
Some Preliminary Findings and Propositions
Michigan State University
University of California, Berkeley
Texas A&M
California State University, Pomona
Kansas State University
Please direct correspondence to:
Brian Pentland
School of Labor and Industrial Relations
4th floor, South Kedzie Hall
Michigan State University
E.Lansing, MI 48824-1032
Office: (517) 353-3905
FAX: (517) 355-7656
Abstract
A Process-based Alternative
Lexical Variety
METHODOLOGY
Site Descriptions
Reference Desk
Data Collection
Questionnaire
Measuring Lexical Variety
ANALYSIS AND FINDINGS
Task variety and analyzability
Reference Library
Lexical Variety: Process (verbs)
DISCUSSION
Some Theoretical Issues
CONCLUSION
Abstract
Routineness is a central concepts in organizational theory and design and is widely
understood as a product of low task variety and high task analyzability. Standardized
scales to measure these dimensions been developed and shown to be reliable, but
preliminary results reported here suggest the possibility that these scales may measure
routineness in the content of a task unit's work but not variety in the process.
Comparing results from the standard measures and detailed observational studies in three
task units, we discovered that work processes in the most "routinized" task
units (as measured by the standard scales) are more varied than in the less
"routinized" task unit. To help explain these findings, we introduce and
operationalize the concepts of lexical and sequential variety and use them to formulate
testable propositions. We also discuss the implications of this alternative view of
routines and routineness for issues such as organizaitonal learning, process redesign, and
mass customization.
There is a constant tension between routinization and customization in the design of work. Routinization has been the classic managerial strategy for increasing productivity, quality, and control in manufacturing, albeit at the cost of worker alienation and turnover (Stinchcombe, 1990; Leidner, 1993). In services, routinization offers similar advantages in terms of productivity and control, but an overly routinized service interaction may be perceived as low quality by customers who equate quality with customized, personalized service (Leidner, 1993). Even in manufacturing, there is increasing pressure to move away from mass production, which represents the ultimate routinization of work, towards increasingly flexible and customized production systems (Piore and Sabel, 1983; Pine, Victor, and Boynton, 1993).
The practical need for customization in both manufacturing and services creates an interesting set of questions for organization theorists. For example, how do we evaluate the "routineness" of task units that produce customized products or services in standardized ways? The issue here is essentially one of construct validity: what does the concept of "routineness" refer to, and how can it be measured? We have traditionally thought of routineness as a property of a task unit -- a collection of individuals within an organization performing a particular function or set of functions. This is the perspective advocated by Perrow (1967) and adopted throughout the literature on organization theory and design. This perspective leads us to see some task units as more routine than others and to measure these differences by asking task unit members to generalize about their work experiences.
In this paper, we argue that it is more natural and more fruitful to see routineness as a property of processes, defined as sequential patterns of action that occur in the context of constraining and enabling structures (Pentland and Rueter, 1994). This view leads us to see some processes as more routine than others. By explicitly considering the sequential structure of work processes, this perspective offers insights that are not possible with other methods. In particular, it allows us to separate the content of what a task unit does from the process through which it is accomplished. We believe this distinction is quite important in understanding the tension between customization and routinization, yet it is has been either ignored or confused in prior research.
In addition to developing the framework, we offer some tentative evidence that standard measures of routinization, based on task variety and analyzability of search (Lynch, 1974; Daft and Macintosh, 1981; Withey, Daft, and Cooper, 1983), are more strongly connected to the content of the work than to the sequence of actions, or process, with which the work is accomplished. Task units where work is reported to be relatively routine (low task variety and high analyzability of search) appear to have as much variety in their work processes as task units where work is less routine (high task variety and low analyzability of search). By failing to distinguish clearly between the content of what is produced and the process of how it is produced, measures based on Perrow's (1967) framework appear to be inadequate to capture the complexity work. The findings reported here are very preliminary, but the sequence-based perspective outlined here seems to offer some advantages over earlier methods for analyzing task unit routinization.
