used to manage Flow 1 was able to capture both the sharing and
the filename format conversion requirements between the two users
of the .tex file. The two perishable flows captured in an elegant
way a number of timing dependencies between far-away parts of
the system. The resulting graphical descriptions are relatively
simple and easy to read.
In this experiment, a number of activities, other than the "main"
executable components of the system, had to be manually written.
These activities include the Controller (user-interface), the
filename conversion activities (Generate .dvi filename, Generate
.ps filename) and the file change detection activity (Detect File
Change). This requirement reflects the fact that the resulting
system offers additional application-specific functionality compared
to the original collection of components.
Our system can facilitate the writing of additional activities
by letting users concentrate on the implementation of the required
functionality and taking care of all details related to compatibility
of interfaces. Experiments 1 and 2 provided positive evidence
to support this point.
The final application was a useful tool for TEX users, but still
fell short of providing a real WYSIWYG capability. One problem
was the inevitable delay between the time a user modified the
.tex file, and the time that modification was reflected in the
dvi viewer. This delay was due to the time it takes TEX to process
the .tex file. Unfortunately, TEX can only process entire files.
Therefore, a single modification in a single page of a large document
can take a significant amount of time to propagate to the dvi
viewer.
But even if TEX could instantaneously process documents, another
problem would remain. Tex files intersperse document text and
TEX commands. Since the synchronization between the editor and
TEX is based on relatively simple, TEX-independent heuristics
(e.g. the heuristic for generating file changed signals is based
on detecting a period of busy time followed by a period of idle
time), TEX can be invoked to process a document while the user
is in the middle of entering a TEX command. The resulting .tex
file at the time of processing will contain TEX "syntax"
errors, which might have unpredictable results in the final appearance
of the document. Although such situations rarely result in fatal
errors, they do make the interaction between editing and viewing
TEX files less than seamless.
The root of the problem is due to the coarse-grain nature of the
TEX system components. In order to build a truly interactive TEX
system we would need finer-grained components, such as a "tex-literate"
modifications detector that recognizes when the user finishes
entering/modifying a tex command, and a tex processor that incrementally
processes only those parts of a document that change. As we mentioned
in Chapter 1, the first consideration in reusing software is locating
the right components. Our system can help bridge a large number
of mismatches when the components are almost right, by
building coordination code around them. However, as we observed
in our discussion of Experiment 2 (Section 6.3.3), the stronger
the machinery built into the component, the less the flexibility
of using the component in arbitrary organizations. Our approach
is limited in reusing coarser-grained components in applications
which require finer-grained interfaces.
6.5 Experiment 4: A Collaborative Editor Toolkit
6.5.1 Introduction and Objectives
Collaborative or group editors allow several people
to jointly edit a shared document in a distributed environment.
They support protocols that control which of the collaborating
users are allowed to make changes to the edited document at any
one time, how changes are observed by other users, and how they
are combined and propagated into the final stored copy of the
document.
Collaborative editors have a lot of functionality in common with
conventional, single-user editors. In fact, collaboration support
can be viewed as an extension of the capabilities of a single-user
editor. Therefore, collaborative editor systems can be designed
by reusing existing single-user editor components.
In their CSCW '90 paper, Knister and Prakash describe DistEdit,
a collaborative editor toolkit which provides a set of primitives
that can be used to add collaboration support to existing, single-user
editors [Knister90]. The primitives provided by the toolkit are
generic enough to support editors with different user interfaces.
The authors have tested their approach by modifying two editors,
MicroEmacs and GNU Emacs, both running under UNIX, to make use
of DistEdit.
The procedure for creating a collaborative editor using DistEdit
requires manual identification of the points in the editor code
where DistEdit primitives should be inserted, small modifications
to the editor code in order to fit it to the requirements of DistEdit,
and recompilation of the modified editor code plus the DistEdit
modules to generate the enhanced executable.
Although it is independent of the user interface of any particular
editor, DistEdit depends on the underlying machine and operating
system architecture. It only runs under UNIX and makes use of
ISIS [Birman89], a UNIX-specific communication package.
