4.6 Special Cases of Flow Dependencies
This section will demonstrate how the generic flow coordination
model of the previous section can be specialized and form the
basis for a large number of different practical mechanisms for
managing flow dependencies.
We distinguish flow dependencies according to the kind of resource
that flows. For each kind of resource, we begin by discussing
how the components of the model of the previous section specialize
to handle issues specific to that kind of resource. Just as we
did in the previous section, we then show how a design space for
the total dependency can be defined by combining the components
of the model. We conclude each section with a number of concrete
example coordination processes, showing how they can be derived
from the generic coordination model.
Control flows specify relationships of the resource type commonly
referred to in Computer Science as control. From a resource
perspective, control is more accurately described as a thread
of processor attention. Therefore, control flows specify how
threads of processor attention must flow from one set of activities
to another.
Every software activity needs to receive control from somewhere
in order to begin execution. In SYNOPSIS descriptions, control
flows into the Begin port of an activity, causing it to begin
execution. It flows out of its End port after it has completed
execution (see Section 3.3.3). From a resource perspective, each
activity consumes a thread of control in order to begin execution,
and produces a new thread of control upon completion.
Control flow dependencies do not generally appear at the top-level
of software architecture descriptions. They are either left implicit,
in which case they are automatically added and managed by the
SYNTHESIS system (see Section 5.2.4), or they are introduced during
the management of timing dependencies, such as prerequisites (Section
4.5.3.2). Since prerequisite dependencies are part of every flow
dependency, control flow dependencies end up occurring in coordination
processes of almost every dependency.
4.6.1.1 Specialization of the generic
process
The following table summarizes the most important differences
in the management of control flows from the generic case.
|
|
a. Usability.
Control corresponds to a thread of processor attention in a given
run-time environment. Consumption of control by a software activity
corresponds to enactment of that activity in the respective run-time
environment. For a software activity to properly use control,
it must be compatible with its run-time environment.
This dependency is generally managed at design-time, by properly
packaging, compiling or configuring activities for their intended
run-time environments. If activities are already in executable
form, they must be placed in compatible execution environments
and control must be transported to those environments (possibly
by the use of remote calls).
In some cases, limited run-time configuration is also possible,
usually by setting environment variables before passing control
to the activity. For example, an environment variable can be set
before passing control to a numerical analysis program to specify
whether a math co-processor exists in the run-time system or not.
b. Accessibility.
Accessibility dependencies specify the fact that a software activity
must be accessible to a processor in order to receive control
from it (be enacted by it). For software activities, accessibility
implies accessibility of the program text.
The generic accessibility coordination alternatives presented
in Section 4.5.2.1 apply here as well. As in the generic case,
placing resource producers and users close together at design
time, reduces the effort of actually transporting control between
them.
Transport control from producer to users
Transportation of control relies in a number of low-level programming language and operating system mechanisms that are modeled in our framework as primitive
| Dependency Type | Generic Mechanism | Examples |
| one-to-one | any of the following mechanisms | |
| one-to-many | Sequentialization | |
| many-to-one | Asynchronous Call
Synchronous Call Scheduling | - UNIX fork
- Multilisp future - Procedure call
- RPC - UNIX cron |
| many-to-many | Broadcasting | - ISIS Multicast [Birman89] |
Some operating systems support variations of Seq that ease the
above restrictions. For example, UNIX supports the exec system
call, using which control can be passed (without return) to a
different executable program.
In its most general form, Seq can manage a one-to-many control
flow relationship. The semantics of a one-to-many Seq is that
the follower activities are placed after the source activity in
the same sequential code block. Ordering among the follower activities
is left unspecified.
Asynchronous Call (Fork). This mechanism manages a many-to-one
control flow. It generates a new thread of control and enables
the enactment of an activity from a variety of other activities.
There is a rich variety of such mechanisms that enable asynchronous
creation of new local or remote threads, based on the same or
on different executable programs. Figure 4-18 shows some variations
of Fork supported by different systems.
c. Prerequisite
Prerequisite dependencies specify the requirement that a resource
is produced before it can be used. Since an activity cannot start
before a thread of control has been generated and passed to it,
in the special case of control flows this requirement is always
automatically managed.
d. Sharing.
- Nonconcurrent. This is a corollary of the consumability
property.
- Indivisible. A thread of control cannot be divided into
more than one activities. However, new threads of control can
easily be generated to handle additional activities.
Sharing of control flow arises in one-to-many dependencies. The
consumability of control implies that each thread of control can
only be used by a single activity. In order to manage one-to-many
dependencies, control replication, that is, explicit generation
of new control threads must take place for each user.