The paper has several objectives: to articulate a process-based framework for the analysis of task variety, to develop methods for operationalizing such a framework, and to articulate some theoretical propositions based on our preliminary findings. It should be seen as a preliminary effort, because this is a large agenda and we have taken only a few exploratory steps. We begin with a brief critique of the traditional perspective on task unit routinization based on Perrow (1967). We then introduce a new framework for analyzing task unit routinization which is based on the concepts of lexical and sequential variety. We then use these concepts to formulate some hypotheses concerning the relationship between lexical and sequential variety and traditional measures of routineness, such as task variety and analyzability. After presenting our research methods and preliminary findings, we discuss the implications of this approach for the concept of organizational routines, and for the analysis of flexibility and customization in both services and manufacturing. We also discuss the strengths and limitations of our methods and offer some suggestions for improvements in future research.
Since the publication of Perrow's (1967) framework, variables such as the number of exceptions (sometimes labeled as "task variety") and the analyzability of exceptions have been used to characterize the degree of routinization in a task unit (Lynch, 1974; Daft and Macintosh, 1981; Withey, Daft, and Cooper, 1983). These variables can then be correlated to other features of the work unit or its environment. Although Perrow's (1967) framework has been widely influential, it has a variety of difficulties. First, it conflates the content of the work (the task) with the process with which work is accomplished (the technology). The definition of what constitutes an "exception" is dependent on the work process used in the task unit; two different task units handling the same mix of raw materials or customer orders would experience different numbers of "exceptions" based on the technology in use. Consider the familiar fast-food example of Burger King versus McDonald's. If one asks them to "hold the pickles" at Burger King, it does not disrupt the production process because sandwiches as Burger King are generally "made to order" (except during rush periods, when a small inventory is usually created). At McDonald's, asking for a sandwich without pickles disrupts the production process and requires a long wait, because sandwiches are typically "built to inventory." Custom orders, no matter how mundane, are exceptions.
The conflation of process and content is equally apparent when we attempt to use Perrow's framework to describe task units that use the same technology, yet handle different levels of variety in their inputs or outputs. Again, restaurants make a familiar example: the same kitchen and cooking equipment can be used to prepare a large number of dishes or a small number of dishes (menus at some pizzerias and delicatessens often exemplify the combinitoric explosion that is possible with bread, meat, cheese and vegetables). Unless one advocates an absurdly strong form of technological determinism (i.e., that there is only one technology to accomplish a given task), then the separation of process from content is a necessary analytical step.
Second, the two key dimensions (number of exceptions and analyzability of search) are not independent. For example, if a new raw material is perceived as "unexceptional," then the search process required to handle it will be negligible. If that same raw material is perceived as "exceptional" (e.g., by a different task unit), then search will be required. If the search is truly perceived as analyzable, however, then there is a well understood procedure available to handle it and it no longer seems like an exception. In short, if a search space is analyzable, in the sense of having well-understood principles that govern its operations, it will not admit many exceptions. For this reason, the "off-diagonal" boxes of "high exceptions/high analyzability" and "low exceptions/low analyzability" do not make sense.
The underlying problem with Perrow's (1967) framework is that it attempts to describe a complex set of alternative processes in terms of two variables that describe the task unit. Work processes are inherently composed of sequences of steps or activities. These sequences and the steps that compose them may vary between task units, or they may vary from time to time within a given task unit. By summarizing sequential work process in terms of indicators like "numbers of exceptions" or "analyzability of search," organization theorists have abstracted away from the core phenomena. Furthermore, as operationalized in most research, these concepts depend on subjective self-reports from task unit members. Inexpensive, survey-based measures have been developed that are reasonably reliable (Withey, Daft, and Cooper, 1983), but given the difficulties with the underlying conceptual structure, however, it is not clear what these instruments are measuring.
To response to these shortcomings, we propose a framework that explicitly accounts for the sequential structure of work processes. This framework is based on the grammatical metaphor developed by Pentland (Pentland and Reuter, 1994; Pentland, 1995). Instead of attempting to summarize the properties of a task unit using abstract variables, we propose to examine the structure of the work process directly and in considerable detail. To do so, we introduce two concepts that are defined in the following paragraphs: lexical variety and sequential variety.
Lexical Variety. In a given work situation, there are a limited number of objects (or nouns) that members of a task unit typically encounter. For example, in a restaurant, there are a limited number of items on the menu. In a shoe store, there are a limited number of kinds of shoes. Categories of objects are a familiar topic in schema theory (Mervis and Rosch, 1981) and in the analysis of culture (Spradley, 1979). For a given sphere of activity (such as a task unit), there will be a limited semantic domain that can be mapped out which will capture all of the basic objects in that domain (Spradley, 1979). For example, in his ethnography of "urban nomads," Spradley (1970) maps out several semantic domains, including the parts of a jail and places to sleep. In the world of objects, the basic semantic domains are "parts of" (e.g., the parts of the body) and "kinds of" (e.g., the kinds of furniture).
