Chapter 2
In this chapter we seek to understand why current technologies
for composing software components into new applications often
require so much additional design effort, as to make the development
of applications from scratch preferable to the reuse of existing
components. We analyze the process of component composition and
argue that the difficulties of performing its steps are closely
related to the failure of current programming languages and design
tools to separate the implementation of component interconnection
protocols from that of the "core" function of each component.
We then argue that the composition effort can be reduced, if we
separate the design problem of component interconnection from
that of implementing a component's core function, and begin to
comprehend, represent and systematize its design dimensions and
design alternatives in a coherent framework. This argument forms
the principal thesis of the work. We outline a set of notations,
theories and tools needed to support this separation. We propose
a new, improved component composition process based on them. This
sets the stage for the rest of the thesis, which presents one
concrete implementation of those requirements and demonstrates
how they can form the basis of a useful methodology for component-based
application development and maintenance.
2.1 Software Applications are Interdependent
Sets of Activities
When a software engineer begins the design of a new software application,
he/she often draws a diagram labeled the "software architecture".
The diagram usually consists of boxes, depicting the main functional
pieces of the application, and lines, depicting interconnection
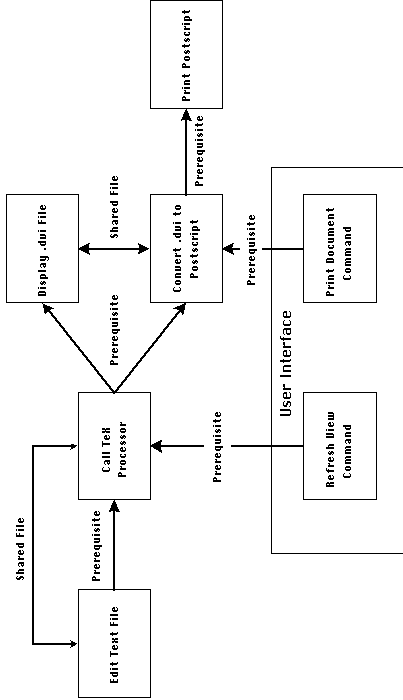
relationships among functional pieces. For example, Figure 2-1
shows one way of representing the architecture of a document processing
application based on the TEX system.
Figure 2-1: A software architecture for a document
processing application. Boxes correspond to activities while labeled
arcs represent dependencies.
At this level of description, software applications are systems
of interdependent software activities. In this thesis, we will
use the term activities to describe the major functional
elements of an application. We will use the term dependencies
to describe relationships and constraints among activities, such
as data and control flows, timing constraints, or resource sharing
relationships. Table 2-1 lists some dependency types commonly
encountered in software systems.
Software architecture diagrams are specification-level
descriptions of software systems. In order to obtain the desired
behavior of an application, activities must be implemented by
executable activities or software components and
dependencies must be managed by appropriate coordination processes.
Software components are software entities of various forms, including
source code modules, executable programs, or remote network services.
Coordination processes implement component interconnection protocols,
such as pipe channels (manage one-to-one flow dependencies), client/server
organizations (manage many-to-one flow dependencies), semaphore
protocols (manage mutual exclusion dependencies), etc.
Some coordination processes correspond to atomic language or operating
system protocols (such as a simple procedure call). Other describe
composite protocols which introduce additional activities and
dependencies to be integrated into the rest of the system. It
is important to observe that, whereas software activities relate
to concepts specific to the application domain, interdependency
patterns relate to concepts orthogonal to the problem domain
of most applications, such as transportation and sharing of resources,
or synchronization constraints among components.
| Dependency Type | Design Dimensions | Coordination Processes |
| Prerequisite | - number of precedents
- number of consequents - relationship among precedents (And/Or) | - Explicit Notification
- Event Polling |
| Mutual Exclusion | - number of participants | - Semaphore protocol
- Token Ring protocol |
| Data Flow | - number of
producers
- number of consumers - data type(s) produced - data type(s) consumed | - Shared Memory protocol
- Pipe protocol - Client/Server protocol |
| Shared Resource | - number of users
- modes of usage - resource sharing properties | - Time-Sharing
- Paging - Replication |
Table 2-1: Some common types of dependencies encountered
in software systems and representative coordination processes
for managing them.
