Chapter 4
Chapter 2 argued for separating the core functional pieces of
a software application from their interconnection relationships.
Last chapter introduced an architectural language that enables
this separation by providing separate abstractions for activities
and dependencies. This chapter goes one step further: It observes
that, when taken out of context, many interconnection problems
in software applications are related to a relatively narrow set
of concepts, such as resource flows, resource sharing, and timing
dependencies. These concepts are orthogonal to the problem
domain of most applications, and can therefore be captured in
an application-independent vocabulary of dependency types. Likewise,
the design of associated coordination processes involves a relatively
narrow set of coordination concepts, such as shared events,
invocation mechanisms, and communication protocols. Therefore,
it can also be captured in a design space that assists designers
in designing a coordination process that manages a given dependency
type, simply by selecting the value of a relatively small number
of design dimensions. The proposed vocabulary of dependencies
and design space of coordination processes, taken together, can
form the basis for a design handbook for integrating software
components. The development of such a handbook aims to reduce
the specification and implementation of software component interdependencies
to a routine design problem, capable of being assisted, or even
automated, by computer tools.
The purpose of this chapter is to give an answer to the following
two questions:
Why do software components interconnect with one another?
How do software components interconnect with one another?
We would like to organize the answers to the first question in
a vocabulary of dependency types, and the answers to the
second question in a design space of coordination processes.
Finally, we would like to connect each of the whys, with
a set of hows, that is, associate each dependency type
with a set of coordination processes for managing it.
A vocabulary of interdependency patterns would greatly aid designers
in constructing application architectural diagrams. Instead of
always inventing a new dependency to express a given component
relationship, designers would often simply choose one from the
dependency vocabulary.
Furthermore, the existence of a coordination process design space
would reduce the step of managing dependencies with coordination
processes to a routine, or even automatic, selection of an element
from a coordination process repository.
Finally, a vocabulary of dependency types and coordination processes
would contribute to an increased understanding of the problems
of software interconnection. Over time, researchers have developed
a vast arsenal of algorithms and techniques for process synchronization,
communication, and resource allocation. What has been missing
so far is a unified framework for relating those algorithms to
the problems they are attempting to solve. Such a framework should
encompass (and relate to one another) synchronization, communication,
and resource allocation considerations. It should relate techniques
and algorithms that are currently being studied by a number of
different research areas (programming languages, operating systems,
concurrent and distributed systems). Therefore, it could form
the basis for developing a design handbook of software component
interconnection. Such a handbook could help reduce the integration
of existing software components into new applications to a routine
design problem.
The approach taken in this chapter is based on coordination theory
[Malone94], an emerging research area that focuses on the interdisciplinary
study of coordination. Coordination theory defines coordination
as the process of managing dependencies among activities. One
of its objectives is to characterize different kinds of dependencies
and identify the coordination processes that can be used to manage
them. This work extends the frameworks presented in [Malone94],
and is the first detailed application of the theory to the understanding
of software component relationships. Coordination theory is discussed
in more detail in Section 7.2.
It is important to emphasize that the results described in this
chapter do not claim rigorous generality and completeness. Our
goal was to develop a dependency vocabulary and coordination process
design space that covers a useful subset of the component
relationships and constraints encountered in practice. The SYNOPSIS
machinery enables designers to incrementally enrich this vocabulary
with new abstractions and processes. It is our hope that this
work will provide a useful starting point that will lead in interesting
extensions by future research.
4.2 Overview of the Dependencies Space
The vocabulary of dependencies presented in this chapter is based
on the simple assumption that component interdependencies are
explicitly or implicitly related to patterns of resource production
and usage. In other words, activities need to interact with
other activities, either because they use resources produced by
other activities, or because they share resources with other activities.
The definition of resources can be made broad enough to make this
assumption cover most (if not all) cases of component interaction
encountered in software systems. Our current definition of resources
encompasses:
processor time (control)
data of various types
operating system resources (memory pools, pipes, sockets, etc.)
hardware resources (printers, disks, multimedia adapters, etc.)