4.6.1.2 Managing control flow dependencies
In the special case of control flows, the only flow design dimensions
(see Figure 4-17) that matter are the number of activities at
each side of the flow and (for many-to-one flows) any user sharing
restrictions.
a. One-to-one flows
One-to-one control flows can be managed by specializing any of
the built-in one-to-many, many-to-one, and many-to-many primitive
mechanisms presented in the previous section. The particular form
and location of the two interdependent components will determine
which mechanisms are applicable.
b. One-to-many flows
One-to-many control flows can be managed
c. Many-to-one flows
Many-to-one control flows are usually managed by variants of the
call mechanism (asynchronous and synchronous). Additional user
sharing coordination might be required to handle special situations,
such as non-reentrant control recipients or race conditions.
d. Many-to-many flows
Depending on their exact semantics, many-to-many control flows
are managed by many-to-many primitive mechanisms, or by decomposing
them into simpler patterns of control flow
________________________________________________________________________
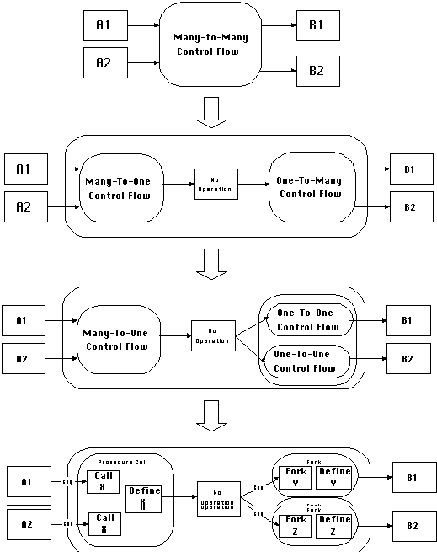
Example 6-1: Managing an each-to-all control flow.
We are interesting in managing a many-to-many control flow dependency
in a system that does not support broadcast primitives. One approach
is to decompose the flow into an equivalent pattern of simpler
control flows. Many-to-one flows can be managed by a local procedure
call, while one-to-many calls can be further decomposed into one-to-one
calls. Finally, one-to-one flows can be managed by a variety of
methods, such as asynchronous calls (Fork). Figure 4-19 shows
the successive transformations and resulting code fragments.
|
Thread of activity A1:
... A1 call X
... Thread of activity A2: ... A2 call X
... procedure X
end procedure |
Figure 4-19: Managing a many-to-many control flow
by decomposition into simpler dependencies.
________________________________________________________________________
Data flows specify relationships between producers and users of
data values. In data flows, producer ports decompose to data out
ports, while consumer ports decompose to data in ports.
4.6.2.1 Specialization of the generic
model
The following table summarizes the most important differences
in the management of data flows from the generic case.
|
|
a. Usability
Figure 4-20: Generic process for managing usability in data flows.
Usability dependencies specify that resource users should be able
to properly use produced resources. For data resources, this usually
translates to data type and format compatibility issues.
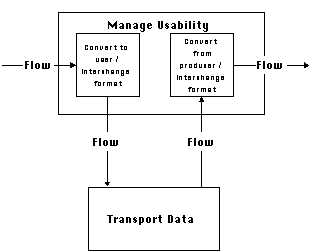
The most generic process for managing data usability dependencies
is shown in Figure 4-20. It can be specialized to cover all five
alternatives outlined in Section 4.5.1. Although its generic form
is simple, its implementation depends on the development of a
sufficiently rich family of data type and format conversion activities.
For simple data resources, such conversions are usually straightforward.
b. Accessibility
The generic accessibility coordination alternatives presented
in Section 4.5.2.1 apply here as well. As in the generic case,
placing resource producers and users close together at design
time, reduces the effort of actually transporting data resources
between them.
Transport data from producer to users
There are two broad alternatives here:
a. Manage at design-time
This mechanism is applicable for transporting preexisting, constant
data resources among activities. Each activity simply receives
a local copy of the constant at design-time and no coordination
takes place at run-time.
b. Use carrier resource at run-time
This is the most frequently used method for transporting data.
A repository or carrier resource, accessible to
both producers and users, is created. Producers write the data
to the shared carrier. Users read the data from the shared carrier.
A prerequisite dependency specifies the requirement that carrier
resources can be read only after they have been written (Figure
4-21).
Examples of carrier resources are local variables, global variables,
shared memory, files, pipes, network channels, tuple space, etc.
Note that this process creates a distinction between the original
data resource that is being transported and the carrier resource
that transports it. For example, in a string transport process
using shared files, it distinguishes between a string resource
that is being produced and consumed, and the file resource that
transports it from producers to users.
The introduction of a new resource into the system results in
the introduction of an additional resource dependency. In contrast
to simple data flow dependencies, where data itself is being transported
from producers to users, the new resource dependency communicates
a resource identifier from producers to users. It is an instance
of a named resource dependency, that will be described
in the next section.
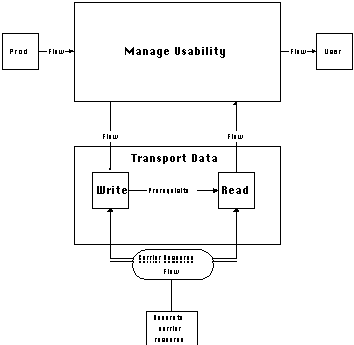
Figure 4-21: Data transportation using a carrier
resource.