________________________________________________________________________
Example 2-1: Dependencies and Coordination Processes
Figure 2-2 depicts a simple architecture where a one-to-one flow
dependency connects two activities. One way of managing this dependency
is by setting up a pipe protocol between the two activities. The
pipe protocol introduces three new activities and two new dependencies
into the system.
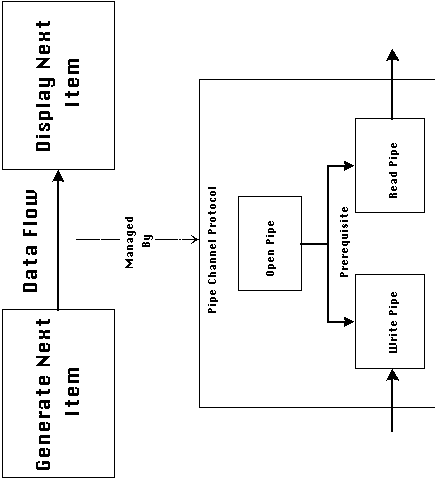
Figure 2-2: A simple application architecture
and a coordination process for managing a data flow dependency
between its activities.
________________________________________________________________________
Example 2-2: Dependency patterns define system behavior
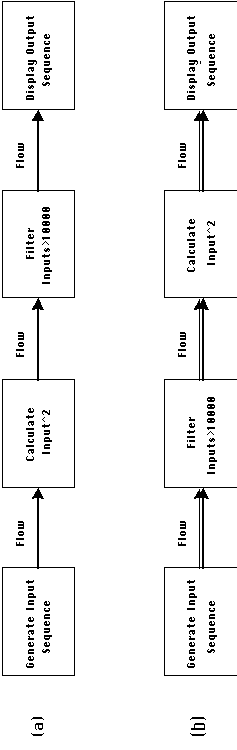
Figure 2-3: Interconnecting the same activities
in two different ways results in two different applications.
The purpose of this example is to demonstrate the equal importance
of activities and dependencies in determining the behavior of
an application. Figure 2-3 shows the architecture of two applications
where an identical set of activities has been interconnected in
two different ways. The behavior of the two applications is quite
different. Application (a) outputs the squares of all members
of its input sequence that are below 100 (since 1002
= 10000). Application (b) outputs the squares of all members of
its input sequence that are below 10000.
________________________________________________________________________
In conclusion, at the architectural level activities and dependencies
are two distinct elements of complex software applications. Both
are explicitly represented and both are equally important to the
definition of a system.
2.2 Implementation Languages Focus
on Components
Despite the equal status of activities and interdependencies in
informal descriptions of a software architecture, as design moves
closer to implementation, current design and programming tools
increasingly focus on components, leaving the description of interconnections
among components implicit, distributed, and often difficult to
identify. At the implementation level, software systems are sets
of source and executable modules in one or more programming languages.
Although modules come under a variety of names and flavors (procedures,
packages, objects, clusters etc.), they are all essentially abstractions
for components.
Traditional language mechanisms for specifying module interconnections
are essentially variations of the procedure call interface. They
specify input and output parameters, and in some cases, lists
of imported and exported procedures. They are not sufficient for
describing more complex interconnections that are commonplace
in today's software systems (for example, a distributed mutual
exclusion protocol). As a consequence, support for complex module
interconnections is either left implicit, relying on the semantics
of programming languages and operating systems, or is broken down
into fragments, and embedded within the modules themselves.
________________________________________________________________________
Example 2-3: Distribution of Component Interconnection Protocols
This example will demonstrate how protocols for implementing even
the simplest interconnection relationships, become fragmented
and distributed among several code modules when the system is
implemented in a conventional programming language.

Figure 2-4: Implementation languages distribute
support for component interconnection protocols among several
code modules.
Figure 2-4 shows the architecture and one implementation of a
simple application that generates, and then displays, a body of
text. Management of the single flow dependency requires a mechanism
for transporting the text from activity Generate Text to activity
Display Text. It also requires a mechanism for ensuring that activity
Display Text reads the text only after activity Generate Text
has written it. In this particular implementation we have chosen
to manage the flow dependency among the two application activities
using a sequential file. Component generate opens, writes and
closes the file, while component display opens, reads, and closes
the file. The main program passes the shared filename to both
components.