In every resource relationship, participating activities can be
distinguished into two roles:
Resource producers
Resource consumers
The existence of two different roles in resource relationships,
implies the existence of three different classes of dependencies:
Dependencies between producers and consumers
Dependencies among consumers who use the same resources
Dependencies among producers who produce for the same consumers
Dependencies between producers and consumers are modeled using
a family of dependencies called flow dependencies. Malone
and Crowston [Malone94] have observed that, in general, whenever
flows occur, one or more other sub-dependencies are present. In
particular, flow dependencies can be decomposed to the following
set of lower-level dependencies:
Sections 4.5 and 4.6 are devoted to a detailed discussion of flow
dependencies.
Sharing dependencies contained inside flows assume that multiple
users of a resource are independent, and therefore competing
with one another for resource access. In many applications however,
users (or producers) of a resource are cooperating in application-specific
ways. In those cases, designers must explicitly specify
additional dependencies that describe the patterns of cooperation
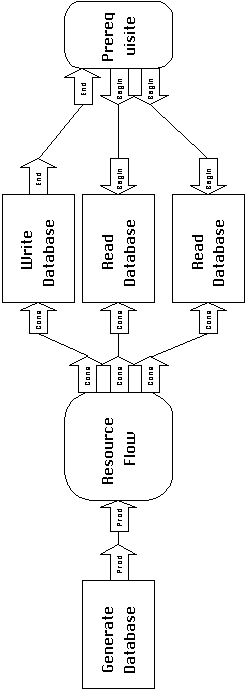
among users (or producers). Imagine, for example, a database resource
which is generated by some activity and subsequently used by three
other activities. In one particular application, one of the users
of the database is using it to write values that will be read
by the other users. This application-specific pattern of cooperation
among users of the database requires the specification of an additional
prerequisite relationship between the writer and the reader activities
(Figure 4_1).
Application-specific patterns of cooperation among activities
that share resources are expressed using additional flows and
another family of dependencies called timing dependencies. Timing
dependencies express constraints on the relative flow of control
among a set of activities. The most widely used are prerequisite
dependencies (A must complete before control flows into B)
and mutual exclusion dependencies (A and B cannot execute
at the same time).
In addition to specifying application-specific cooperation patterns,
timing dependencies are often used to specify implicit resource
relationships. For example, mutual exclusion dependencies
are often used to specify implicit resource sharing relationships,
in which support for resource accesses is embedded inside the
code of each activity. Also, prerequisite dependencies often specify
implicit flow relationships in which resource production and consumption
are embedded inside the code. Section 4.7 describes a family of
timing dependencies. For each dependency, its relationship with
a resource dependency is illustrated.
Throughout the chapter, it becomes apparent that, apart from classifying
and enumerating elementary dependency types, it is also useful
to begin to collect and classify sets of frequently occurring
composite dependency patterns. In many cases, designers
have developed specialized, more efficient joint coordination
processes for such patterns. Section 4.8 will present a few useful
composite patterns of flows and joint coordination processes for
managing them.
4.3 The Concept of a Design Space
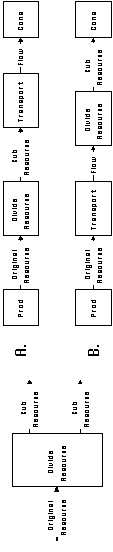
As with any complex taxonomy, it is useful to classify both dependencies and coordination processes using multi-dimensional design spaces [Bell72, Lane90]. Each dimension of the design space describes variation in some design choice. Values along a dimension are called design alternatives. They correspond to alternative requirements or implementation choices. For example, when selecting a data transportation mechanism, the number of data readers could be one design dimension; the location of readers relative to the writer could be another. Figure 4-2 illustrates a tiny design space for selecting a data transportation mechanism.
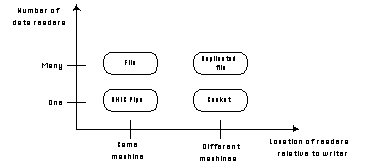
Figure 4-2: A simple design space for selecting
a data transportation mechanism.
Specific designs are described by points in the design space,
identified by the dimensional values that correspond to their
design choices.
Successful design spaces reduce the problem of design to that
of answering a simple set of questions. They also organize related
design alternatives "close" to each other and expose
correlations between various aspects of design. Finally, they
can be easily translated into computerized knowledge bases that
can help semi-automate the design task.