Carrier resources are classified and selected according to the
following two dimensions:
i. Sharing properties
Carrier resources are being shared among all writers and readers
of a transported data resource. In addition, since the default
semantics of data flow imply the flow of a stream of data
values over the lifetime of an application (see Section 4.5),
carrier resources are also shared among different write-read transactions
which might be concurrently in progress. Carrier resources selected
to manage a particular dependency must thus be able to support
the corresponding pattern of resource sharing. Using the resource-in-use
framework of Section 4.4.4, we can connect carrier resource sharing
properties to their usability in specific data flow dependency
patterns:
ii. Dependence on run-time location of endpoints (Endpoint
location dependence)
Some carrier resources can be generated independently of the run-time
location of their users. An example are files in a universally
shared file system. Their pathname is universally recognized and
therefore can be chosen independently of where the user activities
are located at run-time. Other carrier resources are dependent
on the run-time location of their endpoints. Example of the latter
class are private network channels set up between two dynamically
specified endpoints.
From a coordination process perspective, the latter class of resources
requires additional flows from the users to the carrier producer
activity. The flows must communicate information about the location
of user processes. This requirement might complicate the management
of the flow process.
The following table applies the above framework to a number of
frequently used carrier resources.
| Carrier resource | Divisible | Consumable | Concurrent | Endpoint location dependent |
| Local variable | No | No | Yes | No |
| Shared memory | Yes | No | Yes | No |
| Pipe | Yes | Yes | No | No |
| File | Depends | No | Depends | No |
| Socket | Yes | Yes | No | Yes |
| Tuple space | Yes | No | Yes | No |
c. Prerequisite
The prerequisite requirement of generic flow dependencies is replaced
by a prerequisite between the write and read activities of the
data transport process (Figure 4-21). In accordance with the generic
flow model, that prerequisite determines the type of flow. As
described in the previous section, carrier resources must be able
to support the write-read access patterns specified by the chosen
prerequisite. For example, a cumulative prerequisite would define
a cumulative flow, that is, a flow where more than one unread
data items might coexist at any given time. This would require
the selection of a divisible carrier resource, such as a buffered
queue.
The alternative prerequisite types and coordination processes
discussed in Section 4.5.3 apply here as well.
Simultaneous management of Transport and Prerequisite
Programming languages and operating systems support a number of
built-in mechanisms that simultaneously manage data transport
and prerequisite dependencies. Therefore, an important design
choice when managing data flow dependencies is whether prerequisite
and data transport requirements will be jointly or separately
managed.
Most mechanisms are closely related to the primitive control flow
transport mechanisms described in Section 4.6.1.2. They are summarized
in Figure 4-22.
| Dependency Type | Generic Mechanism | Examples |
| one-to-one |
| - OCCAM channels [Inmos84]
- UNIX sockets - UNIX pipes |
| one-to-many | -ISIS Multicast [Birman89] | |
| many-to-one |
| - ABCL/1 async message passing
- Procedure calls - RPC - MS Windows DDE |
| many-to-many | - ISIS Multicast [Birman89] |
We observe that there is an asymmetry between support for many-to-one
and one-to-many relationships. While most languages and systems
support a variation of procedure call (manages many-to-one relationships),
very few systems provide primitive support for one-to-many relationships.
As a consequence, while most many-to-one data flows are managed
using eager flows (control flows from producer to user), most
one-to-many relationships are managed, either using lazy flows
(control flows from user to producer and back), or by loose peer
organizations, where synchronization takes place using shared
events.
d. Sharing
Data flow dependencies assume that all users are independent.
Abstract data is inherently nonconsumable and concurrently sharable.
However, the sharing properties of the carrier resource might
limit the consumability or concurrency of the entire flow. Apart
from this observation, the generic design dimensions and design
alternatives of sharing dependencies presented in Section 4.5.4
apply to data flows as well.
4.6.2.2 Managing data flow dependencies
The distinctive feature of managing data flow dependencies relative
to the generic case lies in the management of the data transport
process. The main choice here is whether a primitive joint coordination
mechanism for prerequisite and transport will be used, or whether
the two dependencies will be managed separately. In the latter
case, the two main design dimensions involve the selection of
the carrier resource type and the process for managing the prerequisite.
a. One-to-one flows
One-to-one flows can be managed by using one-to-one primitive
data flow mechanisms (such as pipes or point-to-point channels)
or by specializing any of the coordination processes for managing
one-to-many, many-to-one, or many-to-many flows.
b. One-to-many flows
There are few built-in primitive mechanisms for direct management
of one-to-many data flows. There are three broad alternative design
paths:
c. Many-to-one flows
Many-to-one data flow dependencies are most naturally implemented
using the procedure call mechanism (and variants thereof).
d. Many-to-many flows
The implementation of many-to-many flows varies depending on their
particular type.
________________________________________________________________________
Example 6-2: Managing a one-to-many flow with a race condition
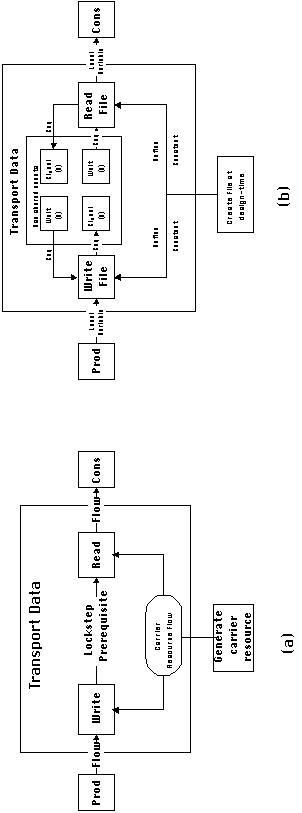
We would like to design a coordination process for managing a
one-to-one-of-many dependency, that is, a dependency where a stream
of data flows from a single producer to multiple potential user
activities. However, each data value can only be read by one user.
First, we have to determine the type of dependency that expresses
our constraint. It is easy to see that a one-to-many lockstep
flow dependency specifies the desirable coordination properties.
Assuming there are no usability considerations, the generic decomposition
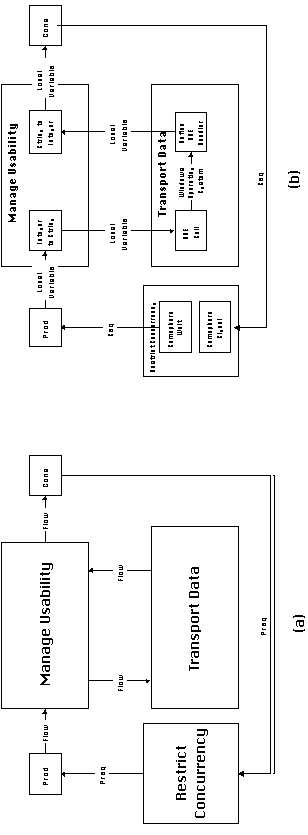
of a coordination process for managing this type of dependency
is shown in Figure 4-23(a). The two main parameters in this model
are the choice of a carrier resource, and the mechanism for managing
the prerequisite. We choose a file as a carrier resource. The
filename is selected at design-time and made known, through constant
definitions, to all interested parties. We also choose a peer
organization for managing the lockstep prerequisite, based on
two semaphores (see Figure 4-11). Semaphore A notifies users whenever
a new data value has been produced. Semaphore B notifies producers
whenever a data value has been used (Figure 4-23(b)). The resulting
program fragments at the producer and user threads would look
as follows:
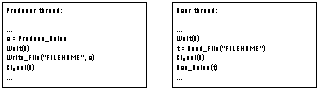
________________________________________________________________________
Example 6-3: Managing a many-to-one data flow with a non-reentrant
user
We would like to design a coordination process for managing a
dependency in which several activities will be sending integer
data to a user activity. The user activity is non-reentrant, that
is, at most one instance of the user can be executing at any one
time.
The user limitations require the use of user sharing coordination
that will restrict the concurrency of user invocations. One way
of restricting user invocations is by restricting the concurrent
production of data (see Section 4.5.4.2). This gives rise to the
generic coordination process model of Figure 4-24(a). We have
chosen to manage the many-to-one data transport dependency using
a Microsoft Windows synchronous call mechanism called Dynamic
Data Exchange (DDE). DDE can only be used to transport string
data. Therefore, conversion of integers to and from string format
is also required. The concurrency restriction (mutual exclusion)
part is managed using a semaphore protocol. The resulting code
fragments at the producer and user threads would look as follows:

________________________________________________________________________
Control and data are examples of direct access resources, that
is, resources that are communicated directly from producer to
user activities. More complex resource types, such as system or
hardware resources, are communicated using a secondary data resource
called the resource name or identifier. We refer
collectively to such resource flows as named resource flows.
Identifiers allow resources of arbitrary complexity to be accessed
through software component interfaces, which typically only support
the exchange of relatively simple data values.
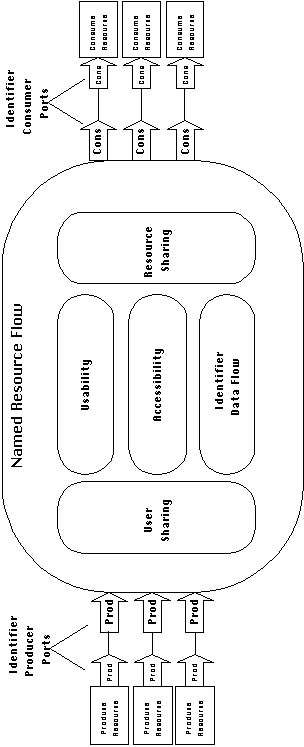
Figure 4-25 shows the generic form of a named resource flow process.