In this program, the management of a single data flow dependency
has been distributed to three different places. Procedures generate
and display each contain one part of the file transfer protocol
embedded in their code body. Less obviously, the management of
the read-after-write prerequisite assumption is being implicitly
managed by ordering the invocation of generate before that of
display in the (sequential) main program.
The distribution of even such a simple protocol in three different modules has the consequence that each of the resulting modules now contains certain implicit interconnection assumptions about other modules with which it will work together. For example, module display assumes that, by the time it begins execution, some other module will have written the data it needs to a file. When attempting to reuse display in a different context, these assumptions will quite often not hold. In those cases, the code of the module must be manually modified to match the interconnection assumptions that are valid in the new context.
________________________________________________________________________
A visual metaphor that might be useful in order to understand
the loss in expressive power as we move from architectural diagrams
to system implementations, is the separation of a 3-dimensional
image into its projections on a set of 2-dimensional planes. Let
us try to picture a software application as a set of black boxes,
each corresponding to a functional component. In 3-dimensional
space, black boxes are interconnected by 3-dimensional connectors,
which manage their interdependencies. This corresponds to the
architectural view of an application. Using this metaphor, the
lack of explicit support for representation of interconnections
at the implementation level corresponds to an inability to represent
the third dimension. Programs are thus like sets of 2-dimensional
planes. In this metaphor, planes correspond to code-level modules.
In order to map a 3-dimensional image into a set of planes, we
take its projection into each of the planes. At the end of the
process, each plane encodes a "core" functional component
but also contains the trace of an interconnection protocol embedded
in it (Figure 2-5 ).
Trying to understand a system by reading its code modules is equivalent
to trying to mentally reconstruct a 3-d image from its 2-d projections.
The separation of interconnections into a set of 2-dimensional
traces, blurs the ostensible function of each module and makes
global understanding of the interdependency patterns a nontrivial
mental exercise. Furthermore, as we shall see, it has negative
implications on the reusability of modules thus constructed.
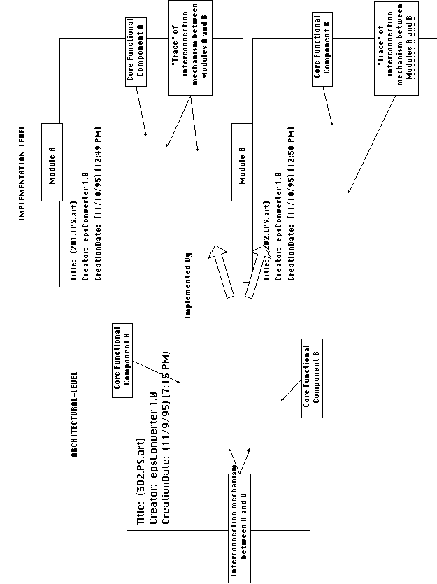
Figure 2-5: Moving from architectural diagrams
to system implementation is similar to projecting a 3-d image
onto a set of 2-d planes.
Several researchers [Shaw94a, Allen94] have identified this expressive
shortcoming of programming languages and systems and have discussed
its negative effects in developing and maintaining software systems.
This thesis makes the additional argument that the lack of explicit
support for representing component interdependencies and implementing
component interconnections separately from the components themselves,
is one of the principal causes for the difficulty of reusing software
components in new applications. The following sections will attempt
to make this argument more explicit.
2.3 Implicit Interconnection Assumptions
Pose Obstacles to Component Reuse
Implementation-level software modules (source or executable) are
the usual candidate units for software reuse. This section will
discuss why the current practice of ignoring the significance
of architectural interdependencies and embedding component interconnections
within components, increases the difficulty of reusing these components
in new applications.
As described in the previous section, components built with current
technologies make strong, and usually undocumented, assumptions
about their interdependencies and interconnections with other
components in the same application. More precisely, they contain
fragments of protocols that implement their interconnections with
the rest of the system in their original development environment.
Such assumptions are either hardwired into their interfaces, embedded
in their code bodies, or left implicit, relying or specific properties
of the environment for which they were originally designed.
Since interconnection relationships is one of the defining elements
of each individual application, different applications are expected
to contain different interconnection relationships. Therefore,
the interaction assumptions embedded inside a component will most
likely not match its interconnection patterns in the target application.