In this experiment, we used SYNTHESIS to create an "architectural
toolkit" for building collaborative editors, loosely
based on the ideas of Knister and Prakash. Instead of providing
a set of primitive calls to be inserted into the code of an existing
editor, our "toolkit" provides a collaborative editor
architecture, expressed as a SYNOPSIS diagram, to which
the original editor must be "fitted". SYNTHESIS can
then manage dependencies and generate the final executable system.
In contrast to DistEdit, the use of a configuration-independent
SYNTHESIS diagram allows the system to generate collaborative
editors for several different execution environments and communication
protocols, starting from a single description (limited only by
the power of the coordination process repository).
Our objectives in selecting this experiment were the following:
Test the capabilities of the system for constructing "architectural
toolkits" that extend the functionality of existing systems,
when their source code is available.
Test the capabilities and limitations of our vocabulary of dependencies
for expressing many-to-many relationships.
6.5.2 Description of the Experiment
6.5.2.1 Description of the collaboration
protocol
Our experiment implements a collaboration protocol loosely based
on the one used in DistEdit. The following is a brief description
of the protocol:
The protocol is based on the designation of one of the participants
in an editing session as master. Master participants have
complete editing capabilities. The remaining participants are
observers, with no editing capabilities. Observers see
every change and cursor movement made by the master; the observer's
cursor is in "lock-step" with the master's cursor.
Observers cannot perform any operations which change the text.
If attempted, such operations simply have no effect.
At all times, at most one participant can be the master. All others
are observers. When an editing session starts, there is no master.
During that time, any participant can take control and become
the master by pressing a designated key-sequence (which might
be editor-dependent). During the session, a master may relinquish
control by pressing another key-sequence. Once there is no master,
all participants are once again allowed to take control.
During time periods when there is no master, all participants
are allowed to individually edit their buffers. Each local editing
activity is then propagated to all participants. The result is
a truly egalitarian mode of collaborative editing.
Any number of users can participate in a collaborative editing session. Participants can enter and leave the session at will, simply by starting or quitting their instance of the editor program. When a new participant enters the session, if there is a master, the current contents of the master's buffer are written back to disk, before they are loaded into the new participant's buffer. In this way, it is ensured that the buffer contents of all participants are identical at all times.
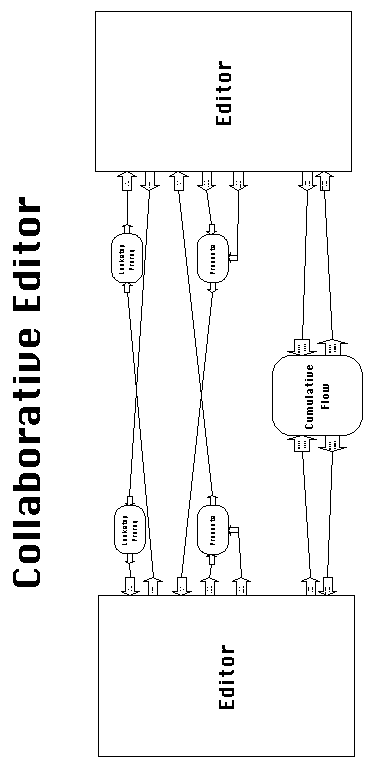
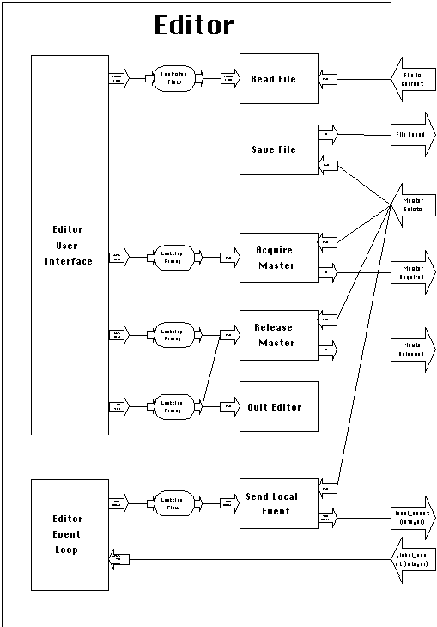
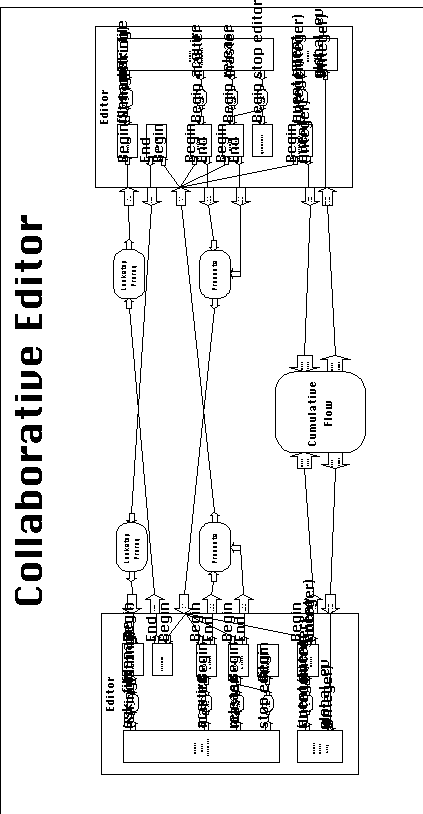

Figure 6-31: Component descriptions used to "fit"
MicroEmacs into the collaborative editor architecture of Figure
6-29.
Should the master leave the session, it first releases its master
status. The remaining participants will then observe a no-master
status and be allowed to take control.
When participants leave a session, they can individually select
to save or not save the contents of their buffers (which are always
in sync). The text being edited can only be lost if all users
leave the session without saving it.
6.5.2.2 A SYNOPSIS architecture
for collaborative editing
A SYNOPSIS architecture for describing a collaborative editor
system which supports the collaboration protocol described in
the previous section is given in Figure 6-28. The architecture
interconnects a set of simpler Editor activities, corresponding
to individual session participants. The decomposition of Editor
activities is given in Figure 6-29.
The detailed description of the system can be better understood
by referring to Figure 6_30, in which the decomposition of Editor
activities has been made visible in the same diagram.
Each Editor activity is based on an existing single-user editor
component. The source code of the editor must be available in
order to use it in this system. Designers are responsible for
"fitting" the source code of the editor to the activity
descriptions of Figure 6-29.
The operation of the overall system is based on a set of Prevents
dependencies (see Section 4.7), each connecting a participant
to all other participants (except itself). Each Prevents dependency
is "enabled" whenever a participant acquires master
status. It is "disabled" whenever that same participant
releases master status. It connects to the Master Exists port
of all other participants. While "enabled", a Prevents
dependency prevents the execution of all Editor activities connected
to the Master Exists port of all participants except the one who
acquired master status.
Extending the user interface
Activity Editor User Interface corresponds to the entire source
code of an existing single-user editor. In order to "fit"
this activity description, the editor source code must be modified
in order to call four external (i.e. undefined inside the module)
procedure calls that interface it with the rest of the architecture:
In most well-designed editors, procedures which handle user command
key sequences are collected together in tables and structures
that can be easily located by designers. "Fitting" an
editor's code to this activity therefore typically only requires
changing the names of the "handler" procedures for reading
files and quitting the editor, and introducing key sequences and
handlers for the two new commands that acquire and release master
status.
The following paragraphs describe the effect of each of the previous
four commands.
a. Acquiring master status
When a user presses the "acquire master" key sequence,
the editor fires the acquire master control port. There are two
possibilities:
b. Releasing master status
When a user presses the "release master" key sequence,
the editor fires the release master control port. The possibilities
here are similar to the previous ones:
c. Quitting the editor
When a user presses the "quit editor" key sequence,
the editor fires the quit editor control port. This passes control
to activity Quit Editor. Designers must map this activity to the
original source code procedure of the editor for quitting the
system. Typically, this procedure asks users whether to save the
current contents of the buffer before quitting.
Before actually quitting, the editor must also release master
status, if it is currently holding it. This is achieved by also
connecting the relevant prerequisite dependency to activity Release
Master, which is executed if no other user is currently holding
master status.
d. Reading a file
When a new participant editor starts, or when a user presses the
"load file" key sequence, the editor user interface
module passes the relevant filename through its filename port.
This invokes the Read File activity, which must be mapped to the
original source code procedure of the editor for loading a file
into its current buffer. However, before this activity can occur,
the current contents of the master's buffer must first be saved,
to ensure that the new participant loads the latest version of
the shared file.
Our architecture expresses this constraint by placing an OR-prerequisite
dependency between each Read File activity and every other participant's
Save File activity. Save File must be mapped to the original source
code procedure of the editor for writing the contents of its current
buffer back to disk.
The prerequisite dependency is satisfied if at least one
of its precedent Save File activities complete. There are two
possibilities:
In order to keep the previous protocol simple, it is executed
every time a participant loads any new file into its buffers.
This might result in unnecessary saves of files in situations
where different participants are, for some reason, loading different
files. It is assumed that all participants are using the editor
to load and edit the shared file only.
Broadcasting master actions
As was mentioned in Section 6.5.2.1, editing activities performed
by the master are transmitted to and are immediately visible by
all observer participants. In contrast, editing activities attempted
by observer participants should have no effect.
At the heart of each editor there exists an event loop.
An editor basically spends most of its time waiting for user (keyboard
or mouse) input. When such input occurs, it is registered by the
event loop as a sequence of events and passed to editor handlers
for processing. Events are integer values, corresponding to keyboard
codes and mouse activities. Event loops typically wait for events,
and place events in an event queue when they occur.
In order to use an editor in a collaborative setting, the function
of its event loop must be modified: Local events detected
at the master editor must be broadcasted to all participants.
Local events detected at observer editors must be discarded. Only
global (broadcasted) events received by an editor should be placed
its event queue and processed.
Our architecture specifies this required behavior as follows:
Activity Editor Event Loop must be mapped into the modified event
loop of each editor. In order to "fit" an editor to
our collaborative architecture, designers must modify its event
loop in order to
Once these modifications are in place, the rest of the architecture
takes care of actually broadcasting and discarding events.
Whenever a local event is detected by an editor's event loop,
there are two possibilities:
Each recipient of a global event returns it back to the modified
event loop through the port global event.
In consistency with our initial description of the protocol, when
no user is holding master status, the above specification results
in the broadcasting of the local events of every participant to
all other participants. The use of a cumulative flow dependency
means that each editor can proceed at its own pace generating
and processing events. The coordination process selected to manage
the flow is responsible for storing all pending events in internal
buffers or queues, separate from the local event queues used by
each editor instance.
6.5.2.3 Generating executable implementations
We have investigated the capabilities of our architectural toolkit
by using it to convert one test system, MicroEmacs [Lawrence89]
into a collaborative editor. MicroEmacs is written is C and its
source code is available for free. There exist versions of the
system for both UNIX and Windows environments. Therefore, it is
an ideal candidate for testing the configuration-independence
claim of our architectural toolkit.
"Fitting" MicroEmacs to our toolkit required the following
manual modifications:
The above modifications are very similar to the ones described
in [Knister90]. Once the modifications were performed, SYNTHESIS
was able generate the additional coordination code needed to generate
the final executable applications. The DDE "Wildconnect"
feature was used to implement broadcast in the Windows implementation.
Sockets were used in the UNIX version. Appendix A.4 lists the
generated coordination code.
In this experiment, SYNTHESIS did not perform Stage 3 of the algorithm
of Section 5.3, because it is assumed that the editor modules
contain all necessary packaging code for starting and initializing
themselves. It simply generated the additional coordination code
files which were then manually linked with the original editor
object files to build the final executable.
This experiment has demonstrated the usefulness of SYNOPSIS and
SYNTHESIS for building architectural toolkits which extend
the functionality of existing applications. Architectural toolkits
are an attractive alternative to conventional toolkits based on
libraries of procedure calls. Their primary advantage lies in
their ability to generate alternative implementations, suitable
for a variety of different environments and configurations, starting
from a single architectural description. In contrast, conventional
call-based toolkits are usually restricted to the environments
for which they are originally developed.