One can also map domains of actions or verbs (Spradley, 1979; Jackendoff, 1983). For verbs, the most common semantic domains would be steps in a process (e.g., steps in buying a house) and means to an end (e.g., ways to skin a cat). Using these domains, one can create taxonomies of actions like those we commonly use for things. Pentland (1992) applied this approach to the analysis of actions in a software support hot line. He argued that in any given situation, there are a limited number of actions or moves available to the participants. For example, a salesperson can ask questions, suggest alternatives, and a variety of other tactics to help make a sale. Likewise, bill collectors employ a variety of standardized tactics to help convince people to pay (Sutton, 1991). These interactional moves are enabled and constrained by structural features of the situation, and they provide a lexicon from which participants in the situation construct performances.
The distinction between verbs and nouns can be used to operationalize the distinction
between process and content. A large lexicon of nouns suggests high content variety, while
a large lexicon of verbs suggests high process variety. Assuming that these concepts can
be operationalized, one can create a simple classification of task units based on these
simple characteristics as shown in Figure 1. This classification distinguishes between
task units where many different objects are handled in the same way (high content variety
and low process variety) and task units where similar objects can be handled in many
different ways (low content variety and high process variety). In a task unit with a large
content lexicon, workers would be able to handle a large number of different objects. In a
task unit with a large process lexicon, workers would be able to make a large number of
different moves. We might hypothesize that work perceived as more routine (using
traditional measures) would involve a smaller lexicon of moves than less routine work, as
well as a smaller lexicon of objects, as suggested by figure 1.
Figure 1: Two Kinds of Lexical Variety
Content (nouns) |
|||
| Process (verbs) | Few |
Many |
|
| Few | Routine |
||
| Many | Non-routine |
||
Sequential Variety. While this framework makes a helpful distinction between process and content, it still fails to incorporate any information about the structure of the work process itself. In particular, it fails to account for the many ways in which actions can be sequenced to create variations in work processes. Consider the difference between a sales situation where the interaction is highly scripted (Leidner, 1993) and a situation where the salesperson improvises in response to the customer; the lexicon would be similar, but the sequences would presumably differ. To capture this aspect of process variety, we ask how many different ways members of a given task unit can combine the moves available to them. That is, for a given lexicon of moves, is the sequence always the same, or can they vary it depending on the circumstance? We will refer to this dimension as sequential variety. Holding the content of the work constant (as reflected in the lexicon of nouns), one might expect that routine work is performed in more or less the same way all the time. This is the gist of the standard questionaire items used to measure task variety (see Appendix 1). This expectation can be operationalized in terms of sequential variety, Work perceived as more routine exhibits less sequential variety than less routine work.
These concepts allow us to propose some hypotheses concerning the relationship between
what subjects report as "routine" and the work they actually do. One could
undertake a variety of more substantive research questions, as well, and we will discuss
some of these later in the paper. At this early stage, however, we wanted to explore the
relationship between our new concepts and methods and some well established concepts and
methods from the literature. As suggested by the entries in Figure 2, one would expect a
clear connection between the degree of routinization of a work process and the size of the
lexicon, both in terms of actions and objects. In other words, people who perceive their
work as "routine" perform fewer actions and encounter fewer objects in the
process. There may also be differences in the number of distinct processes that occur
within a given task unit. In the examples that follow, we discovered that each task unit
we studied was responsible for multiple work processes. Again, one might hypothesize that
members of a task unit who perceive their work as "routine" may be responsible
for fewer distinct work processes.
Given that the purpose of this research was to develop concepts and methods, we were not especially concerned with explicitly testing any particular hypothesis. We believe such an effort would have been premature, since there are no measures of lexical or sequential variety in the literature. Rather, we attempted to gather sufficient data to refine our concepts and our methodology for future research. Towards this end, we selected a theoretical sample of three different task units: a university computer lab, a library reference desk, and a travel agency. These sites were chosen because: (1) they all involve repetitive, episodic, low involvement service interactions; (2) they are all "knowledge intensive", in the sense that they require a considerable amount of training or skill; and (3) they all involve a significant diagnostic or problem-solving component. At the same time, the setting, objectives, and clientele for each kind of work is quite different, allowing us to test the applicability of our framework to a range of settings. Furthermore, we hoped that these task units would reflect different levels of routinization based on traditional measures from the literature.