In order to ensure interoperability, the original assumptions
have to be identified, and subsequently replaced or bridged with
the valid assumptions for the target application. In many cases
this requires extensive code modifications or the writing of additional
coordination software (or "glue" code).
2.3.1 A Taxonomy of Interconnection
Assumptions
Since the problem of component composition is closely related
to that of managing component interconnection assumptions, it
is useful at this point to introduce a framework that characterizes
the various categories of interconnection assumptions encountered
in reusable software components. Our framework classifies assumptions
according to the following two dimensions:
a. The design level (specification, implementation) of the assumption
b. The location of the assumption in the component
With respect to their design level, interconnection assumptions
are classified into:
Protocol assumptions. These are implementation-level assumptions
which result from the fact that components encode parts of their
interconnection protocols into their bodies. For example, a producer
module which was originally designed as a UNIX filter contains
the writer part of the pipe protocol and assumes it will be interacting
with modules which encode the corresponding reader part of the
protocol.
Architectural assumptions. These are specification-level
equivalents of protocol assumptions. They can be expressed as
constraints on the patterns of allowed interconnection relationships
between a component and the rest of the system. Take, for example,
the previously mentioned producer module, implemented as a UNIX
filter. Since pipe protocols manage one-to-one flow dependencies
(each value written to a pipe can only be read once), that module
contains the architectural assumption that each of its values
will flow to a single consumer component. Architectural assumptions
are more difficult to identify than protocol assumptions, because
there exist no systematic frameworks for mapping interconnection
relationships to interconnection protocols, and vice-versa.
With respect to their location inside a component, interconnection
assumptions are classified into:
Interface assumptions. These are protocol and architectural
assumptions encoded into a module's parameter and import/export
interface. Let's consider a simple procedure call as an example.
Protocol assumptions are the most obvious: they include the names,
data types, and ordering of parameters it expects. However, procedure
interfaces also encode a set of implicit, architectural assumptions:
These include the fact that all input parameters are expected
to flow from a single place (the point of call), that all parameters
will be available when control flows into the procedure body,
and that output parameters flow to the same place that inputs
came from.
Assumptions embedded in the code. These assumptions relate to interconnection protocol fragments found in the code bodies of components and their associated dependency patterns. For example, a Dynamic Data Exchange (DDE) server module written for the Microsoft Windows environment, contains the server part of a DDE protocol embedded in its code. It assumes it will be interacting with DDE client components containing the corresponding client part of the protocol. From an architectural perspective, it assumes it will be connected to other components through many-to-one flow dependencies.
Implicit assumptions. These assumptions are manifested
by the absence of any particular mention in code and rely
instead on properties of the environment for which components
were originally designed. An example is a user interface event
loop, originally designed for an environment with preemptive scheduling.
It implicitly assumes it will be sharing the processor with all
other applications running in the system. Therefore, it does not
contain statements that periodically yield the processor. The
explicit addition of such statements would be required in environments
without
Figure 2-6: Architecture of a simple application and descriptions of candidate components for implementing its activities.
preemptive scheduling. Another example is a module which assumes
it will be the only writer of a file in the system and thus does
not contain any statements for locking the file. In order to use
the module in an environment with multiple concurrent file writers,
a file locking protocol must be introduced.
________________________________________________________________________
Example 2-4: Construction of a simple application from existing
components
The following example demonstrates how the difficulties of reusing
software components in new applications are a consequence of mismatches
between the original component interconnection assumptions and
the actual interdependency patterns of the target application.
Figure 2-6 shows the architecture of a simple market simulator
application. We wish to build the application using existing components,
whose interfaces and requirements are also summarized in the same
diagram.
The first important mismatch occurs at the inputs of activity
Estimate Profits. Procedure calcprof expects to receive both its
input parameters, via a procedure call (protocol assumption),
from a single place (architectural assumption). However, in this
application, it is connected to two different activities, each
of which passes its respective parameter to a different procedure.
Module gencost repeatedly calls procedure nextcost for each new
cost data item it generates. Likewise, module gendemand independently
calls procedure nextdemand for each new demand data item it generates.