Our problem requires the construction of two, related, design
spaces:
In addition, each point in the dependency design space (dependency
type) must be associated to a coordination design space for managing
it.
Our objective in the following sections is to define related dependency
and coordination design spaces for each family of dependencies.
The success of a design-space description of design alternatives
clearly lies in the choice of dimensions and specific dimensional
values (design alternatives). There is no obvious rigorous way
of defending a particular set of choices. Neither Bell and Newell
[Bell72], nor Lane [Lane90] have offered any justification for
their dimensions and alternatives, except for their own intuition
and the usefulness of the resulting description. I will follow
the same path, simply proposing a set of dimensions and trying
to show empirically that they form a useful description of design
alternatives.
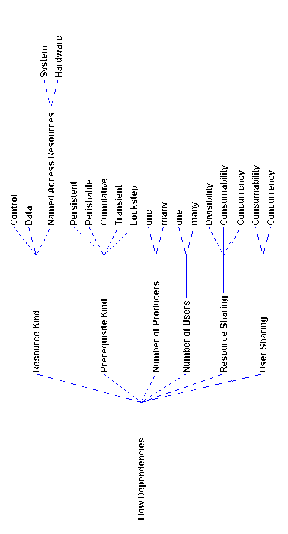
Before we begin the description of resource flow dependencies,
we present a taxonomy of resources occurring in software systems.
This taxonomy will be useful both for distinguishing between different
special cases of flow relationships, and for determining the range
of alternative ways of managing them.
The taxonomy is summarized in Figure 4-3 The following is a discussion
of its principal dimensions.
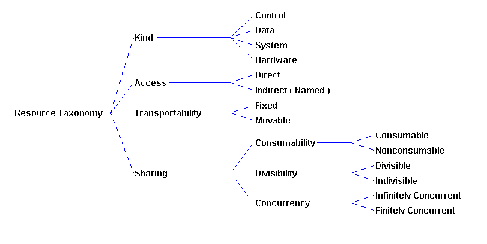
Control. The resource usually referred to in Computer Science
as control, is more accurately described as a thread
of processor attention. In order for any software activity
to begin execution, it needs to receive control from somewhere,
that is, it needs to receive the attention of some processor.
Control flow dependencies thus describe the flow of processor
attention from one activity to another.
Resource access determines how producers and users access their
corresponding resources.
The use of identifiers is extremely widespread in software systems.
Identifiers provide mappings that allow a wide variety of resources
(system, hardware, complex data structures) to be accessed by
software components that can only interface with their environment
through relatively simple data resource ports.
System and hardware resources are always accessed indirectly.
Complex data resources, such as files and databases, are also
typically accessed using identifiers.
4.4.3 Resource Transportability
Transportability determines whether resources can be moved around
in the system.
This section describes a framework for reasoning about shared
resources that was developed by George Wyner and Gilad Zlotkin
at the MIT Center for Coordination Science [Wyner95a].
Wyner and Zlotkin proposed a small number of important resource
attributes that can help designers classify coordination requirements
for shared resource dependencies. They observed that these important
attributes are not merely a function of the resource type, but
of the intended mode of usage as well. That is, the same
resource type, used in different modes (e.g. read versus written),
might display different sharing behavior along those attributes.
For that reason they refer to them as attributes of resources-in-use.
These attributes are:
a. Divisibility
Divisibility specifies whether a resource-in-use can be divided
into independent subresources. Some example of divisible and indivisible
resources are shown below.
| Resource | Usage | Description |
|
Divisible | ||
| Memory heap | Read/Write | Heaps can be divided into independent smaller blocks |
| Network channel | Connect | Physical network channels can support multiple independent connections |
|
Indivisible | ||
| Scalar variable | Read/Write | Scalar variables can only store one value |
| pgp Encrypted File | Decrypt | Encrypted files can only be decrypted in their entirety |
b. Consumability
Consumability specifies whether a resource-in-use is being destructively
consumed. Consumable resources can be used a finite amount of
times. Nonconsumable resources can be used an arbitrarily large
amount of times. Some example of consumable and nonconsumable
resources in use are shown below:
| Resource | Usage | Description |
|
Consumable | ||
| Pipe channel | Read | Values "disappear" from the channel as they are being read |
| PROM | Write | PROMs (Programmable Read Only Memories) can only be written once |
|
Nonconsumable | ||
| File | Read | Files can be read an arbitrarily large amount of times |
| Processor | Start Task | Processors can be used to start an arbitrarily large number of tasks |
c. Concurrency
Concurrency specifies whether a resource-in-use can be used by
more than one users at the same time. Concurrency can be finite,
setting a finite limit on the number of concurrent users, or infinite
(arbitrarily large). The following are examples of finitely and
infinitely concurrent resources.