Reference Desk. The first site selected for this study is the reference desk at the University Research Library at UCLA. The research library, which we will refer to as URL, is the premier general purpose library of the university's library system. It is one of the largest in the country and is consistently ranked among the top 5 in the Association of Research Libraries (ranked second in 1990). It has over 6 million volumes and over 250,000 volumes are added yearly. The library system has almost 100,000 serials. The total staff exceeds 700 with a budget of over $32 Millions in 1989-1990. While there are a number of specialized libraries serving the needs of the professional schools such as Law, Medicine and Management, URL has a broader mission and serves the library needs of the university and the community at large. The reference function at URL plays a very visible role in the patrons perception about the general quality of the library. While users might have unpleasant experiences with the circulation department which has the duty of enforcing rules and regulations which often include fines, the reference librarian is still perceived to be on the patron's side.
The reference department has 8 librarians but only 7.4 FTE reflecting the less than full-time status of some librarians. Their experience ranges from 32 years for the department head to 3 years for a junior librarian. The average experience is 16.62 years with a standard deviation of 8.86 years. As many other organizations, the State University has been hard hit by the difficult economic conditions. The University library and the reference function at URL has not been exempt and has seen a steady increase in the workload combined with a hiring freeze. One way that the reference function has coped with these changes is the creation of 3 new para-professional library assistants positions. As the library assistants do not have degrees in librarianship, they receive training program to acquaint them with the basic library skills. Their skills are further honed through an informal apprenticeship during which they observe experienced librarians answer the patrons reference questions. Library assistants duties are twofold. They perform some of the administrative tasks that librarians have become burdened with due to staff shortages. At the same time, library assistants also work the reference desk during non-prime hours or during prime hours teaming up with experienced librarians. In 1992-93, URL reference librarians answered over 68,400 questions from patrons.
PC Labs. The second task unit included in the study was the student computer lab at a graduate business school. The computer labs are housed in two rooms, one of which is primarily for printing. Each lab has IBM and Macintosh computers. A variety of software is available for student use including word processing, spreadsheet programs, graphics packages, and statistical analysis software. In addition, students may access the business school and university mainframes from the labs. While the labs are open, a TA is usually present in each to answer any questions or help with any problems that arise.
There are thirteen TAs who cover the different shifts in the computer labs. Five of these have worked as TAs for less than two months. All of the TAs are students in the school and work only part time in the labs. TAs undergo no special training on the software and hardware available. Since they are all students in the school, the TAs generally are familiar with the equipment in the labs before they are hired. The lab supervisor attempts to hire TAs so that at least one TA is very familiar with each software package. Instructions to the TAs are given in a meeting each academic quarter. Any policy or procedure changes that occur at other times are dispensed through electronic mail. Since the TAs work only part time while attending school and do not intend to pursue this work as a career, most of them do not see themselves as professionals. The TAs do attempt to solve users' problems, but if a TA does not know the answer to a particular question, he or she will refer the user to another TA or a full time staff person.
The types of questions users ask TAs range from the mundane, such as changing a cartridge in a laser printer, to the unusual, such as aiding a student who wishes to scan in maps for a multi-media presentation. Two typical tasks involve helping a student who has lost a disk and assisting a student to format and print a document to meet specific requirements. When not actively helping users, the TAs spend most of their time at a TA computer station. Users who have a question usually approach the TA at the station. If the TA cannot solve the problem by making a quick suggestion, he goes to the users' computer where he either instructs the user, or sits at the keyboard and attempts to solve the problem, leaving when done. If the TA cannot find a solution, he may consult other users, another TA, or refer the user to a full time staff member.
Travel Agency. The third task unit was a travel agency that operates as an in-house corporate travel agency in the regional headquarters of a large, multi-national food company that we will call CACAO. This agency is linked not only with CACAO, but with a large midwestern travel agency (that we will call TRAVEL) through a joint venture. An employee from TRAVEL works in the CACAO office. She provides first-line supervision for the other agents, monitors the work flow, and performs quality control on all the bookings. Most of CACAO's work is done in the local agency, but when the workload is heavy, travel requests are faxed to a TRAVEL office in Ohio, and travel arrangements are made there. The local travel agents may later work on the same bookings, but travelers at CACAO are unaware that their requests have been processed at another site.
