Chapter 3
In this chapter, we begin the description of the principal end
products of this research. Our overarching objective, argued for
in the previous chapter, is to support a more efficient process
for developing software applications out of existing parts. The
process generates new applications by applying a series of computer-assisted
transformations to descriptions of their architecture. The purpose
of this chapter is to describe the first requirement for supporting
the process: An architecture description language called SYNOPSIS.
The language provides linguistic support for representing and
transforming software architecture diagrams. It has two principal
distinguishing features: First, it enables a clear separation
of an application's core functional pieces from their interdependencies.
Second, it supports entity specialization, a mechanism through
which software architectures can be described at various levels
of abstraction. The chapter begins by outlining the major design
objectives of SYNOPSIS. It then gives an overview of the language,
based on a simple example. The main body of the chapter is devoted
to a detailed discussion of SYNOPSIS language elements, element
transformations, and compatibility checking mechanism.
3.1 Language Design Objectives
The purpose of SYNOPSIS is to provide linguistic support for representing
and transforming the entities of the component-based application
development process that was outlined at the end of the previous
chapter (see Figure 2-8). More specifically, support is needed
in the following three areas:
3.1.1 Representation of Application
Architectures
It should be possible to clearly separate the core functional
pieces of an application from their application-specific patterns
of interdependencies.
Chapter 2 presents our detailed argument for developing software
system description notations with this property. SYNOPSIS satisfies
this requirement by supporting two distinct language elements:
activities, for representing core functional parts and
dependencies, for representing interconnection relationships
among activities.
It should be possible to separate the specification of system
architecture from the implementation of the elements being structured.
Such a separation is desirable in order to be able to:
select or replace components for implementing activities independently
of one another (their specification-level interdependencies do
not change; different component implementations might influence
the implementation of interaction protocols)
port an application to different configurations (specification-level
relationships do not change; implementation of interaction protocols
is the element most likely to change across configurations)
SYNOPSIS satisfies this requirement by representing implementation-level
entities as optional attributes of activities and dependencies.
Thus, activities can optionally be associated with a code-level
component, such as a source code module, an executable
program, or a network server. Dependencies can optionally be associated
with a coordination process, representing a protocol for
managing the relationship described by the dependency.
Section 3.3 describes SYNOPSIS language elements in detail.
3.1.2 Transformation of Application
Architectures
It should be possible to connect the specification of system
architecture and the implementation of the elements being structured
through well-defined, structural transformations.
This requirement is instrumental to allowing the generation of
executable applications directly from their architectural diagrams.
SYNOPSIS supports the mechanism of entity specialization which
allows generic application architectures to be transformed to
executable systems by successive specialization of activities
and dependencies contained in their decomposition.
Section 3.5 describes the mechanism of entity specialization.
3.1.3 Support for Compatibility Checking
It should be possible to specify and check compatibility restrictions
and configuration constraints on the interconnection of application
elements.
In a manner analogous to type checking in programming languages,
it is desirable to be able to perform limited static checking
of compatibility when connecting or transforming elements. Such
controls facilitate the construction of correct architectures
and help designers focus their attention to more complex issues.
SYNOPSIS provides such a mechanism, based on matching element
attribute values. The mechanism is described in Section 3.4.
This section introduces a simple example application that will
serve as a guide to the various elements of SYNOPSIS. We will
refer to this example again in Chapters 5 and 6, in order to illustrate
how the system can integrate a set of heterogeneous software components
into a smoothly running executable application.
The example system is a file viewer application that consists
of three simpler subsystems:
_ a user interface that repeatedly asks users for code numbers
of interest
_ a filename retrieval subsystem that receives user-supplied code
numbers and retrieves matching filenames from a database
_ a file viewer subsystem that displays the contents of each retrieved
file
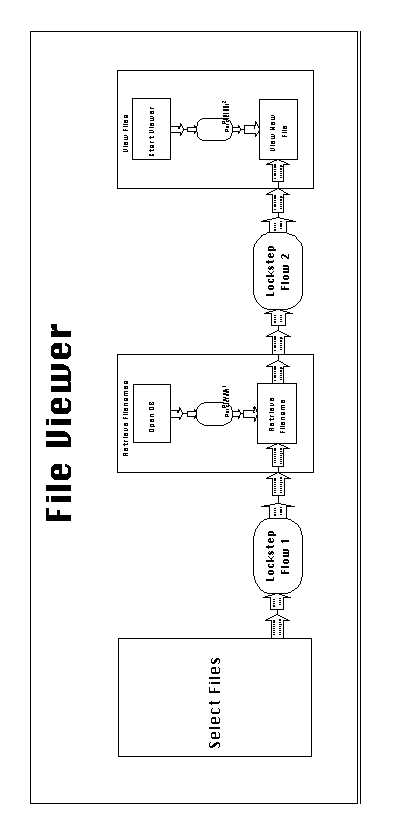
Figure 3-1 depicts the architecture of the application, expressed
as a SYNOPSIS diagram. Two distinct kinds of entities can be immediately
distinguished in the diagram: Activities, drawn as rectangles,
and dependencies, drawn as ovals.
Each of the three application subsystems corresponds to a different
activity in the diagram. Activity Select Files is atomic,
while activities Retrieve Filenames and View Files are composite,
decomposing to patterns of simpler elements. The entire application,
File Viewer, is also defined as a composite activity.
Dependencies encode relationships among the application's activities.
Flow dependencies connect producers and consumers of data
resources. In this application, they indicate that user-supplied
code numbers must flow from the user interface to the filename
retrieval subsystem. Likewise, retrieved filenames must flow from
the filename retrieval to the file viewing subsystem. Prerequisite
dependencies (labeled Persistent Prereq) indicate that the filename
database must be opened (once) before any filename retrieval takes
place, and that the file viewer subsystem must be initialized
(once) before any file can be displayed.
Activities and dependencies are connected together via ports.
Ports are an abstract mechanism for representing an element's
needs for interaction with the rest of the system. For example,
activity Retrieve Filename, has three ports: Two of them are data
resource ports, encoding the fact that it needs to receive data
resources of type Integer (code number), and that it produces
data resources of type String (filename). The third is a Begin
control port, encoding the fact that flow of control into the
activity must follow the completion of activity Open DB.
All elements of the language (activities, dependencies, ports)
may contain an arbitrary number of additional attributes. Attributes
are name-value pairs that encode additional information about
the element. They are also used to express compatibility restrictions
that constraint the connection of elements.
Activity ports are connected to corresponding dependency ports
using wires, drawn as line segments in the diagram. Every
time a new connection is attempted, the system performs a compatibility
check, based on unification of corresponding attribute values
at the two ends of the connection.
The diagram of Figure 3-1 conveys the structure of the File Viewer
application independent of the implementation of its elements.
It is a generic (specification-level) view of the application.
The goal of the process outlined in Section 2.4 is to be able
to generate an executable system by applying a series of transformations
to that diagram. From a language perspective, this requires support
for implementation-level entities that implement the intended
functionality of activities and dependencies.
SYNOPSIS supports such a set of entities, defined as attributes
of their respective activities and dependencies. They are called
software components, coordination processes and software
connectors.
Software components are code-level software entities, such
as source code modules, executable programs, user-interface functions,
network services etc. SYNOPSIS provides a special notation for
describing the properties of software components (see Section
3.3.1.2).
Our objective in this example is to construct the File Viewer
application out of a set of existing, heterogeneous code-level
components:
_ a C source module implementing the user interface subsystem
_ a Visual Basic module implementing the filename retrieval subsystem
_ a commercial text editor in executable form implementing the
file viewing subsystem
Coordination processes manage dependencies. They represent
implementations of interaction protocols. They are patterns of
simpler activities and dependencies. Finally, software connectors
represent low-level interconnection mechanisms, directly supported
by the semantics of programming languages and operating systems.
Examples include procedure calls, method invocations, local variables,
etc.
Activities represent the main functional pieces of an application.
They own a set of ports, through which they interconnect
with the rest of the system. Interconnections among activities
are explicitly represented as separate language elements, called
dependencies. Activities must always connect to one another through
dependencies. As a consequence, every activity port must be connected
to a compatible dependency port.
Activities are defined as sets of attributes which describe their
core function and their capabilities to interconnect with the
rest of the system. The two most important activity attributes
are:
An (optional) decomposition. Decompositions are patterns
of simpler activities and dependencies which implement the functionality
intended by the composite activity. The ability to define activity
decompositions is the primary abstraction mechanism offered by
SYNOPSIS.
An (optional) component description. Component descriptions
connect SYNOPSIS activities with code-level components which implement
their intended functionality. Examples of code-level components
include source code modules, executable programs, network servers,
etc.
Depending on the values of the above two attributes, activities
are distinguished as follows (Figure 3-2):
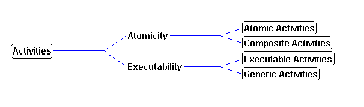
Atomic or Composite. Atomic activities have no decomposition.
Composite activities are associated with a decomposition into
patterns of activities and dependencies.
Executable or Generic. SYNOPSIS allows the description
of software systems at various levels of abstraction. This is
manifested by allowing activities to be executable or generic.
Executable activities are defined at a level precise enough to
allow their translation into executable code. Activities are executable
either if they are associated with a component description, or
if they are composite and every element in their decomposition
is executable. Activities which are not executable are called
generic. To generate an executable implementation, all generic
activities must be replaced by appropriate executable specializations.
Throughout this thesis, we will use the term primitive
to refer to entities that are both atomic and executable.
3.3.1.1 Activity decompositions
Activity decompositions are patterns of activities and dependencies
that implement the intended functionality of a composite activity,
with which they are associated. Activity decompositions must obey
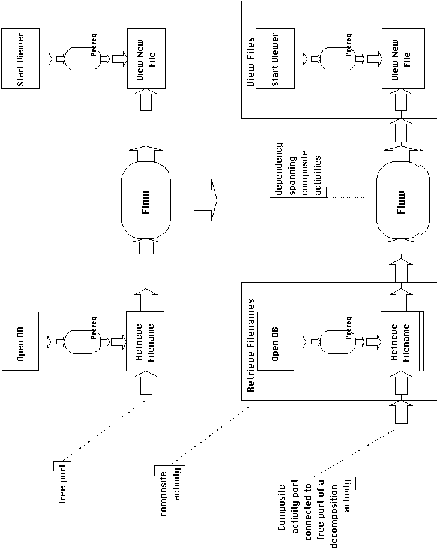
the following structural restrictions (Figure 3-3):
All free ports of activities contained in the decomposition
(i.e. ports not connected to other decomposition elements) must
be connected to compatible ports of the composite activity. This
simply states that the external points of interaction of a composite
activity with the rest of the system are equal to the points of
interaction of its decomposition, minus the interactions that
are internal to the decomposition.
Dependencies contained in an activity decomposition can have no
free ports. This states that, if a dependency is included in a
decomposition, all of its ports must be connected to activities
included in the same decomposition. Dependencies that span composite
activities must be defined outside of any of them. This rule is
an equivalent way of expressing the requirement that activities
must always be connected to one another through intermediate dependencies.
3.3.1.2 Component descriptions
Activities describe the functional pieces of an application. These
functional pieces are implemented either by decomposing them into
equivalent patterns of simpler activities and dependencies, or
by associating them with appropriate code-level software components.
In order to properly integrate such software components into executable
systems, our system needs some information about their interfaces,
source and object files, and other related attributes. SYNOPSIS
provides a special notation called Component Description Language
(CDL) for describing the properties of software components
associated with executable activities. CDL should be thought of
as "syntactic sugar" that eventually translates into
sets of SYNOPSIS attribute definitions. These definitions are
stored in the corresponding executable activity.
SYNOPSIS component descriptions must include information about:
_ the component kind
_ the provided interface of the component
_ expected interfaces of other components
_ source and object files needed by the component
_ additional attributes specific to the component
The following paragraphs describe each part of the description
in more detail:
Component kinds
Software components come in a variety of forms, such as source
modules, executable programs, user-interface functions, etc. One
of the main objectives of the entire project is to be able to
combine together heterogeneous components of arbitrary form. SYNOPSIS
provides support for defining arbitrary component kinds. This
mechanism is described in detail in Chapter 5. From a CDL perspective,
each component kind is represented by a different keyword. Table
3-1 describes the component kinds supported by the current prototype
implementation of the system.
| Component Type | CDL Keyword | Description |
| Source procedure | proc | A source code procedure or equivalent sequential code block (subroutine, function, etc.) |
| Source module | module | A source code module, consisting of one or more source code files and containing its own entry point (main program). Modules interact with the rest of the system through expected interfaces only. |
| Filter | filter | A source code procedure that reads its inputs from and/or writes its outputs to sequential byte streams |
| Executable | exec | An executable program |
| DDE server | ddes | A DDE server embedded inside an executable program |
| OLE server | oles | An OLE server embedded inside an executable program |
| Gui-Function | gui | A function provided by the graphical user interface of some executable program, typically activated through a key sequence |
Provided component interface
Software components interact with other components by providing
input-output interfaces. Depending on the component kind, such
interfaces might correspond to procedure parameter lists, executable
program command line invocation interfaces, user interface function
activation key sequences, etc. When associating software components
to executable activities, each element of the provided interface
must be mapped to a corresponding atomic port of the activity.
Expected interfaces of other components
This part of the description reflects the fact that current-technology
software components often make assumptions about the existence
of other components or services in the system. For example, a
source module might be calling an externally defined procedure
with specified name and parameter interface. A Microsoft Windows
executable program might assume the existence of a DDE server
application with given specifications. Such expectations are documented
in this section, using a syntax identical to the one used to define
the component's provided interface. When associating software
components to executable activities, each element of each expected
interface must also be mapped to a corresponding atomic activity
port.
Files needed by the component
Software components are usually pieces of code, residing in one
or more source or object files. This section specifies the relevant
set of files, to be eventually included in the final application.
Additional component attributes
For every kind of component, there is a set of required attributes
that must be specified. Examples of such attributes include the
programming language (for source components), the invocation pathname
(for executable programs), the service and topic names (for a
DDE server component), the activation key sequence (for user-interface
services), etc. There are also optional attributes, such as restrictions
on the target environment or host machine.
Figure 3-4 shows the CDL descriptions of components associated
to the five executable activities of the File Viewer application
that was introduced in Section 3.2.
|
Component "Select Files" IsA Procedure
Provides:
proc select_files();
Expects:
proc view_selected_files(in codenum:Integer);
Source Files:
\fviewer\select.c
Attributes:
Language = c
End Component |
|
Component "Retrieve Filename" IsA Function
Provides:
func retrieve_filename(in codenum:Integer):String;
Source Files:
\fviewer\retrieve.bas
Attributes:
Language = vb
End Component |
|
Component "Start Viewer" IsA Executable
Provides:
exec msword();
Attributes:
ExePath = \applic\msoffice\winword\winword.exe
End Component |
|
Component "Open DB" IsA Procedure
Provides:
proc init_DB();
Source Files:
\fviewer\retrieve.bas
Attributes:
Language = vb
End Component |
|
Component "View New File" IsA Gui-Function
Provides:
gui open_file(in filename:String);
Attributes: guiWindow = "Microsoft Word"
guiKeys = "^O@1~"
End Component |
Figure 3-4: Component Descriptions for the File
Viewer example application (Figure 3-1).
Activity Select Files is associated with a C source code function,
called select_files. This function contains an internal loop that
repeatedly asks users for a code number. For each user-supplied
code number, it calls function view_selected_files, to which it
passes the user-supplied code number as an argument. Function
view_selected_files is not part of this module and is expected
to exist somewhere in the same executable. Its single parameter
codenum is mapped to a corresponding producer port of activity
Select Files. File select.c contains the code and data definitions
for select_files and any other internal functions it may call.
Similarly, activities Open DB and Retrieve Filename are associated
with Visual Basic procedures defined in file retrieve.bas.
Activity Start Viewer is associated with an executable program
(Microsoft Word, a commercial text editor). Enactment of the activity
corresponds, in this case, to invoking the program. The component's
CDL provided interface describes the command line parameters for
starting the program. In this case there are no command line parameters,
other than the program pathname.
Finally, activity View New File is associated with a graphical-user-interface
function offered by the text editor. In order to display a new
file, the text editor normally expects to receive a key sequence
in its main window, consisting of the character CTRL-O, followed
by the required filename, followed by a newline character. Thus,
this service expects one abstract data resource (the filename),
embedded in a key sequence whose generic format is described by
attribute guiKeys. In this example, guiKeys contains the characters
^O (=CTRL-O), followed by @1 (=the value of the first interface
element, in this case the filename), followed by ~ (=newline).
Finally, attribute guiWindow specifies the title of the editor's
main window, where the activation key sequence must be sent.
Dependencies describe interconnection relationships and constraints
among activities. Traditional programming languages do not support
a distinct abstraction for representing such relationships and
implicitly encode support for component interconnections inside
their abstractions for components (see Chapter 2). In contrast,
SYNOPSIS requires that all interconnections among activities are
explicitly represented using dependencies. Like activities, dependencies
own ports. Dependency ports must be connected to compatible activity
ports.
Like activities, dependencies are defined as sets of attributes.
The most important attributes are:
An (optional) decomposition into patterns of simpler dependencies
that collectively specify the same relationship with the composite
dependency.
An (optional) coordination process. Coordination processes
are patterns of simpler dependencies and activities that describe
a mechanism for managing the relationship or constraint implied
by the dependency.
An (optional) association with a software connector. Connectors
are low-level mechanisms for interconnecting software components
that are directly supported by programming languages and operating
systems. Examples include procedure calls, method invocations,
shared memory, etc.
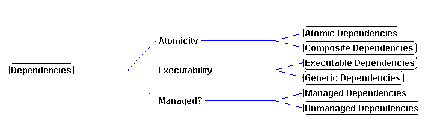
Depending on their values in the above attributes, dependencies
are distinguished into the following categories (Figure 3-5):
Atomic or composite. Atomic dependencies have no
decomposition. Composite dependencies are associated with patterns
of simpler dependencies that specify the same relationships.
Managed or unmanaged. Managed dependencies have
an associated coordination mechanism, specifying one way of managing
the interconnection relationship they represent. Unmanaged dependencies
have no associated coordination process. They simply specify the
existence of a relationship and must be specialized by appropriate
managed dependencies before code generation can take place.
Executable or generic. Executable dependencies are
defined at a level specific enough to be translated into executable
code. Dependencies are executable if one or more of the following
conditions hold: (1) they are directly associated with a code-level
connector, (2) they are composite and all elements of their decomposition
are executable, (3) they are managed and all elements of their
coordination process are executable.
SYNOPSIS allows the definition of arbitrary dependency types.
However, one of our goals is to make the step of specifying and
managing dependencies a routine one. For that reason, it is useful
to define a standardized vocabulary of common dependency types
that covers a large percentage of activity relationships encountered
in software systems. Such a vocabulary will be described in Chapter
4. Figure 3-6 shows some examples of common dependencies.
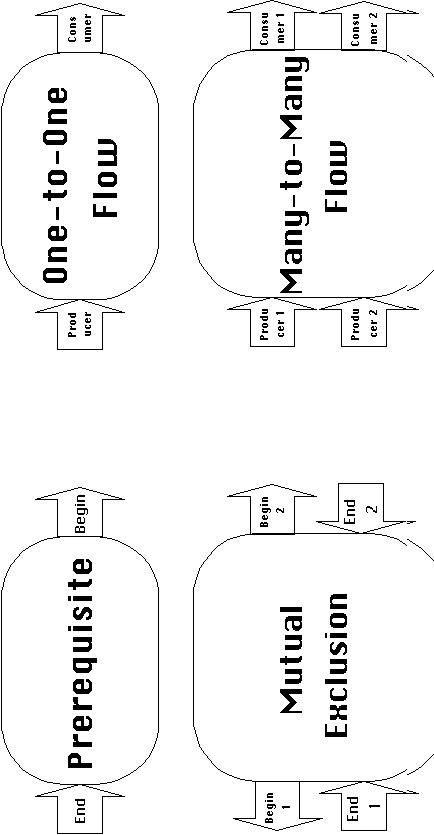
3.3.2.1 Dependency decompositions
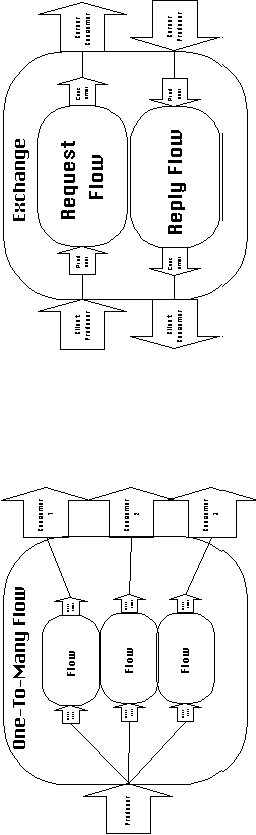
Some dependencies can be equivalently described by patterns of
simpler dependencies. Such patterns are called dependency decompositions
and are defined as attributes of composite dependencies. Figure
3-7 shows some examples of composite dependencies and their decompositions.
3.3.2.2 Coordination processes
Dependencies specify interconnection relationships which translate
into needs for interaction among a set of activities. For
example, a prerequisite dependency indicates a need to make sure
that an activity does not take place before another activity has
ended.
To generate executable systems, dependencies must be managed
by inserting appropriate interaction or coordination
mechanisms into the system. SYNOPSIS provides the abstraction
of coordination process, defined as an attribute of dependencies,
to represent and localize the definition of such interaction mechanisms.
Coordination processes are patterns of simpler dependencies and
activities. In that sense, they are very similar to activity decompositions.
Coordination processes must obey the following structural restrictions,
which are the dual of the equivalent restrictions for activity
decompositions (see Section 3.3.1.1):
All free ports of dependencies contained inside a coordination
process (i.e. ports not connected to other elements of the coordination
process) must be connected to compatible ports of the associated
dependency. This simply states that the external points of interaction
of a coordination process with the rest of the system are equal
to the points of interaction of its elements, minus the interactions
that are internal to the coordination process.
Activities contained inside a coordination process can have no
free ports. This basically states that, if an activity is included
in a coordination process, all of its ports must be connected
to dependencies included in the same coordination process. Activities
that span coordination processes must be defined outside of any
of them. This rule is an equivalent way of expressing the requirement
that dependencies must always be connected to one another through
intermediate activities.
Figure 3-8 shows a SYNOPSIS definition of a coordination process
that implements a pipe channel protocol (manages one-to-one flow
dependencies). It is a pattern of three activities, and five lower-level
dependencies.
Dependencies describe interconnection relationships among components.
These relationships are managed either by coordination processes,
described as patterns of simpler activities and dependencies,
or by associating them with appropriate code-level software connectors.
Connectors represent low-level software component interaction
mechanisms built into the semantics of programming languages,
or implicit in the semantics of operating system calls. Examples
include:
_ design-time ordering of program statements in the same sequential
code block (manages prerequisite dependencies)
_ local variable transfer (manages flow dependencies)
_ transport of data from one process to another implicit in the
semantics of a UNIX pipe protocol
Ports encode abstract interfaces ("needs for interaction")
of activities and coordination processes. All connections between
SYNOPSIS language elements are done through ports.
As is the case with activities and dependencies, SYNOPSIS ports
are distinguished into composite and atomic.
Composite ports act as abstract port specifications, describing
a port's logical role in the system. They decompose into sets
of simpler ports, which might themselves be composite or atomic.
Atomic ports directly map to an element of some implementation-level
component interface (see Section 3.3.1.2).
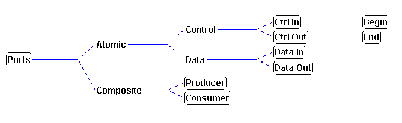
Figure 3-9 shows the SYNOPSIS built-in specialization hierarchy
for ports. SYNOPSIS users are free to define new ports as specializations
of the built-in types, or define completely new port types.
The built-in port hierarchy implies that atomic ports are either
input or output ports of data or control.
Atomic data ports are mapped to atomic interface elements
of software components or executable coordination processes. The
mapping is performed by setting attribute MapsTo at the port to
a string indicating the respective interface element. Depending
on the component kind, an atomic port might thus correspond to
a source procedure parameter, a command line argument, a user-interface-function
activation key sequence, an event detected or generated by a program,
an object generated or used by an executable program, etc. All
atomic data ports contain an attribute named Resource, which lists
the data type expected to flow through the port.
Atomic control ports model the flow of control in and out
of an activity or coordination process. Every activity has at
least one pair of control ports modeling the beginning and end
of execution of the activity. These ports are called the Begin
and End ports. Complex activities might have additional control
ports, modeling, for example, periodic calls to other activities
that take place during the life of the original activity (Figure
3-10).
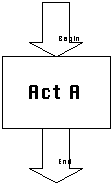
|
Component "Act A" IsA Procedure
Provides:
proc act_a();
End Component
|
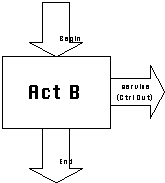
|
Component "Act B" IsA Procedure
Provides: proc act_b(); Expects:
proc service();
End Component |
Sets of atomic ports can be optionally grouped inside composite
ports. Our built-in port hierarchy contains only two types of
composite ports: producer and consumer ports, specifying
the production and consumption of abstract resources.
Designers might want to use composite ports for two reasons:
to indicate sets of logically related interface elements in a
given implementation, and
to indicate generic needs of interaction when designing generic
entities. Different specializations of a given generic entity
might contain different decompositions of the same composite port,
corresponding to the variety of interfaces by which a given abstract
need for interaction can be implemented.
The rest of the section describes an example of the use of composite
ports.
We are designing an application which processes the contents of
an input file. One of the activities in this application will
make the contents of that file available to the rest of the system.
Initially, we do not know the exact implementation and interface
of the component that will implement that activity. We, therefore,
specify a generic activity called Generate Input, which contains
a generic producer port, through which the contents of the input
file will be made available to the rest of the system (Figure
3-11(a)). In the application diagram, that producer port will
be connected to dependency ports connecting it to the consumer
activities.
There are at least two ways to implement activity Generate Input.
Figure 3-11(b) shows a filter implementation. The activity
is associated to a component that writes its output to an externally
opened sequential byte stream. The same byte stream must be read
by consumer activities to retrieve the contents of the input file.
In this case, the composite producer port decomposes to a data
input port, corresponding to the file descriptor of the sequential
byte stream that must be passed to the filter. It is interesting
to note that, in this case, a composite producer (i.e. output)
port, decomposes into an atomic data input port.
Figure 3-11(c) shows another way to implement Generate Input.
For each line of the input file, the second implementation calls
a procedure, which it expects to have been defined externally.
It passes the current input line as a string parameter to the
procedure. In this case, the composite input port decomposes into
a data output port, corresponding to the string parameter of the
procedure called by the component.
By default, every composite activity port includes the Begin and
End ports of its associated activity in its decomposition. Activity
ports are directly connected to coordination process ports. Coordination
processes often need to control what happens before or after the
execution of an activity. This requires them to have access to
the Begin and End ports of an activity. In actual practice, this
requirement is frequent enough that we decided it to include Begin
and End ports in the decomposition of every composite activity
port by default.
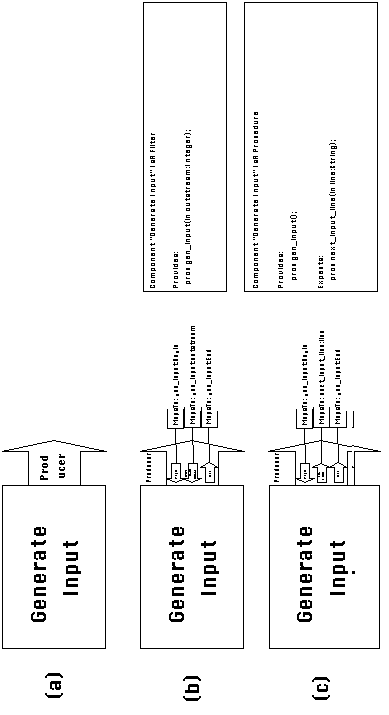
Figure 3-11: (a) A generic activity containing a generic producer port.
(b) One executable specialization of the previous activity and its corresponding generic port decomposition into atomic ports.
(c) Another executable specialization of the same
activity, which has a different decomposition of the generic port.
Most interactions among software components center around the
flow and sharing of various kinds of resources. In most cases,
resources are dynamically produced during run-time, as a result
of execution of activities. Such dynamically produced resources
are implicitly modeled in SYNOPSIS diagrams through producer ports.
As mentioned in the previous section, ports contain special attributes
which describe the data type, or other properties, of the resources
that flow through them.
In many software applications, however, there exist some resources
that have been produced outside of the scope of the application.
Examples include hardware resources, such as a printer, and resources
produced by other applications, such as a database.
SYNOPSIS models such preexisting resources using a special resource
language entity. Like activities, resource entities own ports,
through which they are connected to the rest of the system. Atomic
activity ports, are associated with interface elements of software
components. In contrast, atomic resource ports are bound
to constant data values, which usually correspond to resource
identifiers.
Figure 3-12 depicts an example of the use of resource entities
in SYNOPSIS diagrams. Resource entity Database represents a preexisting
database file which is being shared by two activities in this
application. Database has a single port, which is bound to the
filename of the database file. This filename must be made known
to the two user activities (through a Flow dependency), in order
for them to be able to access the database.
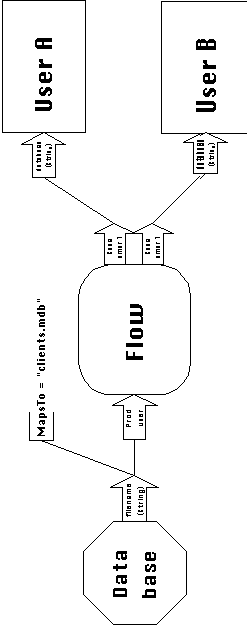
Attributes are name-value pairs that specify additional information
about SYNOPSIS language entities. Attribute values can be scalar,
lists, or pointers to other SYNOPSIS entities. Although SYNOPSIS
supports the definition of arbitrary attributes, the system is
using some conventions about required attributes in each entity
type. Some of those conventions have been collected in Table 3-2.
As more experience is gained from using the system, more such
useful conventions are expected to emerge.
In the current implementation attributes play an important role:
_ in determining compatibility of an element with its neighbors
in the system
_ in integrating components and coordination processes into sets
of executable modules
The following additional features of the attribute mechanism are
especially designed to support the compatibility checking process:
| Entity type | Required
Attributes | Description |
| All activities | Environment | execution environment(s) for which activity is compatible |
| Activities associated to source module components | Language
Executable | source programming language of module name of executable where module is to be integrated |
| Activities associated with executable program components | ExePath | pathname of executable program |
| Activities associated with DDE server components | Service
Topic | Server DDE service name Server DDE topic name |
| Activities associated with graphical user interface function components | guiKeys guiWindow | Format string of activation key sequence Name of window where activation key sequence should be sent |
| All atomic ports | MapsTo Resource | pointer to interface element corresponding to
port type of data flowing through port |
Attribute Inheritance
As will be described in Section 3.5, all SYNOPSIS language elements
inherit the decomposition and all attributes from their specialization
parents. In addition to that, SYNOPSIS language elements also
inherit all attributes defined at their decomposition parents.
This feature enables attributes that are shared by all members
of a composite element to be defined only once at the decomposition
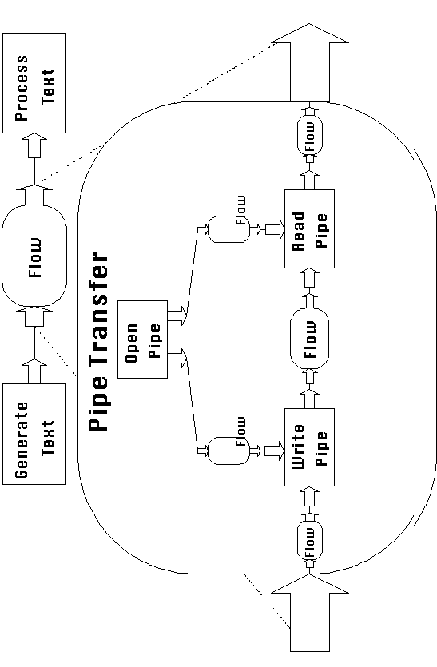
parent level. For example, in Figure 3-13, all activities and
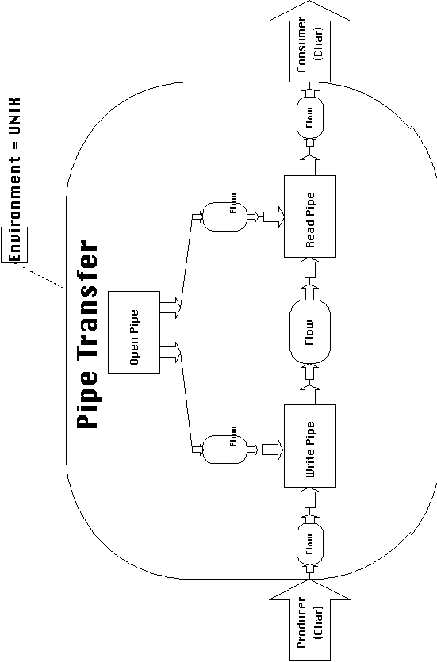
dependencies contained inside UNIX Pipe Transfer inherit the attribute
definition Environment = UNIX, which denotes that they are compatible
with the UNIX environment.
Since ports owned by an element are considered to be parts of
its decomposition, ports always inherit all attributes defined
at their owner.
Attribute Variables
In addition to normal values, attributes can be assigned to attribute
variables. Attribute variables are strings that begin with "?".
For example:
Resource = ?res
Procedure = ?proc
Attribute variables need not be declared. They are automatically
created the first time they are referenced.
Unique variables are special attribute variables whose
names begin with the string "?unq" (e.g. ?unq-var, ?unq1,
etc.). They have the special requirement that their values cannot
be equal to the value of any other variable in the same scope.
They are used to express inequality constraints (see Section 3.4.1).
Attribute variables are local to each owner element (activity,
dependency, resource) but are shared among an owner element and
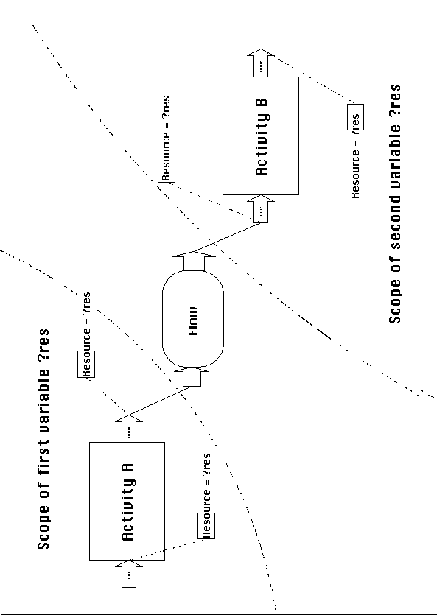
all its ports. For example, in Figure 3-14, both references to
variable ?res at ports of Activity A refer to the same variable.
Setting the variable at one of the ports will affect both attribute
definitions. Likewise, both references to variable ?res at ports
of Activity B refer to the same variable. However, references
across activities refer to different variables. For example,
setting the variable ?res at Activity A will not affect the value
of variable ?res at Activity B.
Wires, drawn as simple line segments, indicate that a legal connection
has been established between two ports. Wires established between
composite ports imply a set of legal connections between each
of their corresponding subports.
There are two types of wires in SYNOPSIS diagrams.
Internal wires connect free ports of decomposition or coordination
process elements to compatible ports of their associated composite
elements. For example, in Figure 3_3 two internal wires connect
the two free ports of atomic activity Retrieve Filename to compatible
ports of composite activity Retrieve Filenames. Likewise, in Figure
3-8 internal wires connect the three Flow dependencies contained
in the decomposition of One-To-Many Flow to compatible ports of
the composite dependency. Establishment of a legal internal wire
requires that the decomposition or coordination process port (the
internal port) is equal to or a specialization of the composite
element port (the external port) to which it is being connected.
External wires connect activity ports to dependency ports.
It is illegal to connect an activity port directly to another
activity port, or a dependency port directly to another dependency
port. Furthermore, the port at the activity side must be equal
to or a specialization of the port at the dependency side. This
restriction reflects the coordination perspective on software
architecture adopted by SYNOPSIS, whereby software systems are
represented as sets of activities interconnected through explicitly
represented relationships (dependencies).
3.4 Checking Element Compatibility
SYNOPSIS language elements have several semantic restrictions
and constraints on their ability to connect to other elements.
Some of these restrictions are encoded in the syntax of the language.
For example, activity ports can only be connected to dependency
ports (and vice versa). Furthermore, dependency ports can only
connect to activity ports that are equal to or a specialization
of them. Such restrictions are described in Section 3.3.6. Other
restrictions are specific to the attributes of code-level elements
(components and connectors) associated with executable activities
and dependencies. Examples of such restrictions include:
An activity associated with a source code procedure returning
an integer value can only be connected to other activities through
dependencies associated with coordination processes capable of
transporting integer values.
_ Flow dependencies managed by local variable connectors can only
connect activities whose associated components can be packaged
inside the same sequential code block.
_ Flow dependencies managed by DDE transfer coordination processes
can only connect activities whose associated components will be
packaged in different executables within the same Microsoft Windows-based
host.
We would like to be able to encode such restrictions and constraints,
so that a number of compatibility tests can be performed automatically
by the language. Hence, a problem similar to type checking in
a programming language arises in SYNOPSIS whenever two elements
are connected together. Since all SYNOPSIS connections are between
ports, it is desirable to be able to perform compatibility checks
at the port level.
SYNOPSIS bases its compatibility checking on attributes. Attributes
are used to specify compatibility restrictions. Before establishing
a connection between two ports, SYNOPSIS performs a port matching
algorithm that determines port compatibility.
Figure 3-15 describes the algorithm. The algorithm compares the
values of all attributes that exist at both sides of the attempted
connection. If both attributes have a fixed value then the two
values must match. If either attribute is assigned to a variable,
a process similar to unification takes place. If at least one
attribute fails to match, the connection is considered illegal.
Check_Compatibility( aport, dport ) |
Figure 3-15: Port compatibility checking algorithm.
3.4.1 Using Attributes to Encode Constraints
The semantics and scope rules of attributes and variables (see
Section 3.3.5) permit a number of compatibility constraints to
be encoded into attributes. The following paragraphs give some
examples of how some of the most useful kinds of constraints can
be encoded using the attributes mechanism.
"An attribute must have a specific value at all neighbor
elements"
This is encoded by defining the attribute with the specified value
at all ports where this condition is required. If the condition
is required at all ports of an owner element, the attribute need
only be defined once at the owner element.
Example: A dependency managed by a coordination process
encoding a UNIX pipe protocol can only be used to connect components
that will run in UNIX environments. Designers can encode this
constraint by defining an attribute Environment set to UNIX at
the top level of the process (Figure 3-13). This attribute is
inherited by all ports. In order to pass the compatibility check,
all connected activities must contain the attribute set to the
same value.
"An attribute must have the same (unspecified) value at
all neighbor elements"
This can be encoded by setting the attribute to the same variable
name at all ports where this condition is required. The unification
process will only succeed if the equivalent attribute at the other
end of all connections has the same value.
Example: Local variable transfer is the simplest coordination
process for managing flow dependencies. However, it can only be
used if all its members (a) produce and use the same data type,
and (b) can be packaged into the same procedure. The latter requirement
implies that they also have to be written in the same language
and be packaged into the same executable program. All these constraints
can be encoded into the ports of the associated dependency as
shown in Figure 3-16.
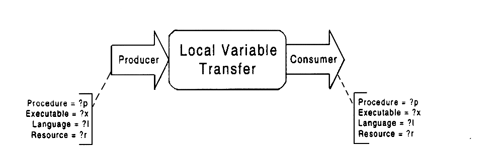
Figure 3-16: Activities connected to both endpoints
of this dependency must have identical values for the specified
attributes.
"An attribute must have a different value at each neighbor
element"
This can be encoded by setting the attribute to a different unique
variable (see Section 3.3.5) at each port where this condition
is required. Since each unique variable cannot be unified to a
value given to any other variable, unification will only succeed
if the attribute has a different value at each neighbor element.
Example: Dynamic Data Exchange (DDE) is one protocol for
transferring data among different executable programs in the Microsoft
Windows operating system. It does not work properly for transferring
data within the same executable. Thus, it can only connect components
that will be integrated into different executables. This constraint
can be encoded into the ports of the associated dependency as
shown in Figure 3-17.
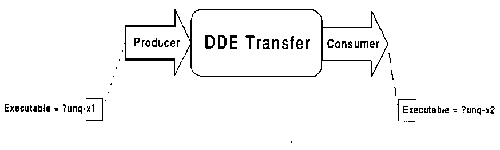
Figure 3-17 : Activities connected at the endpoints
of a dependency managed by a DDE Transfer coordination process
must be packaged into different executables.
3.4.2 The Dual Purpose of Attribute
Matching
Attribute unification simultaneously checks constraint compliance
and creates equivalence classes of attribute values across a number
of elements. For example, an attempt to connect two activities
through a dependency managed by a local variable transfer coordination
process (Figure 3-16), not only checks whether the two endpoint
activities can be packaged together into the same procedure, but
also unifies attribute Procedure at both of them to the same equivalence
class. This will help the code generator determine that the two
activities should be packaged into the same procedure.
Attribute unification is therefore one of the mechanisms used
by the system in order to integrate activities and dependencies
into sets of executable modules. This aspect of the system will
be described in more detail in Chapter 5.
Object-oriented languages provide the mechanism of inheritance
to facilitate the incremental generation of new objects as specializations
of existing ones, and also to help organize and relate similar
object classes. SYNOPSIS provides an analogous mechanism called
entity specialization. Specialization applies to all the
elements of the language, and allows new activities, dependencies,
ports and resources to be created as special cases of existing
ones. Specialized entities inherit the decomposition and
other attributes of their parents. They can differentiate themselves
from their specialization parents by modifying their structure
and attributes using the operations described below. Entity specialization
is based on the mechanism of process specialization that was first
introduced by the Process Handbook project [Malone93, Dellarocas94].

Figure 3-18: A hierarchy of increasingly specialized
coordination processes for managing prerequisite dependencies.
The mechanism of entity specialization enables the creation of
specialization hierarchies for activities, dependencies, ports,
and coordination processes. Such hierarchies are analogous to
the class hierarchies of object-oriented systems. In specialization
hierarchies, generic designs form the roots of specialization
trees, consisting of increasingly specialized, but related designs.
The leafs of specialization trees usually represent design elements
that are specific enough to be translated into executable code
(Figure 3-18). Specialization hierarchies have proven to be an
excellent way to structure repositories of increasingly specialized
design elements, such as the vocabulary of common dependency types
we shall introduce in Chapter 4.
Apart from enabling the organization of related design elements
in concise hierarchies, entity specialization also encourages
application development by incremental refinement of generic application
architectures. Designers can initially specify their applications
using generic activities and dependencies. Such generic application
architectures can then be iteratively refined by replacing their
generic elements with increasingly specialized versions, until
all elements of the architecture are executable. The existence
of repositories of increasingly specialized design elements can
reduce the specialization steps to a routine selection of appropriate
repository elements.
In a way analogous to object-oriented class creation, all SYNOPSIS
elements are created as specializations of other elements. New
elements inherit the decomposition, coordination process, and
all other attributes defined in their specialization parent. They
can differentiate themselves from their parents by applying any
number of the following transformations to their attributes (see
[Wyner95b]):
_ Add or delete a decomposition or coordination process element
_ Replace a decomposition or coordination process element with
one of its specializations
_ Add or delete a connection
_ Add or delete an attribute
_ Modify the value of an attribute
Figure 3-19 shows an example of how an executable dependency can
be defined as a special case of a generic one by inheriting the
coordination process of its parent and then replacing all generic
activities and dependencies contained therein with executable
specializations. Figure 3-19 (a) depicts a generic coordination
process for managing flow dependencies using pipes. The process
describes the essence of a pipe protocol independently of the
particular system calls that are used to implement it in a given
environment. It is generic because it contains three generic activities
and five unmanaged dependencies. Figure 3-19 (b) depicts an executable
specialization of the pipe transfer protocol, specific for the
UNIX operating system. The specialization inherited the design
elements of the original protocol and replaced generic activities
and unmanaged dependencies with executable specializations, appropriate
for the UNIX operating system.
This operation allows incremental refinement of architectural
diagrams. Designers can specify SYNOPSIS architectures in very
generic terms and then incrementally specialize their elements
until an executable design has been reached. Such a process is
supported by the ability to maintain hierarchies of increasingly
specialized activities, encoding families of alternative designs
for specific parts of software architectures.
From a linguistic perspective, an activity can only replaced with
a specialization if the new specialization is able to structurally
replace the original activity and legally connect to all neighbor
elements connected to it. If the specialization is composite,
the same requirements apply for its decomposition as well. The
requirements translate to the following port compatibility requirements:
_ For each connected port of the original activity, there must
be an equivalent port of the specialization.
_ Each port of the specialization must be compatible with the
dependency port to which the corresponding port of the original
activity was connected.
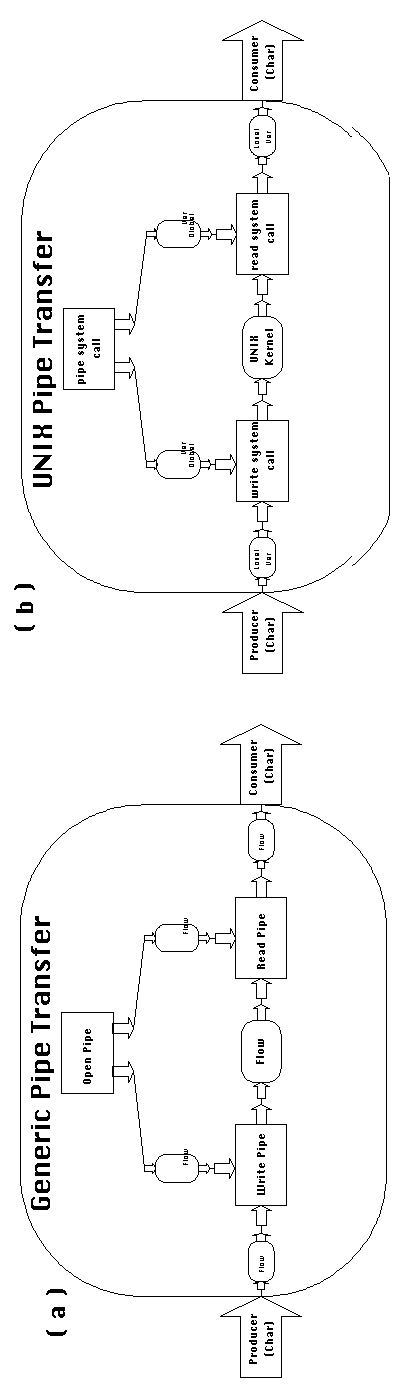
Figure 3-19: (a) A generic coordination process that manages flow dependencies using pipes.
(b) An executable specialization of the previous
process.
3.5.3 Specializing Dependencies
Generic dependencies are descriptions of needs of interaction
among software activities. They are useful for constructing configuration-independent
architectural descriptions of software systems that clearly show
why activities need to interact with one another. In order
to derive executable implementations from such abstract descriptions,
designers can follow two alternative paths:
If the generic dependency has a decomposition, replace all elements
of the decomposition with executable specializations.
Replace the generic dependency with a managed specialization.
Managed dependencies are associated with coordination processes.
Coordination processes represent interaction protocols. From a
linguistic perspective, a dependency can only replaced with a
specialization if the new specialization is able to structurally
replace the original dependency and legally connect to all neighbor
elements connected to it. If the specialization is managed, the
same requirements apply for its coordination process as well.
The requirements translate to port compatibility requirements
similar to the ones for specializing activities:
- For each connected port of the original
dependency, there must be an equivalent port of the specialization.
- Each port of the specialization must be compatible with the
activity port to which the corresponding port of the original
dependency was connected.
SYNOPSIS provides the abstractions needed in order to describe
application designs as sets of activities connected by dependencies.
It also provides the mechanism of entity specialization that enables
generic application architectures to be transformed to executable
designs by:
replacing generic activities with executable specializations
replacing generic dependencies with managed specializations
integrating activities and dependencies into executable modules
The first transformation requires locating appropriate code-level
components that implement activity functional requirements. We
consider this problem the responsibility of the designer and have
argued in Section 1.1 that it is being made simpler by today's
technologies.
Chapter 4 will present a vocabulary of common dependency types
and a design space of associated coordination processes that aims
to reduce the second transformation to a routine design step,
capable of being assisted, or even automated, by computer.
Finally, Chapter 5 will discuss the problems and solutions of
automating the third transformation.