The principal difference of this diagram from the generic process
of Figure 4-4 is that the prerequisite dependency of the original
diagram has been replaced with an identifier data flow dependency
(which, of course, contains a prerequisite). This reflects the
fact that, what is actually flowing (i.e. is being exchanged through
component interfaces) in such cases is not the resource itself,
but its identifier. The general discussion of design dimensions
and coordination alternatives of Section 4.5 applies to identifier
flows, as well as to the remaining three dependencies of Figure
4-25.
________________________________________________________________________
Example 6-4: Coordinating the use of a garbage collectible
memory heap
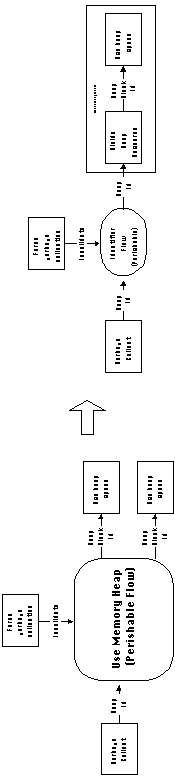
Figure 4-26: The use of a memory heap with periodic
garbage collections can be modeled and coordinated using named
flow dependencies.
Figure 4-26 shows how the use of a memory heap resource can be
coordinated using named flows. In this diagram, a garbage collection
process "generates" a new heap resource every time it
is called. This resource is then shared among a number of user
programs. Periodically, an independent agent forces the system
to perform garbage collection, and thus "create" a new
heap resource. The situation is naturally described using a perishable
flow dependency (see Figure 4-8).
Assuming the heap is accessible to all users, the two issues that
have to be resolved in order to manage this dependency are:
a. Sharing the heap. Memory heaps are divisible resources
(see Figure 4-15). Therefore, the sharing process simply uses
the global heap id, reserves a private block, and produces the
identifier of that block.
b. Managing the heap identifier flow. The heap identifier
flow is a perishable data flow: Each heap id can be used an arbitrary
number of times until it is invalidated. Then, a new heap id must
be generated (by the garbage collector) before further use can
occur. Managing the perishable data flow in requires (see Section
4.6.2.2):
- selecting a carrier resource
- managing a perishable prerequisite
In this case, we store heap identifiers in a global variable,
accessible to all users. We manage the prerequisite using a customer
pull organization: A separate marker is used to determine whether
the current heap id is valid or not. Activity Force Garbage Collection
invalidates that marker. Before each access, each heap user checks
the marker to see if the heap id is valid. If it is not, it invokes
the garbage collector and sets the marker to true.
The resulting code fragments that implement the above pattern
of coordination are as follows:
|
Heap User Thread: ... if not(heap_id_valid) then
heap_id = Garbage_Collection
end if block_id = Divide_Heap(heap_id)
Use_Heap(block_id)
... |
Force Garbage Collection thread: ... Force_Garbage_Collection heap_id_valid = False
... |
________________________________________________________________________
4.6.4 Existing Resource Dependencies
Previous sections have described flow patterns involving resources
that are dynamically produced during run-time. Flow dependencies
can be specialized to also handle preexisting resources, such
as constant values, hardware devices, and files created outside
the scope of the system. Such dependency patterns follow the general
form of Figure 4_25, with the exception that producer ports are
now connected to resource entities (Section 3.3.4), describing
the preexisting resources, rather than activities.
Existing resource dependencies have the following main differences
from generic flows:
As a consequence, the typical preexisting resource dependency
only needs to manage usability and sharing among users. The general
discussion and design alternatives presented in Sections 4.5.1
and 4.5.4 respectively, apply here as well.
_______________________________________________________________________
Example 6-5: Sharing a printer

Figure 4-27: Sharing a printer can be modeled
and coordinated as a special case of flow dependency.
In this example, we are interested in modeling and coordinating
the sharing of a printer resource among a set of user activities.
Printers are accessed by users through a device name, which is
constant and known at design-time. Therefore, no run-time coordination
is required for communicating the resource name. Furthermore we
assume that, in this particular application, there are no usability
considerations, Therefore, the only component of the shared resource
dependency that requires run-time coordination is the sharing
component. Printers cannot interleave the printing of multiple
files. Assuming there is no built-in support for spooling, printers
must be treated as nonconcurrent resources, and appropriate run-time
coordination that restricts concurrent printer access must be
introduced into the system.
________________________________________________________________________
Timing dependencies specify constraints on the relative timing
of two or more activities. The most widely used members of this
dependency family are prerequisite dependencies (A must
complete before B starts) and mutual exclusion dependencies
(A and B cannot overlap).
Timing dependencies are used in software systems for two purposes:
a. Specify implicit resource relationships
Implicit resource relationships arise in situations where parts
of a resource flow coordination protocol have been hard-coded
inside a set of components. Other parts of the protocol might
be missing, and explicit coordination might be needed to manage
the missing parts only. One example is a set of components for
accessing a database. Each of the components contains all the
functionality needed in order to access the database built into
its code. The name of the database is also embedded in the components
and does not appear in their interface. However, none of the components
contains any support for sharing the database with other activities.
In applications that require concurrent access of the database
by all components, designers need to specify and manage an external
mutual exclusion dependency among the components.
b. Specify cooperation relationships
Flow dependencies assume that different users of a resource are
independent from one another. In many applications, however, users
of a resource are cooperating in application-specific ways. Section
4.2 describes an example of such patterns of cooperation. In those
cases, designers must specify additional dependencies that describe
the cooperation among the users. Some of those dependencies could
be other resource dependencies. Other could be timing dependencies.
In order to derive a useful family of timing dependencies we have
used the following approach, based on Allen's taxonomy of time
interval relationships [Allen84].
| Relation | Symmetric Relation | Pictorial Example |
| X before Y | XXX YYY | |
| X equal Y | XXX
YYY | |
| X meets Y | XXXYYY | |
| X overlaps Y | XXX
| |
| X during Y | X equal Y | YYYYYY
|
| X starts Y | X, Y simstart | XXX
YYYYY |
| X finishes Y | X,Y simend | XXX
|
In his seminal paper, Allen has enumerated all possible relationships
between two time intervals (Table 4-1). An occurrence of a software
activity can be represented by a time interval: [Begin_time,
End_time]. Timing dependencies express constraints among activity
occurrences. These constraints can be expressed by equivalent
constraints between time intervals. Constraints can either require
or forbid that a given time interval relationship holds.
By enumerating "required" and "forbidden"
constraints for each of Allen's time interval relationships, we
get a list of potentially interesting elementary timing dependencies
(Table 4-2). These dependencies can be combined to define additional,
composite timing relationships. Finally, the resulting set of
dependencies can be organized in a specialization hierarchy, as
shown in Figure 4-28.
| Allen's Relation | Comments | ||
| X before Y | X prerequisite Y | X prevents Y | |
| X equal Y | Can be expressed as a composite pattern:
X,Y simstart AND X,Y simend | ||
| X meets Y | X meets Y | Special case of prerequisite | |
| X overlaps Y | X overlaps Y | X,Y mutex | |
| X during Y | X during Y | X,Y mutex | During can be expressed as a composite
pattern:
X overlaps Y AND Y finishes X |
| X starts Y | X starts Y | ||
| X,Y simstart | X,Y simstart |
X finishes Y X finishes Y
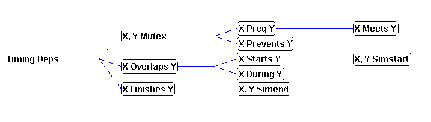
The following paragraphs describe each of the dependencies shown
in Figure 4-28. For each dependency type, we describe:
4.7.1 Mutual Exclusion Dependencies
(X, Y Mutex)
| Description: | Mutual exclusion dependencies among a set of activities limit the total number of activities of the set that can be executing at any one time. |
| Design Dimensions: | Degree of concurrency (maximum number of concurrently executing activities). |
| Coordination Processes: | See [Raynal86] |
| Typical Use: | Mutual exclusion dependencies typically arise among competing users who share resources with limited concurrency. |
4.7.2 Prerequisite Dependencies (X
Prereq Y)
| Description: | Prerequisite dependencies specify that an activity X must complete execution before another activity Y begins execution. |
| Design Dimensions: | See Section 4.5.3 |
| Coordination Processes: | See Section 4.5.3 |
| Typical Use: | Prerequisites arise in two general situations:
i. Between producers and consumers of some resource. A resource must be produced before it can be consumed. ii. As a special way of managing mutual exclusion dependencies. Mutual exclusion relationships can be managed by ensuring that the activities involved occur in a statically defined sequential order. The ordering can be specified by defining appropriate prerequisite relationships. |
4.7.3 Prevention Dependencies (X Prevents
Y)
| Description: | Prevention dependencies specify that the occurrence of an activity X prevents further occurrences of another activity Y. |
| Design Dimensions: | - In permanent prevention dependencies, an occurrence
of X
prevents all further occurrences of Y.