CACAO employees use information systems extensively in their work. The travel agents sit at computer terminals all day long and use an on-line booking system (SABRE) to perform much of their work. TRAVEL also provides them with on-line scripts that import information from the CACAO database, and are designed to make the booking process simpler and more efficient. A local-area-network connects the personal computers that the travel agents use, so that they may bring up the same records out of their database. In addition, the ticketing information is sent to another site in California, where accounting information is processed and returned to CACAO in the form of reports.
CACAO has 7 employees. The head of the agency also is responsible for planning corporate events, so that most of the first-line supervision is done by the TRAVEL employee. One agent is responsible for international books, two for domestic ones, and others handle administrative jobs, such as financial reports and printing and issuing tickets. The agency head does not consider it to be a particularly high-pressure agency, but the agents find the work stressful, particularly during peak periods. The agents sit at their computer terminals and work steadily all day long.
Three methods of data collection were used at each site: a questionnaire, ethnographic interviews (Spradley, 1979), and structured observation (Adler and Adler, 1994). These data collection methods are summarized in Table 1 and discussed in the following sections.
Table 1: Data Collection Summary
Task Unit |
Questionnaire |
Number of |
Interactions |
Reference Desk |
9 |
5 |
59 |
PC Lab |
6 |
2 |
32 |
Travel Agent |
7 |
2 |
47 |
Questionnaire. For each of these task units, we wanted to establish a baseline measure of routineness. To do so, we prepared a brief questionnaire to measure task variety and task analyzability using standardized scales from the literature (Withey, Daft, and Cooper, 1983). The specific items used in the survey instruments are given in Appendix A. All members of each task unit were given the survey to complete, and nearly every member of each task unit returned a completed survey. As expected, an analysis of the responses indicated that both scales were reasonably reliable (a > .75).
Interviews. To begin developing measures of lexical variety, we employed Spradley's (1979) technique of domain analysis. Using a combination of ethnographic interviews and direct observation, we identified a lexicon of moves for each site (Pentland, 1992). The objective was to identify the domain of "steps in" the work of each task unit so that the actual work processes could be coded in these terms. We specifically chose to adopt an ethnographic approach and develop the coding scheme in "native" terms, rather than imposing our own lexicon. This decision has implications for the comparability of the data across sites, as we will discuss below.
We identified experienced members in each task unit who would be familiar with all aspects of the work process. Initial interviews with each informant lasted between one and two hours. Following Spradley's (1979) recommendations, interviews began with "grand tour" questions, followed by more specific questions designed to elicit the domains of interest. For example, at the travel agent, "Tell me about a typical service request," and later, "What steps would you take to complete an airline reservation?" To help validate the interview data, we undertook some initial observations at each site. In most cases, some additional activities cropped up that informants had neglected to mention. These were added to the coding scheme to help complete the semantic domain.
In addition, members of the research team compared lexicons across sites to identify commonalities or differences. These discussions helped fill in the domain at each site, as well as contributing to a common understanding for the observational data collection. The final version of the domain was reviewed by informants at each site for completeness and accuracy, but no formal confirmatory methods were used to test the contrasts between the categories.
Observations. Once we had refined our coding scheme, as described above, we engaged in additional observations of work in progress at each site. The purpose of these observations was to collect data on the frequency with which various activities occurred and the sequences in which they occurred. These data form the primary basis for estimating the lexical and sequential variety of the work process at each site.
To perform these observations, a set of coding forms was prepared for each site. The sheets included the lexicon of moves for the service provider as well as for the client1. The coding forms were designed to facilitate capturing the flow of action as it occurred. The forms were like spreadsheets, where the rows designated categories of action and the columns designated successive moments in time. By simply marking an X in the appropriate row and column, the observer could capture the sequence of interaction. Each interaction was coded on a single sheet and later transcribed into strings of codes for analysis. The number of interactions observed at each site is shown in Table 1.
A major limitation of this approach is that coding interactions in real time, on the fly, is difficult. While developing the coding forms, we attempted to assess the reliability of our coding schemes by using two observers and comparing results. As frequently happens in this kind of research, pairwise agreement on specific codes was low because a single missed or added code results in disagreement on subsequent codes in the sequence (Folger, