The principal objectives of the work described in this thesis
are:
Both are important and difficult problems. Not surprisingly, they
have received attention in a variety of different research areas.
This chapter describes the various areas which relate to this
thesis and explains the similarities and differences between major
research efforts in each area and our work. We begin with an overview
of the two research areas that have most strongly influenced this
work: software architecture and coordination theory. The rest
of the chapter describes other approaches for component composition
and software reuse and discusses how they relate (or do not relate)
to our approach.
As the size and complexity of software systems increases, the
design and specification of overall system structure, or software
architecture, emerges as a central concern. Architectural
issues include the gross organization of a system, protocols for
communication, synchronization, and data access, assignment of
functionality to design elements, and selection among design alternatives.
Architectural designs are important for at least two reasons.
First, an architectural description makes a complex system intellectually
tractable by characterizing it at a high level of abstraction.
In particular, the architectural design exposes the top level
design decisions and permits a designer to reason about satisfaction
of system requirements in terms of assignment of functionality
to design elements. Second, architectural design allows designers
to exploit recurring patterns of system organization. Such patterns
ease the design process by providing routine solutions for certain
classes of problems and by supporting reuse of underlying implementations.
While, until recently, the practice of architectural design was
largely ad hoc, the topic is receiving increasing attention from
researchers and practitioners and is emerging as an explicit discipline
within software engineering [Perry92, Garlan94].
Within the emerging field of software architecture research, there
are several closely related subareas, including:
The following paragraphs will give a brief overview of the above
subareas, and will discuss how this thesis relates to each of
them.
7.1.1 Languages for Architectural Description
Until recently, system designers had at their disposal two primary
ways of defining software architecture: they either used the modularization
facilities of existing programming languages and module interconnection
languages (see Section 7.3.1), or they described their designs
using informal diagrams and idiomatic phrases (such as "client-server
organization"). In a number of position papers [Shaw94a,
Shaw94b] Shaw has articulated the shortcomings of both those approaches,
and the need for specialized architectural description languages.
A number of recent and ongoing research projects are focusing
on developing suitable notations for the description of software
architectures [Kogut94b]. A common theme in most of these projects
is the provision of separate abstractions for describing components
and connectors. Components represent the major computational
or data pieces of an application and correspond to implementation-level
entities, such as program modules, databases, remote servers etc.
Connectors represent mechanisms for describing interactions among
components, such as procedure calls, pipes, event systems, blackboard
systems, etc.
The two systems that are most closely related to SYNTHESIS are
Shaw's UniCon [Shaw95] and Garlan's Aesop [Garlan94b].
UniCon
UniCon provides a general-purpose architectural description language
based around two distinct kinds of abstractions: components and
connectors.
Components define computational capabilities. They consist of
an interface that specifies the capabilities the component exports
and an implementation, which may be primitive or composite. Currently
supported component types include source modules, shared data,
files, filters, and processes.
Connectors mediate interactions among components. A connector
consists of a protocol that specifies the class of interactions
the connector provides and an implementation. Only primitive connectors
are currently supported, although support for composite connectors
is planned. Built-in connector types include pipes, sequential
file i/o, procedure calls, shared data access, and real time scheduling.
UniCon can express and check appropriate compatibility restrictions
and configuration constraints using a mechanism analogous to type
checking.
SYNOPSIS has many features in common with UniCon, including a
clear separation between activities and coordination processes,
the ability to specify and combine multiple component kinds in
the same system, and the provision of a mechanism for performing
compatibility checks. SYNOPSIS differs from UniCon in two fundamental
ways:
Aesop
Whereas the focus of UniCon is to make it possible to combine
a wide variety of component and connector types within a given
system design, Aesop focuses on providing support for developing
style-specific architectural development environments. Each of
these environments assists and constraints designers into producing
applications which conform to a given architectural style.
Architectural styles are recurring organizational patterns and
idioms, such as pipe-filter, client-server, and event-based architectures.
Each style can be expressed by specifying:
Aesop enables the specification of architectural styles using
a mechanism similar to subtyping. A style-specific vocabulary
of design elements is introduced by providing subtypes of the
basic architectural classes or one of their subtypes. Stylistic
constraints are then supported by the methods of these types.
Aesop combines the description of a style with a shared toolkit
of common facilities to produce an environment, called a fable,
specialized to that style. Fables are application development
environments. They assist and constraint designers into producing
applications which conform to the specific architectural style
supported by the fable.