- In temporary prevention dependencies, occurrence of a third activity Z re-enables occurrences of Y. |
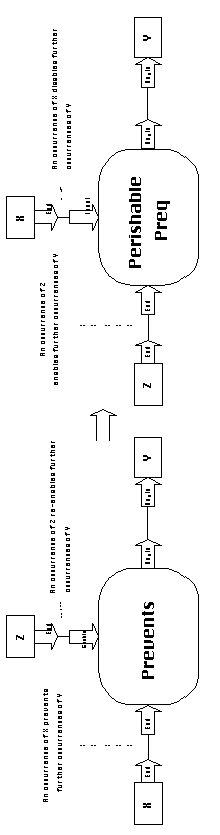
| Coordination Processes: | Prevention relationships are closely related to perishable prerequisites (see Section 4.5.3.1). As shown in Figure 4-29, every prevention dependency can be mapped to an equivalent perishable prerequisite. |
| Typical Use: | Prevention relationships often arise among competing activities that share some resource, where one of the competing activities (X) has higher priority, and thus the power to restrict access to (prevent) other competing activities (Y). |
4.7.4 Meets Dependencies (X Meets Y)
| Description: | Meets dependencies specify that an activity Y should begin execution after completion of another activity X |
| Design Dimensions: | Minimum or maximum delay between the completion of X and the initiation of Y. |
| Coordination Processes: | Most of the coordination processes for managing lockstep prerequisites can be used to manage this dependency. Delay parameters between X and Y can determine which alternatives are appropriate for each special case (For example, if Y must start immediately after X completes, direct transfer of control is usually preferable to loose event synchronization). |
| Typical Use: | Meets dependencies are a special case of prerequisite and can also be used to describe relationships between producers and users of resources. The explicit specification of maximum delay between the two activities is useful in situations where resources produced have finite lifetimes and must be used within a specified time interval. |
4.7.5 Overlap Dependencies (X Overlaps
Y)
| Description: | Overlap dependencies specify that an activity Y can only begin execution if another activity X is already executing. |
| Design Dimensions: | None |
| Coordination Processes: | This dependency can be managed in two different ways:
i. Proactively scheduling Y when X starts execution. This is equivalent to decomposing X overlaps Y to Y starts X with specified delay. ii. Waiting for X to begin execution before allowing Y to start. This is equivalent to defining a perishable prerequisite (enabled by initiation of X, invalidated by completion of X) between Y and X. |
| Typical Use: | Overlap relationships typically imply resource relationships between Y
and X. In
most cases, during its execution Y produces some resource or state required by X. Overlap dependencies occur most frequently as components of During dependencies. |
4.7.6 During Dependencies (X During
Y)
| Description: | During dependencies specify that an activity X can only execute during the execution of another activity Y. |
| Design Dimensions: | None |
| Coordination Processes: | This dependency is a composite pattern of the following two
dependencies: X Overlaps Y X can begin execution only if Y is already
executing
Y Finishes X Termination of Y also terminates X It can be managed by composing processes for managing its two component dependencies. |
| Typical Use: | During dependencies imply that X uses some resource or state generated during Y's execution. For example, a network client can only execute successfully during execution of the system's network driver. |
4.7.7 Starts Dependency (X Starts Y)
| Description: | Starts dependencies specify that an activity Y must start execution whenever X starts execution. |
| Design Dimensions: | Minimum or maximum delay between initiation of the two activities. |
| Coordination Processes: | Combinations of direct control flow and scheduling can be used to manage this dependency. |
| Typical Use: | This dependency is often used to describe application-specific patterns of cooperative resource usage or implicit resource dependencies. For example, when starting a word processor program, the printer driver is often initialized as well, in anticipation to the word processor's need for its services. |
4.7.8 Simultaneity Dependency (X,Y
simstart)
| Description: | Simultaneity dependencies specify that all activities in a set must start execution at the same time. |
| Design Dimensions: | Minimum and maximum tolerances between the actual time each activity in the specified set begins execution. |
| Coordination Processes: | Simultaneity dependencies can be transformed into many-to-many prerequisite dependencies and managed as such (see Figure 4-30). |
| Typical Use: | Simultaneity dependencies are most often used to describe patterns of cooperative resource or mutual resource dependencies. |
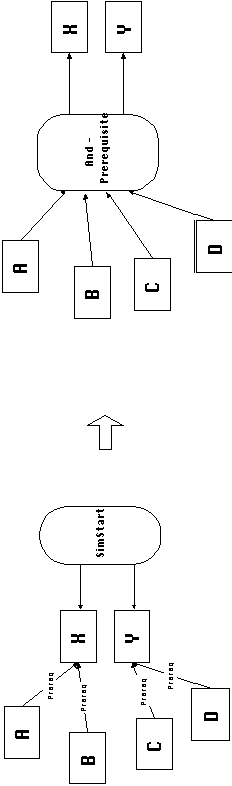
Figure 4-30: A simultaneity dependency can be
transformed and managed as a composite prerequisite: Before activities
X and Y can begin execution, all four prerequisite activities
must first occur. Then, both X and Y can occur together.
4.7.9 Finishes Dependency (X Finishes
Y)
| Description: | Finishes dependencies specify that completion of an activity X also causes activity Y to terminate execution. |
| Design Dimensions: | Minimum or maximum delay between completion of X and termination of Y. |
| Coordination Processes: | Termination of the process that executes Y using machine-specific system primitives. |
| Typical Use: | This dependency is most often used to specify application termination relationships (Figure 4-31). |
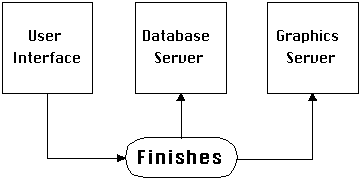
Figure 4-31: Termination of the user-interface
also requires termination of the database and graphics servers.
.
4.7.10 Simultaneous End Dependency
(X, Y Simend)
| Description: | Simultaneous end dependencies specify that all activities in a set must terminate if any of them completes execution. |
| Design Dimensions: | Minimum or maximum tolerances between the actual time each member of the specified set terminates. |
| Coordination Processes: | Centralized: Each activity in the set sends a signal to a
monitor
process upon termination. The monitor process terminates all other activities in the set. Decentralized: Terminating activities generate an event. All participant activities periodically check for that event and terminate themselves if they detect it. |
| Typical Use: | Speculative concurrency: Multiple worker activities are jointly or independently working on a problem. All of them terminate if at least one of them arrives at a solution. |
The approach we have used in most of this chapter is based on
decomposing complex relationships into sets of independent
simpler relationships, enumerating ways of managing each of
the simpler relationships, and combining the pieces to construct
coordination processes for the more complex relationships. This
has resulted in a taxonomy of elementary dependency types and
their respective coordination processes.
Although the definition of a vocabulary of simple dependencies,
that can be used and managed independently of one another is a
very desirable objective (see Section 4.1), throughout the chapter
we have observed that in several cases there exist joint
coordination processes for managing together more than one dependencies.
For example, replication is a process that jointly manages accessibility
and sharing issues in one-to-many flow dependencies, often more
efficiently than if the two issues had been managed separately.
It would be very useful to begin to classify such composite dependency
patterns, and the specialized joint coordination processes for
managing them. When encountering such patterns, designers will
have a choice between decomposing them into their components and
managing each component independently, or using a joint managing
process for the entire pattern,
SYNOPSIS provides full support for defining and storing composite
dependencies. Although a systematic classification of composite
dependencies lies beyond the scope of this thesis, the rest of
the section provides evidence of the usefulness of this task by
describing a few commonly occurring complex patterns of flow dependencies,
for which special joint coordination processes have been developed.

Pairs of flow dependencies in opposite directions can often be
efficiently managed by combining them into a single procedure
call. One of the flows can be managed by the flow of parameters
from caller to callee, while the opposite flow can be managed
by the flow of the return value from callee to caller. We call
such composite pairs of flow dependencies, exchange dependencies.
4.8.2 Multiple Unidirectional Flows
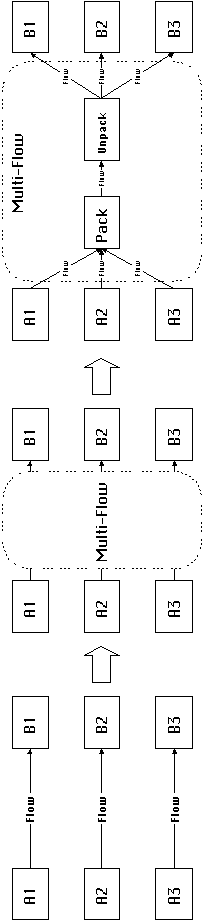
Sets of flow dependencies in the same direction can often be managed
very efficiently by collecting them together, packing them into
composite structures, and sending them using a single flow. At
the other end, they are unpacked and distributed to their users.
Such a technique is used when sets of small messages are collected
together into larger packets and sent through the network in one
shot.
4.8.3 Arbitrary Static Flow Patterns
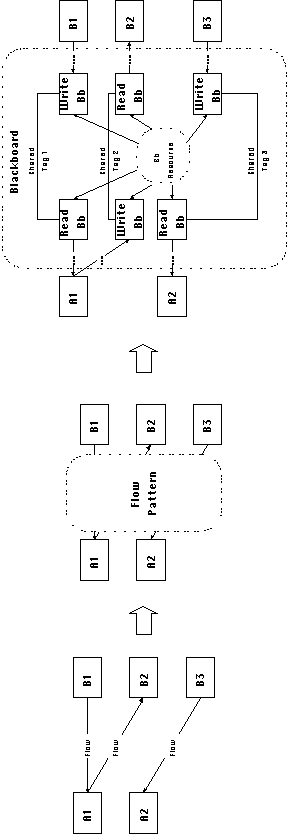
Arbitrary sets of flows can be managed together using a divisible,
associative access repository of information, often called a
blackboard. Data items are written and read from the blackboard
using associative tags. A single blackboard resource is able to
concurrently manage multiple flow transactions provided that each
transaction uses its own unique tag. The language Linda [Carriero89,
Gelernter92] is built around the blackboard model of flow management.
Linda calls its blackboard object tuple space.

Sets of flow dependencies that form a cycle, create the possibility
for deadlock conditions among the interdependent activities. For
that reason, we can define special composite coordination processes
that jointly manage sets of circular flows. Such coordination
processes, in addition to managing each flow will install additional
coordination that will prevent deadlock.
This chapter has introduced a vocabulary of dependency types for
describing software component interconnection relationships and
an associated design space of coordination processes for managing
each dependency type. Combined with the linguistic support of
SYNOPSIS, we are now well-armed in order to:
The piece of the puzzle that is still missing is how activities
and coordination processes can be integrated into executable applications.
Chapter 5 is devoted to a discussion of the issues involved, and
presents an algorithm that can automate the integration process.
Chapter 6 describes SYNTHESIS, a prototype implementation of a
software development tool based on the ideas described in this
thesis. It also discusses a number of experiments performed using
SYNTHESIS, in order to test the feasibility and usefulness of
our approach.