Somehow the two values must be collected together and transmitted,
via a single procedure call, to calcprof. One way to achieve this
is to write one of the values to a global variable, and then read
that variable and call calcprof from inside the procedure to which
the other value has been passed. Such a scheme requires additional
coordination to ensure that (a) the global variable is not read
by the second procedure before it has been written by the first
procedure, and (b) that the first procedure does not overwrite
the variable before the second procedure has read and transmitted
each value.
The other mismatch occurs at the output of activity Estimate Profits.
Since calcprof writes its output values to a pipe, it implicitly
assumes (a) that there will be a pipe reader at the other end
(protocol assumption), and (b) that each value will be used by
a single consumer activity (architectural assumption). In this
example, however, two activities need to read each value. In order
for this to happen, additional software must be provided that
reads the pipe and makes each value available to both consumer
activities. In the case of activity Display results this involves
setting up a second pipe. In the case of activity Log results
a simple procedure call is sufficient.
________________________________________________________________________
We observe that, even in a simple system, the process of component
composition is not trivial. In more complex systems, carrying
out the above process might involve significant design effort,
to the extent that many designers prefer to build new applications
from scratch rather than reuse existing components they might
have at hand. Progress has been made in automating the handling
of some of the most "obvious" categories of protocol
assumption mismatches, such as interface assumptions. However,
up to this date, there has been little success in handling more
complex protocol assumptions, as well as in treating all different
sources of assumption mismatches under a unifying framework. Researchers
have only recently began to recognize the importance of architectural
assumption mismatches [Garlan95].
Step 1: | Identify original component assumptions Identify the interconnection assumptions of each component. |
Step 2: | Determine new patterns of interaction Determine the patterns of interconnection of each component with the rest of the system in the target application. |
Step 3: | Mediate component assumption mismatches Replace or mediate the original component assumptions in order to make them compatible with the patterns of interconnection in the target application. |
.
Figure 2-7: Conventional view of the process for
building software applications from existing components.
We claim that an important source of difficulties in this area is due to our failure to recognize component interconnection as a separate design problem, provide tools for visualizing component interdependencies, and separate support for component interactions from the implementation of a component's core function. Most designers ignore (or do not consciously take into account) the dimension of component interdependencies and view the process of component composition as an ad-hoc effort to bridge mismatches among components (see Figure 2-7). This view of the process results in a number of practical difficulties:
Difficulties in identifying component assumptions
Difficulties in determining new patterns of interaction
Difficulties in replacing or mediating component assumptions
The following sections elaborate on each of these difficulties.
2.3.2 Difficulties in Identifying Component
Assumptions
By not recognizing component interconnections as an explicit element
of software systems, current programming languages leave them
implicit and often not documented. Designers have to understand
or deduce them by reverse-engineering the code. As explained in
Section 2.3.1, relevant assumptions might be hidden in a variety
of places, including:
Module interfaces. Such assumptions include the names,
order and data type of input and output parameters, as well as
names and signatures of imported and exported modules. They are
the most obvious and easy to identify assumptions. Researchers
have developed special notations, called Module Interconnection
Languages (MILs), to facilitate this task (see Section 7.3.1).
Unfortunately, they don't tell the whole story.
Code blocks. Apart from procedure argument lists, there
is a large variety of other means of component interaction, ranging
from global variables, to complex interprocess communication protocols
requiring elaborate setup and maintenance. Each participating
component will contain fragments of those protocols embedded in
its code blocks. Although good program design is able to help
localize such fragments, nothing in today's languages actually
forces programmers to do so. In many cases, designers have to
read the entire code in order to identify them.
Implicit environmental properties. The most problematic
assumptions are those which are manifested by the absence of any
particular mention in code and rely instead on properties of the
environment for which components were originally designed. There
is no tangible documentation of such assumptions, except in program
comments. In the worst case, designers must rely on their experience,
intuition, and knowledge of the development environment of the
component.
2.3.3 Difficulties in Determining New
Patterns of Interaction
This is the step where the lack of support for explicit representation
and management of component interdependencies creates the most
problems. The interactions of components in the target application
result from the management of their interdependencies in the new
system. Designers need to understand those new patterns of interdependencies,
map them to appropriate coordination processes that manage them
and, finally, determine the pieces of those processes that are
associated with each component in the system. We see, therefore,
that this step should, in fact, decompose into three distinct
steps, and be supported by explicit representations of the target
application architecture and frameworks for mapping interdependency
patterns to coordination processes.
An additional complexity comes from the fact that interconnection
protocols typically deal with issues orthogonal to those of the
problem domain of an application, such as machine architectures,
operating system mechanisms and communication protocols. This
increases the expertise requirements from the part of the designer
and complicates the mental effort needed to mix those orthogonal
concerns in the same code unit.
2.3.4 Difficulties in Replacing or
Mediating Component Assumptions
Since original component assumptions might be encoded in a variety
of places, replacing or mediating them might require several modifications
within or around a component. Furthermore, since target coordination
processes typically define a set of "roles" to be integrated
with several interdependent components, this, again, usually results
in the need to perform several modifications distributed across
the system.
The previous difficulties can, again, be illustrated by the 3-d-to-2-d-transformation
metaphor of the component composition process (see Section 2.2).
The input to the process (a set of modules to reuse) corresponds
to a set of 2-d planes, each of which encodes a specific component,
but also contains the trace of interconnections of this component
in its original environment. The output of the process corresponds
to another set of 2-d planes (the input set with possibly some
new modules added). The process consists in modifying the input
planes, erasing or modifying the projection of original interconnection
protocols, so that at the end of the process it has become equal
to the equivalent projection of the target interconnection protocols.
The visual process is greatly facilitated by the existence of
an intermediate 3-d representation, picturing interconnection
relationships among components in the target application. Managing
application interdependencies with coordination processes and
decomposing processes into pieces associated with each component
is equivalent to projecting the new 3-d model onto the set of
2-d planes that represent the original modules. It would be very
hard to imagine the form of the new projections without recourse
to this 3-dimensional view.
The problem with current technologies is that they do not provide
support for the equivalent of a 3-d view of software systems,
nor a systematic way of projecting "3-dimensional" interconnection
protocols onto existing "2-dimensional" software modules.
Even if the inputs and outputs of the process are still modules
expressed in our current "2-dimensional" idioms, the
existence of an intermediate "3-dimensional" architectural
view and algorithms for performing the equivalent of a projection
of that view to "2-dimensional" modules, would greatly
facilitate the task of component composition.
2.4 Component Interdependencies Deserve
First-Class Status
The preceding discussion provides the motivation for the main
thesis of this work. We have shown that the complexity of the
process of constructing software applications from existing components
is a consequence of our failure to separate context-specific support
for component interconnections from the implementation of a component's
"core" functionality.
We define software interconnection to be the design problem
of:
(a) specifying the patterns of dependencies among activities in a software application
(b) selecting coordination processes to manage dependencies and
integrating the resulting interconnection protocols with the rest
of the system
This thesis argues that the problem of component interconnection
should be treated as an orthogonal design problem from
that of the specification and implementation of a component's
core function. We should begin to comprehend, represent and systematize
its design dimensions and design alternatives in a coherent framework.
Such a separation will provide benefits, not only for the initial
development, but also for the maintenance and portability of component-based
applications.
2.4.1 Requirements for Separating Interconnection
from Implementation
The proposed separation translates to a number of concrete requirements for new notations, tools and theories to support the process of component composition. These requirements relate directly to the discussion of the difficulties presented in the Section 2.3, and can be summarized as follows:
2.4.1.1 Make component assumptions
explicit
A full separation of the problem of component interconnection from that of component implementation would require us to design components with minimal interdependency assumptions. In actual practice such a requirement would limit the reuse of components developed with current technologies. It might also pose stringent constraints to the development of new components. A more relaxed requirement is to develop component description notations that help make interconnection assumptions explicit.
2.4.1.2 Separate and localize representations
of component interdependencies
We need to be able to represent component interdependencies separately from components and to localize interconnection protocols that manage them. This requires the development of architectural languages with separate abstractions for software activities, dependencies, and coordination processes. It also requires the development of a vocabulary for specifying common component interdependencies.
2.4.1.3 Develop systematic design
guidelines for component interconnection
We need systematic frameworks for selecting coordination processes
that manage application interdependencies. Such frameworks should
enumerate the design dimensions of the problem of component interconnection.
They should provide mappings from patterns of dependencies to
sets of alternative coordination processes for managing them.
Finally, they should provide compatibility criteria and design
rules for selecting among alternative design choices.
Step 1: | Specify target application architecture
Express the architecture of the target application as a set of activities interconnected through dependencies. |
Step 2: | Associate activities to code-level components
Locate and select existing code-level components that implement the core functionality of application activities. |
Step 3: | Manage target application interdependencies
Select coordination processes that manage target application interdependencies. |
Step 4: | Integrate components and coordination processes
Integrate code-level components and coordination processes into sets of executable modules. |
Figure 2-8: An improved approach for building
software applications from existing components.
2.4.2 Benefits from Separating Interconnection
from Implementation
If we are able to satisfy the above requirements, we can develop
improved processes for developing and maintaining software applications
out of existing software components. Such processes will center
around explicit, abstract descriptions of software applications
at the architectural level. Figure 2-8 gives a generic description
of such an approach and Figure 2-9 a schematic high-level diagram
of the transformations involved.
Successful implementations of such processes should be able to
offer the following practical benefits:
2.4.2.1 Benefits to initial application
development
Independent selection of components. Designers should be
able to select components to implement activities independently
of one another. Candidate software components need not conform
to any particular set of standards or assumptions. Any mismatches
will be handled by coordination processes.
Routine management of dependencies. Dependencies should
be routinely managed by coordination processes based on systematic
design frameworks. Depending on how successfully frameworks are
developed, the process of dependency management should be assisted,
or even be automated, by design tools.
Minimal or no need for user-written coordination code.
Technologies for mediating original component assumptions and
integrating components and coordination processes into sets of
executable modules should be able to generate new applications
with minimal, or no need for additional, user-written coordination
code.
2.4.2.2 Benefits to application
maintenance
Easy replacement of components with alternative implementations.
Designers often need to change the code-level components that
implement the functionality of specific activities, in order to
reflect changes in functional requirements, or to take advantage
of new, improved software products. Applications should be easily
reconstructed after such changes, by reusing the same architectural
diagram and simply managing again the dependencies of the affected
activities with the rest of the system.
Easy porting of applications to new configurations. When
applications are ported to a new environment, their abstract architecture
(activities and dependencies) remains unaffected. However, the
use of different coordination processes might be required. By
making the step of dependency management a routine one, it should
be easy to manage them again for the new environment and construct
a new application from the original architectural description
and functional components.
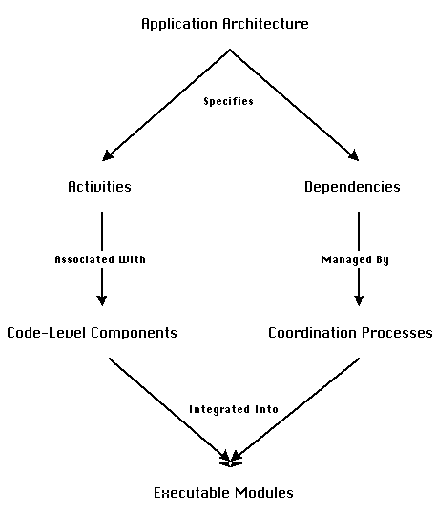
Figure 2-9: A schematic view of the proposed process
for building component-based applications.
Our objective in the rest of this thesis is to propose one concrete
implementation of the requirements presented in Section 2.4.1
and to demonstrate how they can be combined into a useful methodology
for component-based application development. The methodology is
based on the process sketched in Figure 2-9 and offers the practical
benefits outlined in Section 2.4.2. The end products of the work
include:
An architectural language (SYNOPSIS) for describing software applications,
with explicit support for activities, dependencies, and coordination
processes. Chapter 3 is devoted to a detailed description of SYNOPSIS.
A vocabulary of commonly encountered activity interdependencies
and a design space of associated coordination processes. Chapter
4 presents the vocabulary and design space.
An application development tool (SYNTHESIS) that allows designers
to enter architectural descriptions of applications and is able
to assist the process of generating execus systems by successive
semi-automatic specializations of their architecture.
Chapter 5 proposes one concrete implementation of the process
outlined in Figures 2-8 and 2-9. The design assistant component
of the SYNTHESIS system is based on that process. Finally, Chapter
6 presents a number of experiments that test and validate the
feasibility and usefulness of the entire approach.