| Resource | Usage | Description |
|
Infinitely Concurrent | ||
| File | Read | In most systems, multiple users are allowed to read files concurrently |
| Multitasking Processor | Start Task | Multitasking systems appear to execute multiple tasks concurrently |
|
Finitely Concurrent | ||
| Ftp Server | Connect | Ftp servers often limit the number of concurrent connections for performance reasons |
| Printer | Print File | Printers cannot interleave the printing of different files |
4.5 A Generic Model of Resource Flows
This section presents a generic model for classifying flow dependencies
and a generic process for managing them. Section 4.6 describes
how this generic model can be specialized to manage different
special cases of flow dependencies.
In the most general case, flow dependencies exist between a number
of resource producers and a number of consumers (Figure 4-4).
Dependencies are connected to activities through resource producer
and consumer ports. Producer and consumer ports are abstract
ports (see Section 3.3.3). That is, they are composite ports
that contain implementation-specific groupings of low-level interface
ports that logically participate in the production and consumption
of a given resource.
We assume that, by default, a flow dependency between a set of
activities implies a stream of resource flows over the
lifetime of an application execution. Coordination processes for
managing flow dependencies are designed with this assumption in
mind. Situations where resources are produced or consumed only
once during the lifetime of an application execution are represented
by special types of dependencies.
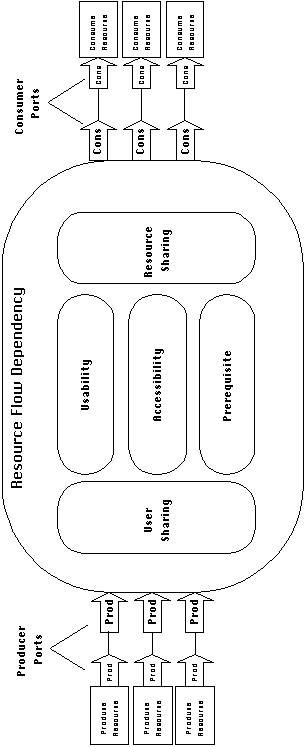
| Dependency | Description |
| Usability | Produced resources must be in a form usable by each user |
| Accessibility | Produced resources must be made accessible to each user |
| Prerequisite | Resources must be produced before they can be used |
| Resource sharing | Multiple consumers share the same resources |
| Consumer sharing | Multiple producers produce resources for the same consumers |
Our objectives in this section are the following:
Both design spaces are based on a generic model for decomposing
flow dependencies into lower-level dependencies, shown in Figure
4-4. Managing a flow dependency implies managing all lower-level
dependencies. This model extends the ideas introduced in [Malone94],
and attempts to capture the different considerations that must
be addressed whenever resources are exchanged or shared among
different activities.
The generic model for managing flow dependencies focuses on the
relationships between producers and users of resources. It assumes
that different consumers (producers) are independent from one
another and compete for access to resources (consumers).
In the following sections, we will first introduce dependency
and coordination processes design spaces for each of the lower-lever
dependencies. The design space for generalized flow dependencies
will then be defined by the product of the component dependencies
design spaces.
4.5.1.1 Types of usability dependencies
Usability dependencies state the simple fact that resource users
should be able to properly use produced resources. This is a very
general requirement that encompasses compatibility issues such
as:
The exact meaning and range of usability considerations varies
with each kind of resource. Section 4.6, which describes specializations
of flow dependencies for a variety of different resources, also
discusses in more detail the meaning of usability dependencies
for each of them.
4.5.1.2 Managing usability dependencies
One interesting observation resulting from this work is that,
irrespective of the particular usability issue being managed,
coordination alternatives for managing usability dependencies
can be classified using the following two design dimensions (Figure
4-5) :
| Design Dimension | Design Alternatives |
| Who is responsible for ensuring usability? | - Designer (Standardization)
- Producers - Consumers - Both producers and consumers - Third party |
| When are usability requirements fixed? | - At design-time
- At run-time |
Who is responsible for ensuring usability ?
The following alternatives are possible:
- Designer is responsible (No run-time coordination is necessary).
Components are specially selected at design-time so as to be compatible
with one another. This is often achieved by developing applications
using standardized components. Examples of standardized component
families include OLE objects, OpenDoc components, Visual Basic
VBXs, etc [Adler95]. The advantages of this approach include run-time
efficiency and reliability. On the other hand, it limits the choice
of components for a particular functional requirement to those
explicitly designed for the particular standardized environment.
- Producers are responsible for ensuring usability. This
implies that the producer knows the format expected by the users,
and is able to generate or convert its resources to the user format.
- Consumers are responsible for ensuring usability. This
requires the consumer to recognize the format of resources it
receives, and to be able to convert them to its own format, if
necessary.
- Third party ensures usability between producers and consumers.
Third party must know and be able to handle both formats.
- Both producers and consumers convert to and from an interchange format. The advantage of this approach is that it does not require prior knowledge of the formats produced and expected by producers and users. This is particularly desirable if producers and users are dynamically changing, and each of them is using a different native format. The disadvantage is that two conversions take place, which might be inefficient if conversions are computationally costly. Producers and users must agree on the interchange format.
Are usability requirements fixed ?
Coordination processes can be further classified depending on
whether the producer and consumer formats are fixed and known
at design-time, or whether they are negotiated at run-time. In
the latter case, the management of usability dependencies might
introduce additional flow dependencies to the system, that have
to be managed in turn.
4.5.2 Accessibility Dependencies
4.5.2.1 Types of accessibility dependencies
Accessibility dependencies specify that a resource must be accessible
to a user before it can be used. Since users are software activities,
accessibility specifies more accurately that a resource must be
accessible to the process that executes a user activity before
it can be used. Important parameters in specifying accessibility
dependencies are the number of producers, the number of users,
and the resource kind.
4.5.2.2 Managing accessibility dependencies
There are two broad alternatives for making resources accessible
to their users (Figure 4_6):
Depending on the type of resource being transferred, either or
both alternatives might be needed. Placing producer and user activities
"close" to one another generally decreases the cost
of transporting the resource. Combinations of placing activities
and transporting resources should be considered in situations
where the cost of placing the activities is lower than the corresponding
gain in the cost of transporting the resource.
The following is a discussion of the two alternatives:
| Principal design alternatives | First-level of specialization | Second-level of specialization |
|
Place producers and consumers "close together" | Place at design-time Place at run-time | - Package in same sequential module
- Package in same executable - Assign to same processor
- Assign to nearby processors - Code is accessible to all processors - Physical code transportation required |
Transport resource | Actual processes depend on resource kind (see Section 4.6) | |
a. Place producers and users "close together"
This can be done either at design-time, or at run-time.
ul>
- Place activities at design-time. The following is a list
of ways to manage this step, in decreasing order of efficiency:
b. Transport resource from producers to users
This step depends on the kind of resource that is flowing. It
is discussed in more detail in Section 4.6.
4.5.3 Prerequisite Dependencies
4.5.3.1 Types of prerequisite dependencies
A fundamental requirement in every resource flow is that a resource
must be produced before it can be used. This is captured by including
a prerequisite dependency in the decomposition of every flow dependency.
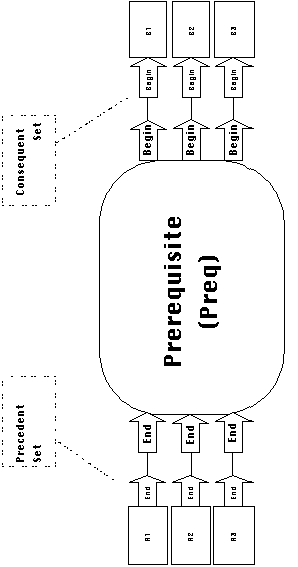
Prerequisites are relationships between two sets of activities
(Figure 4-7). In the following discussion we will refer to set
A as the precedent set and to set B as the consequent
set. As is the case with flow dependencies, prerequisite dependencies
in our vocabulary have stream semantics: they assume that
precedent and consequent activities might execute multiple times
over the lifetime of an application execution. Prerequisite dependencies
thus specify constraints on the allowed execution interleavings
of precedent and consequent activities.