The process of generating an enhanced application by using a conventional
toolkit can be summarized as follows:
The process of generating an enhanced application by using an
architectural toolkit is analogous:
"Fit" the application into the various activities of
the toolkit that describe parts of it. This might involve locating
specific parts of the application and/or making some modifications.
As we can see, the manual effort required in both cases is comparable.
The advantage of the architectural toolkit approach lies in the
fact that it does not require rewriting the toolkit for different
environments. It can also be used to generate many alternative
implementations for the same environment, to allow experimentation
with alternative ways of organizing synchronization or interprocess
communication.
From the point of view of the expressing power of our vocabulary
of dependencies, this experiment, again, has demonstrated how
a non-trivial synchronization and communication protocol can be
specified and implemented by the use of relatively simple dependency
patterns.
On the other hand, this experiment has indicated a shortcoming
of the current SYNOPSIS implementation in expressing many-to-many
relationships. Currently, many-to-many dependencies must have
a statically fixed number of members. In this example this means
we can describe collaborative editors with a fixed maximum number
of participants. Figure 6-28 specifies the architecture of an
editor with two participants. The diagrams can be easily modified
to add more participants (by adding additional instances of the
Editor activity and replacing all dependencies with equivalent
versions for the desired number of participants). However, the
maximum number of participants specified by each diagram must
be fixed in advance.
Future research ought to extend the language with constructs for
expressing many-to-many relationships between an undefined number
of activities.
The purpose of this chapter was to demonstrate the feasibility
of our approach, and explore different aspects of its usefulness.
More specifically, our objectives were to demonstrate:
The prototype implementation of SYNTHESIS has proven that the
ideas presented in the previous chapters of the thesis can indeed
form the basis of a system for developing applications from existing
components. SYNTHESIS has also enabled us to carry out the experiments
to which the main body of this chapter is devoted.
Experiment 1 (File Viewer) has demonstrated that the system is
able to resolve low-level problems of interoperability, such as
incompatibilities in programming languages, data types, procedure
names, and control flow paradigms. It has also shown how the system
can facilitate the exploratory design of alternative component
organizations.
Experiment 2 (Key Word In Context) has provided positive evidence
for the ability of the system to resolve more fundamental architectural
mismatches, that is, different assumptions about the structure
of the application in which they will be used. It has also demonstrated
that the overall architecture of an application can be specified
to a large extent independently of the implementation of any individual
component, by appropriate selection of coordination processes.
Finally, it has shown that the flexibility of using a component
in alternative organizations is inversely proportional to the
coordination machinery built into the component.
Experiment 3 (Interactive TEX System)
has tested the power of SYNOPSIS and our proposed vocabulary of
dependencies in expressing non-trivial application architectures.
It has also investigated the strengths and weaknesses of our approach
for combining coarse-grained components, such as executable programs
into new applications that require finer-grained interaction.
Finally, Experiment 4 (Collaborative Editor) has investigated
the usefulness of the system for developing architectural toolkits
that extend the functionality of existing source code programs.
Architectural toolkits are an attractive alternative to conventional
toolkits based on libraries of procedure calls. Their primary
advantage lies in their ability to reuse a single architectural
description in order to generate alternative implementations,
suitable for a variety of different environments.
Overall, the experiments presented in this chapter have demonstrated
that that the proposed architectural ontology and vocabulary of
dependencies were capable of accurately and completely expressing
the architecture of the test applications. Furthermore, they have
provided positive evidence for the principal practical claims
of our approach, which can be summarized as follows:
Support for code-level software reuse: SYNTHESIS was able
to resolve a wide range of interoperability and architectural
mismatches and successfully integrate independently developed
components into all four test applications, with minimal or no
need for user-written coordination software.
It is difficult to provide a rigorous proof of the merits and
capabilities of a new design methodology for building complex
systems. There is certainly room for improvement in every aspect
of the ideas presented in this thesis. Nevertheless, the positive
results of this chapter suggest that the approach proposed by
this research is a step in the right direction, both for facilitating
code-level and architectural software reuse, as well as for helping
structure the thinking of designers faced with problems of organizing
software components into larger systems.