SYNTHESIS shares with Aesop the objective of assisting designers
to rapidly build correct application architectures. However, instead
of assisting designers to conform to a given architectural style,
the objective of SYNTHESIS is rather to help them explore and
select the architectural style which better suits the requirements
of their particular problem. As we have demonstrated in Section
6.3, component implementations might constrain the applicability
of particular styles. Furthermore, the optimal organization of
a number of components often requires mixing several different
styles in the same system. Restricting designers to using a single
style would not enable them to cope with the first situation,
or to take full advantage of the second.
Section 6.3 has shown that the overall organization of a set of
software components depends to a large extent to the attributes
of the coordination processes used to manage each of their interdependencies.
As we discussed in Section 6.3.3, the coordination process design
space of Chapter 4 might be useful in allowing more precise definitions
of architectural styles as set of constraints on coordination
process design dimensions. Overall, clarifying the relationship
between architectural styles and our design dimensions of coordination
processes is a promising path of future research.
7.1.2 Architectural Taxonomies and
Handbooks
Most mature engineering disciplines have long ago recognized the
importance of classifying and codifying accumulated design knowledge
into architectural frameworks and design handbooks. The existence
of such handbooks facilitates design reuse and helps focus the
design effort to the truly innovative parts of a new system.
Software engineering has only recently recognized the central
role of common design patterns and idioms, often referred to by
the term architectural styles [Garlan94]. Early efforts
to identify, name, and analyze these patterns include Shaw's 1989
categorization of a number of idioms [Shaw89]. Garlan and Shaw
later extended this list [Garlan94], providing several examples
of their use in understanding real systems. Perry and Wolf [Perry92]
also recognized the importance of architectural patterns and outlined
the use of styles in characterizing applications such as compilers.
A different, but related, area of activity has recently emerged
in the object-oriented community through the articulation of (object-oriented)
design patterns [Gamma93]. Inspired, in part, by Christopher Alexander's
work on pattern languages [Alexander77], these efforts have led
to handbooks of common patterns for organizing software [Gamma94,
Pree95]. The patterns usually consist of a small number of objects
that interact in specific ways. A typical example is the Model-View-Controller
pattern, identified by the creators of Smalltalk for organizing
user interface software [Krasner88].
Our research focuses on leveraging code reuse by providing a taxonomy
and handbook of software interconnection or coordination mechanisms.
In contrast to object-oriented design patterns, our taxonomy is
independent of any language paradigm and is based on very abstract
notions such as resource flow and resource sharing. Language-specific
coordination patterns can be expressed as specializations of more
generic patterns. For example, a UNIX-specific pipe transfer protocol
is defined as a special case of a language-independent protocol
for transporting data from a single producer to a single consumer,
which, in turn, is defined as one generic process for managing
one-to-one data flow dependencies. One of the main objectives
of our taxonomy is to allow the expression of application architectures
in a configuration-independent way (e.g. in terms of activities
interconnected through resource flow dependencies), that can subsequently
be specialized for different sets of components and supported
interaction mechanisms.
7.1.3 Domain-Specific Software Architectures
A growing number of industrial research and development efforts
are creating domain-specific architectural styles, or reference
architectures, for specific product families [Mettala92].
This work is based on the idea that a common architecture of a
collection of related systems can be extracted so that each new
system can be built by "instantiating" the shared architecture.
Examples include the standard decomposition of a compiler, standardized
communication protocols, fourth generation languages (which exploit
the common patterns of business information processing), user
interface toolkits and frameworks, and various product architectures
in domains such as command and control, avionics, manufacturing,
and mobile robotics.
SYNTHESIS provides several features that support the development,
storage, and reuse of domain-specific software architectures.
First, SYNOPSIS architectural diagrams can be specified to be
as generic or as specific as desired. Second, they can be stored
in the entity repository and reused in other architectures. Third,
they can be specialized and refined, in order to incorporate specific
components, or to generate coordination code for specific environments.
Sections 6.4 and 6.5 describe two examples of domain-specific
architectures: one for a TEX-based
document typesetting application and one for a collaborative editor.
In both experiments, a single abstract top-level architecture
was specialized to "fit" the components at hand, and
dependencies were managed by appropriate coordination processes
for each target configuration.