Prerequisite dependencies occur very frequently in software architectures.
They are the most frequently used member of the dependency family
we call timing dependencies. Timing dependencies express constraints
in the timing of control flow into a set of activities. They are
discussed in Section 4.7.
Prerequisite dependencies form a family of related sequencing
constraints. The most useful members of the prerequisite family
are the following:
The above variations of prerequisite relationships can be organized
in a specialization hierarchy, as shown in Figure 4-9. The implication
of prerequisite specialization relationships is that coordination
processes for managing a prerequisite relationship can also be
used to manage any of its parent relationships in the specialization
structure. For example, in order to manage a cumulative prerequisite,
in addition to using processes specifically designed for this
type of prerequisite, designers can also consider using coordination
processes for transient or lockstep prerequisites.

Prerequisite dependencies can be further classified according
to:
4.5.3.2 Managing prerequisite dependencies
There are four generic processes for managing prerequisite dependencies
(Figure 4-10):
a. Producer Push
This process decomposes into a control flow dependency (Section
4.6.1). The alternatives for managing it are the same as those
of managing the corresponding control flow dependency.
Producer push processes manage lockstep prerequisites. Consequents
are invoked once each time the precedents complete execution.
Producer Push |  |
As soon as the precedent completes, it invokes the consequent by explicitly passing control to them. |
Consumer Pull | 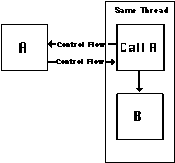 |
Before it begins execution, the consequent synchronously calls the precedent. |
Peer Synchronization | 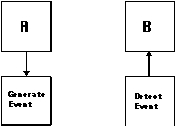
| Both precedent and consequent are executed by independent threads of control and synchronize themselves using shared events. |
Controlled Hierarchy | 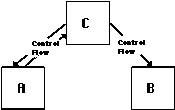
| A third party controls the invocation of both the precedent and the consequent |
b. Consumer Pull
This process family decomposes into a synchronous call pattern
of control flow dependencies. The alternatives for managing it
are the same as those of managing the corresponding pattern of
control flows.
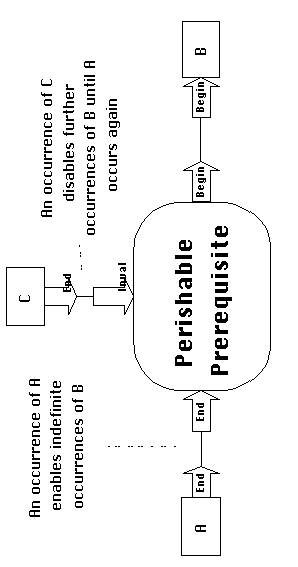
Consumer pull processes manage lockstep prerequisites. Precedents
are invoked once before each consequent. Consumer pull organizations
can also be used to manage persistent and perishable dependencies:
Before starting itself, each consequent checks whether the prerequisite
condition is valid, and invokes the precedent activities if it
is not.
c. Peer Synchronization
Peer synchronization processes can be used to manage all kinds
of prerequisites. Figure 4_11 shows their generic form for each
kind of one-to-one prerequisite. All processes can be generalized
to handle many-to-many prerequisites.

Figure 4-11: Generic processes for managing prerequisite
dependencies using peer event synchronization.
Peer Synchronization processes rely on the generation and detection
of shared events in the system. Events can be classified as follows
(Figure 4-12):
Memoryless events can be further distinguished into persistent
and transient.