Coordination theory [Malone94] is an emerging research area that
focuses on the interdisciplinary study of coordination. Research
in this area uses and extends ideas about coordination from disciplines
such as computer science, organization theory, operations research,
economics, linguistics, and psychology. Its intended applications
include, but are not limited to, understanding the effects of
information technology on organizations and markets, assisting
the development of successful cooperative-work tools, and helping
design efficient distributed and parallel computer systems. In
all those domains, a coordination perspective can help (1) analyze
alternative designs and (2) suggest new design ideas. Table 7-1
summarizes some sample applications of a coordination perspective.
Coordination theory defines coordination as the process of managing
dependencies among activities. Its research agenda includes characterizing
different kinds of dependencies and identifying the coordination
processes that can be used to manage them. Table 7-2 lists a subset
of the original list of dependencies identified by Malone and
Crowston.
This work is directly related to coordination theory, in that
it applies a coordination perspective to software applications.
Our work views the process of developing applications as one of
specifying architectures in which patterns of dependencies among
software activities are eventually managed by coordination processes.
| Application Area | Examples of analyzing alternative designs | Examples of generating new design ideas |
| Organizational structures and information technology | Analyzing the effects of decreasing coordination costs on firm size, centralization, and internal structure | Creating temporary "intellectual marketplaces" to solve specific problems |
| Cooperative work tools | Analyzing how the payoffs to individual users of a system depend on the number of other users | Designing new tools for task assignment, information routing, and group decision-making |
| Distributed and parallel computer systems | Analyzing stability properties of load sharing algorithms in computer network | Using competitive bidding mechanisms to allocate processors and memory in computer systems. Using a scientific community metaphor to organize parallel problem-solving |
It makes two principal contributions to coordination theory:
This project grew out of the Process Handbook project [Malone93,
Dellarocas94] which applies the ideas of coordination theory to
the representation and design of business processes. The goal
of the Process Handbook project is to provide a firmer theoretical
and empirical foundation for such tasks as enterprise modeling,
enterprise integration, and process re-engineering. The project
includes (1) collecting examples of how different organizations
perform similar processes, and (2) representing these examples
in an on-line "Process Handbook" which includes the
relative advantages of the alternatives.
| Dependency | Examples of coordination processes for managing dependency |
| Shared resources | "First come/first serve", priority order, budgets, managerial decision, market-like bidding |
| Task assignments | (same as for "Shared resources") |
| Producer / consumer relationships | |
| Prerequisite constraints | Notification, sequencing, tracking |
| Inventory | Inventory management (e.g., "Just In Time", "Economic Order Quantity") |
| Usability | Standardization, ask users, participatory design |
| Design for manufacturability | Concurrent engineering |
| Simultaneity constraints | Scheduling, synchronization |
| Task / subtask | Goal selection, task decomposition |
Simultaneity constraints Scheduling, synchronization
Table 7-2: Examples of common dependencies between
activities and alternative coordination processes for managing
them. Indentations in the left column indicate more specialized
versions of general dependency types (From [Malone94]).
The Process Handbook relies on a representation of business processes
that distinguishes between activities and dependencies and supports
entity specialization. It builds repositories of alternative ways
of performing specific business functions, represented at various
levels of abstraction. The handbook is intended to function as
an organizational-CAD tool and helps (a) redesign existing
organizational processes, (b) invent new organizational processes
that take advantage of information technology, and perhaps (c)
automatically generate software to support organizational processes.
SYNOPSIS has borrowed the ideas of separating activities from
dependencies and the notion of entity specialization from the
Process Handbook. While the Process Handbook project is currently
focusing on building a robust and scalable repository of semi-formal
descriptions of general business processes, our work focuses on
a more narrow domain, software applications, and is especially
concerned with (1) refining the process representation so that
it can describe applications, coordination processes, and components
at a level precise enough for code generation to take place, and
(2) populating repositories of dependencies and coordination processes
for the specialized domain of software component integration.
7.3 Other Approaches for Component
Software Development
7.3.1 Module Interconnection Languages
Module Interconnection Languages (MILs) and Interface
Definition Languages (IDLs) are an early attempt to provide
specialized notations for assisting the structuring of a large
collection of modules to form a software system. Representative
examples of early language designs include MIL75 [DeRemer75],
Intercol [Tichy79] and LIL [Gogouen86]. More recent examples include
Stile [Stovsky88] and Conic [Magee89].
MILs provide notations for describing:
A key issue in the design of a MIL is the nature of that glue.
In early languages, the predominant form of composition was based
on definition/use bindings. In this model, each module
defines or provides a set of facilities that are
available to other modules, and uses or requires facilities
provided by other modules. The purpose of the glue is to resolve
the definition/use relationships by indicating for each use of
a facility where its corresponding definition is provided. MILs
based on definition/use bindings were intended for use in large
but homogeneous systems, where coordination among system components
took place using primitive language facilities, such as procedure
calls. They focused on the description of components and left
the architectural relationships of those components with the rest
of the system implicit and often difficult to identify.
In our system, CDL, the notation used in SYNOPSIS to define components
and their interfaces (see Section 3.3.1.2), is closely related
to the early MILs.
As technology advanced to distributed and heterogeneous systems,
simple procedure call bindings were no longer adequate for describing
and implementing the range of possible interactions among software
components. When attempting to bind modules written in different
languages or residing in different systems, a number of new issues
(mismatches in data types, communication protocols, etc.) must
be addressed by more complex interaction mechanisms. More recent
MILs, such as Conic and Stile reflected this situation by providing
port-based module interface description languages. Module interaction
in those languages no longer relies on procedure call interfaces
but rather on a small set of message-passing primitives, which
require special run-time support.
Allen [Allen94] and Shaw [Shaw94a, Shaw94b] have
made eloquent
expositions of the shortcomings of MILs for capturing architectural
designs and argued for developing architectural languages with
support for complex interconnection patterns. SYNOPSIS is one
such language, providing the abstractions of dependencies and
coordination processes, which enable designers to express arbitrarily
complex interconnection needs and interaction protocols respectively.
The relatively small role that component descriptions play in
the total SYNOPSIS description of an application, provides another
proof of the limited expressive capabilities of MILs.
7.3.2 Open Software Architectures
Computer hardware has successfully moved away from monolithic,
proprietary designs, towards open architectures that enable
components produced by a variety of vendors to be combined in
the same computer system. Open architectures are based on the
development of successful bus and interconnection protocol standards.
A number of research and commercial projects are currently attempting
to create the equivalent of open architectures for software components.
Different researchers use different names to characterize their
projects, including software bus architectures, object broker
architectures, coordination languages, or application frameworks.
However, all these approaches are based on standardizing some
part of the glue required to compose components. This section
gives an overview of some notable efforts in these areas, and
contrasts them with the approach taken by our system.
Software bus architectures
Several researchers have attempted to facilitate the interconnection
of mixed-language software components by delegating all interfacing
and coordination decisions to an abstract decoupling agent, commonly
referred to as a software bus. Software buses typically
offer a "bus interface" to bus clients, implemented
as a set of standardized calls that clients use to get specific
services from the bus. Common bus "services" include
data and control transportation, interface adaptation, and data
type conversions. Heterogeneity in languages and architectures
is accommodated since program units are prepared to interface
directly to the bus and not to other program units. Some notable
efforts in this area include Polylith [Purtilo94] and Bart [Beach92].
Object-oriented approaches
Recent object-oriented component software architecture standards,
such as CORBA [OMG91], Microsoft's OLE [Microsoft94], and Apple's
Open Scripting Architecture [Apple93, Apple94] are all essentially
software bus approaches, because they rely on the existence of
an intermediary agent or broker, through which components
interact with one another using standardized interfaces (see [Adler95]
for an overview and comparison of the various approaches).
Coordination languages
A variation on the theme of software buses are coordination
languages, that is, sets of capabilities for interfacing and
coordinating software components that can be embedded inside other
programming languages [Lucco90, Gelernter92]. The best known coordination
language is Linda [Carriero89]. Linda provides a small set of
language-independent primitives for thread creation and communication
based on a blackboard-like (associative shared memory) data structure
called tuple space. It relies on special run-time support
to implement the tuple space abstraction on top of the physical
machine configuration.
Application Frameworks
Application frameworks are guidelines for developing components
that can be used together. They typically consist of an application
programming interface (API), that is, a toolkit of standardized
calls that offer intercomponent services, and a set of protocols
that guide the way these calls should be used from inside components.
The most successful application frameworks are user interface
toolkits, such as X-Windows [Scheifler88] and Motif [OSF90], operating
system APIs, such as Microsoft Windows API and the Macintosh Toolbox,
and rapid application development architectures, such as Microsoft
Visual Basic [Microsoft93].
Discussion
Successful software bus approaches can enable independently developed
applications to interoperate without the need to write additional
coordination code. However, they have a number of drawbacks. First,
they can only be used in environments for which versions of the
software bus have been developed. For example, OLE can only be
used to interconnect components running under Microsoft Windows.
Second, they can only be used to interconnect components explicitly
written for those architectures.
In contrast, integrating a set of components using SYNTHESIS typically
does require the generation of additional coordination
code, although most of that code is generated semi-automatically.
Components in SYNOPSIS architectures need not adhere to any standard
and can have arbitrary interfaces. Provided that the right coordination
process exists in its repository, SYNTHESIS will be able to interconnect
them. Open software architecture protocols can be incorporated
into SYNTHESIS repositories as special cases of coordination processes.
The previous two sections described approaches for facilitating
code-level component reuse. However, several researchers are also
exploring reuse at a more abstract, architectural level. Their
efforts focus on reusing abstract algorithms and data structures
rather than reusing source code. They center around repositories
of abstract notations, often called software schemas, that
represent solutions to commonly occurring software problems, and
can be instantiated or specialized to produce source code.
In the software schema approach, the algorithms and data structures
captured by the schemas are reusable artifacts. The abstraction
specification for the schema is a formal exposition of the
algorithm or data structure, whereas the abstraction realization
corresponds to the source code produced when the schema is instantiated.
The fixed part of the abstraction specification formally
describes the invariant computation or data structure of the schema
(for example, sorting with respect to an unspecified partial ordering
or a queue of an unspecified element type). The variable part
of the abstraction specification describes the range of options
over which a schema can be instantiated, such as the element type
and overflow length of a queue.
Examples of software schema approaches include PARIS [Katz89]
and the Programmer's Apprentice [Rich90]. The Programmer's Apprentice
provides a notation called the Plan Calculus for describing software
schemas. A flowchart representation is used to describe algorithmic
aspects of a schema, such as control flow and data flow. Flowcharts
can be annotated with logical preconditions and postconditions
to capture the declarative aspects of the schemas. Empty boxes
within a flowchart represent the variable part of the schema abstraction.
Software developers instantiate such a schema by filling in the
empty boxes with nested schemas.
SYNTHESIS has a number of features in common with the Programmer's
Apprentice system. Both systems support a repository of design
entities (activities, dependencies, and coordination processes
in SYNTHESIS and plans in PA). Just like plans, SYNTHESIS design
entities might be executable or generic. In that sense, SYNTHESIS
supports both code-level and design-level reuse. Entities decompose
into patterns of simpler entities, which can be successively specialized,
in order to move from a generic design to an executable implementation.
On the other hand, the two systems support different levels of
software design. The Programmer's Apprentice was developed in
order to support algorithm and data structure selection and design.
Its Plan Calculus notation provides abstractions for supporting
conditionals, iterations, and recursion. It does not provide support
for complex interconnection protocols and assumes that schema
interconnection will take place using primitive language mechanisms,
such as procedure calls. SYNTHESIS, in contrast, is designed to
facilitate the interconnection of black-box-like components into
larger application. It does not yet provide very strong support
for expressing elaborate control and iteration structures. It
focuses on providing rich abstractions and protocols for component
interconnection.
7.3.4 Reusability through Program Transformation
Heterogeneous systems consist of software components written in
different languages, using different architectural conventions.
Some researchers have pursued transformational approaches for
making them work together. That is, instead of writing additional
glue code that bridges mismatches between components, they have
explored techniques for transforming all components to a common
language, or a common architecture.
The TAMPR program transformation system [Boyle84] is an example
of this approach. TAMPR is able to translate programs from LISP
to Fortran, for reusability in Fortran environments, but also,
for improved performance.
Today's operating systems offer rich support for communication
and interaction between applications written in different languages.
Therefore, program transformation is no longer necessary in order
to combine components written in different languages. Section
6.2 has demonstrated how SYNTHESIS can insert appropriate coordination
processes around components that, not only resolve differences
in programming languages, but also differences in provided and
expected procedure names and parameter data types.
On the other hand, Sections 6.3 and 6.4 have demonstrated that
the addition of coordination code around components has certain
limits when the components have strong built-in interaction assumptions
that are incompatible with their intended use in a new system.
For example, a component designed as a filter cannot operate well
in an interactive environment, no matter how much coordination
code is inserted around it. In those cases, manual transformation
of component code has to take place. There is no system yet that
attempts to identify and automate the transformation of interaction
assumptions embedded inside a component's code (other than
those directly encoded in a component's interface), but
this is an intriguing area for future research.
7.4.1 Theory of Operating, Concurrent,
and Distributed Systems
Operating system research is concerned with developing algorithms
for the allocation and protection of system resources and the
management of communication and synchronization among system processes.
The study of concurrent and distributed systems is concerned with
essentially the same problems in the special domains of systems
with multiple processors or physically distributed components
[Andrews91, Bacon93].
Our work provides a unifying framework for organizing the techniques
and algorithms developed in those areas, relates them to dependency
patterns, and uses them to populate the design space of coordination
processes for software systems.
It also encourages a different approach in designing and interconnecting
complex systems: Instead of starting with the available communication
and synchronization mechanisms of the underlying operating systems
and trying to fit the application to them, designers are encouraged
to think about the interconnection needs of their systems (in
terms of dependency patterns) independently of how these needs
will eventually be managed. The repository of coordination processes
then assists designers to find a solution which is compatible,
both with the underlying interaction needs, and with the available
support mechanisms in the target environment. Sometimes this process
can suggest solutions which are more effective than those provided
by the operating system (like, for example, packaging components
in the same executable program and using built-in language coordination
mechanisms).
The term Computer-Aided Software Engineering (CASE) covers
a wide spectrum of automated tools that support various phases
of software design and development. This section will attempt
to position our work in the world of CASE tools, by identifying
the phases of software design and development that it is able
to assist.
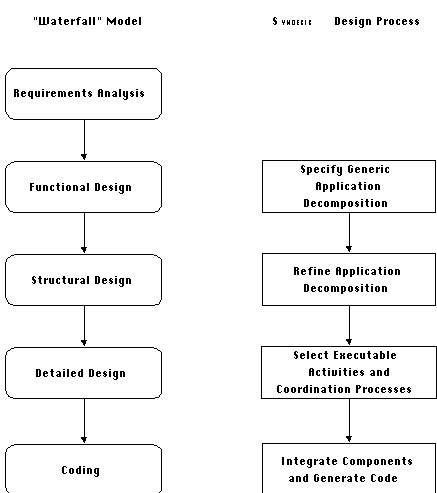
Figure 7-1 shows a simplified version of the classic "waterfall"
model of software development [Boehm81], excluding the phases
involving software testing, installation and maintenance. This
model is not a realistic representation of the actual process
of developing software. Most notably, it hides the fact that the
designers need to revise their designs and thus iterate through
its phases. Nevertheless, it still serves to identify the major
phases in the design and development of a software system. These
phases are briefly explained in Table 7-3.
Figure 7-1 also shows where SYNTHESIS fits with respect to the
waterfall model. As can be seen, it has the potential of assisting
all phases of software development, except the initial requirements
analysis.
SYNOPSIS can be used to sketch a decomposition of a system into
generic activities, which can then be specialized and refined
as more insight about the system is gained. SYNTHESIS can store
repositories of alternative domain-specific architectures that
can further assist designers both in specifying and in refining
the functional decomposition of their systems.
Once designers have finalized the decomposition of an application
into patterns of activities and dependencies, SYNTHESIS can assist
them to select executable implementations for atomic activities,
and coordination processes for managing dependencies through the
process we described in Chapter 5.
Figure 7-1: Waterfall model of software development
and corresponding stages of application development using SYNTHESIS.
| Requirements analysis | Identification of the application(s) to be supported and the user community to be served. Important characteristics to be determined may include the sophistication of the users, level of user-machine interaction desired, performance constraints, etc. |
| Functional design | Identification of the major functions and goals the system has to meet |
| Structural design | Refinement of system functions and division into modules |
| Detailed design | Selection of major algorithms and data structures within each module, selection of communication and synchronization protocols between modules |
| Coding | Implementation of modules. Integration of modules into an executable system |
Finally, when detailed design is complete, SYNTHESIS can automatically
generate coordination code, package existing components into procedures
and executables, and produce the final executable system.