Persistent Memoryless Events
| Event type | Generate | Detect | Reset |
| Semaphore | Signal Semaphore (V) | ||
| File Creation | Create File | Test File Existence | Delete File |
| File Modification | Write File | Compare file modification time with stored modification time | Set stored modification time to file modification time |
| Process Creation | Create Process | Test Process Existence | Kill Process |
Transient Memoryless Events
| Event type | Generate | Detect |
| UNIX Signal mechanism | signal system call | wait system call |
| Windows DDE mechanism | send DDE transaction | initialize DDE conversation |
Cumulative Events
| Event | Reset | Increment | Decrement | Detect |
| Counting Semaphore | Set semaphore to zero | Signal semaphore | ||
| List | Clear List | Add element to list | Remove element from list | Check if list is empty |
d. Controlled Hierarchy
There are three variations on this process:
Controlled hierarchy processes can be used to manage lockstep
prerequisites. Permanent prerequisites can also be managed by
this approach by placing the prerequisite code before any other
code in the system (e.g. in an initialization module or at the
top of the main program).
Figure 4-13 summarizes the design dimensions of prerequisite dependencies
and coordination processes.
| Principal Design Dimensions | Design Alternatives | Other Design Dimensions |
| Type of prerequisite | - Persistent
- Perishable - Cumulative - Transient - Lockstep | |
| Organization of coordination mechanism | - Producer Push
- Consumer Pull
- Peer Synchronization - Controlled Hierarchy | - Synchronous vs. Asynchronous
control flow
- Type of shared event used - Wait for precedent completion vs. pre-scheduling |
4.5.4.1 Types of sharing dependencies
Sharing arises when more than one activity requires access to
the same resource. Sharing dependencies can be specialized using
the three dimensions of the resource-in-use framework of Section
4.4.4. For each different combination of resource-in-use parameters
(e.g. indivisible, consumable, concurrent), a different specialization
of sharing dependency can be defined.
Sharing dependencies arise in one-to-many, many-to-one, and many-to-many
flow dependencies in two distinct situations:
a. Resource sharing
Resource sharing considerations arise in one-to-many flow dependencies,
because more than one activity uses the same resource. Resource
users are assumed to be independent. Therefore, the sharing coordination
requirements depend solely on the sharing properties of the resource.
The different possibilities are:
| Resources can be divided among the users. | |
| The total number of users must be restricted. | |
| The number of concurrent users must be restricted . |
b. Consumer sharing
Consumer sharing dependencies arise in many-to-one flow dependencies
because more than one producers produce for the same consumer
activity, viewed as a "resource". Consumer "resources"
can be characterized using the resource-in-use framework. The
different dimensions are:
| Divisibility | Consumer activities either occur or do not occur. Therefore, they are considered indivisible resources. |
| Consumability | Consumability of a consumer activity means that it can occur a limited number of times or, equivalently, that it can accept a limited number of produced resources. This implies the need for coordination in order to select which resources will be accepted. Modeling consumer activities as consumable resources enables many-to-one flow dependencies to be used for modeling race conditions. |
| Concurrency | Concurrency determines whether multiple instances of a consumer activity can be active at the same time. Some consumer activities are nonconcurrent (e.g. non-reentrant procedures). In that case, coordination should be installed to restrict simultaneous execution of more than one activity instances. |
Many-to-many flow dependencies contain a combination of both resource
and consumer sharing dependencies.
4.5.4.2 Managing sharing dependencies
The problem of resource sharing has been studied extensively by
researchers in various areas and there exists a huge literature
of related algorithms and techniques. Our purpose in this section
is to take an architectural look at resource sharing techniques,
showing how their interfaces can be abstracted to a small number
of generic processes, and how they relate to the other components
of a resource flow management process in a small, well-defined
number of ways.
There are three general techniques for coordinating resource sharing
requirements (Figure 4-14):
| Resource Type | Sharing Coordination Required | Specializations |
| Divisible Resources | Divide Resource | - Divide before transportation
- Divide after transportation |
| Indivisible Resources | ||
| Consumable and/or
Finitely Concurrent | Restrict access to resource Replicate resource | - Restrict consumer activity execution
- Restrict resource transportation
- Restrict resource production |
| Nonconsumable and
Infinitely Concurrent | No sharing coordination is required |
a. Divide resource
This technique applies to divisible resources. It can be represented
by a process that uses the entire resource and produces a set
of new subresources (Figure 4-15). Subresources are considered
independent resources and can then flow to each user with no further
coordination.
There are two different ways a resource divide can be combined
with the rest of a flow coordination process:
b. Restrict access to resource
This very general technique applies to both consumable and nonconcurrent
resources. In both cases the function of the coordination process
is to restrict the flow of control into activities accessing the
resource (Figure 4-16). More specifically:
From an architectural perspective, there are three different ways
an access restriction process can be integrated with the rest
of a flow coordination process:
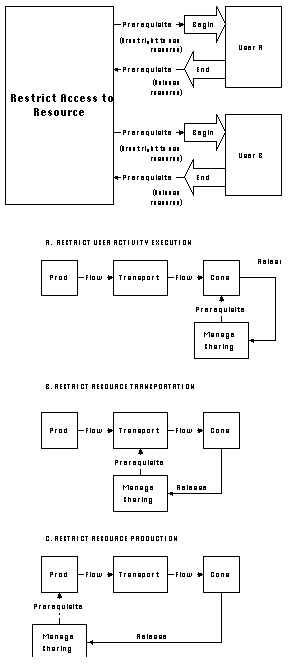
c. Replicate Resource
Resource replication is a technique that jointly manages accessibility
and resource sharing dependencies. Its more general architectural
form is similar to that of a resource division process. However,
it applies to indivisible resources.
Combinations of division and restriction
The previous techniques can be combined to handle more complex
resource sharing requirements. For example, in order to share
a resource that is nonconcurrent and finitely divisible among
a potentially infinite number of users a combination of division
and access restriction can be used: Whenever an access is desired,
extraction of a new subresource is first attempted. If that fails,
time-sharing is used. This algorithm is used, for example, to
manage the sharing of finite capacity buffered input/output channels
among a potentially infinite number of user processes.
4.5.5 Putting it all together: Flow
dependencies
The design dimensions of generalized resource dependencies are
the sum of the design dimensions of their component dependencies
(Figure 4-17). For each combination of dimension values, a different
special case of resource flow can be defined. The following is
a discussion of the different dimensions and the alternative flow
dependencies they can be used to define.
a. Resource kind
The most important design dimension is the kind of resource. Section
4.6 will describe how resource dependencies are specialized according
to this dimension.
b. Prerequisite relationship
Another important dimension is the kind of prerequisite requirement.
According to this dimension, resource relationships are classified
into:
Managing Prerequisite Coordination Processes
The coordination process selected to manage a prerequisite dependency
at the heart of a resource flow has a profound influence on the
overall organization of the interacting activities. Corresponding
to the four generic classes of prerequisite coordination processes
we have an equivalent taxonomy of flow organizations:
If control is transferred to users using synchronous calls, this
organization reduces to what is commonly called client/server
architecture. In this case, resource producers acts as clients
and resource users act as servers.
Pull organizations of flow dependencies also reduce to client/server
architectures. In this case, resource users act as the clients
and resource producers act as the servers. Note, however, that
the direction of the client/server relationship is the inverse
of the direction of the flow relationship.
c. Number of producers and users - Sharing dimensions
| one-to-all | Each resource flows to all users |
| one-to-one-of-many | Each resource flows to one of the users. This can be managed in an application-independent way (e.g. first come-first served), or in an application-specific way. In the latter case, user consumer ports usually provide additional pieces of information, such as user priorities. |
Situations where users are not willing to receive all resources
produced are often referred to as race conditions. In our
framework, race conditions are modeled as many-to-one dependencies
where the user activity acts as a consumable "resource".
General ways of managing consumable resources can be used to manage
the dependency.
| each-to-all | Every resource produced flows to all users |
| each-to-one | Every resource produced flows to one user only |
| each-from-one | Each user receives one resource only |
| all-from-one | Only one of the resources produced flows to (all) users |
The design alternatives for managing resource dependencies are
the product of the different alternatives for managing each component
dependency. In principle, each of the component dependencies can
be managed by independent coordination processes. In practice
however, there often exist opportunities to increase efficiency
by managing patterns of dependencies using joint coordination
processes. This gives rise to additional design alternatives that
designers should be aware of. We have already encountered the
opportunity to use joint coordination processes for managing
accessibility and sharing (restrict resource transportation, replicate
resource). In the following sections, we will encounter more opportunities
for joint dependency management.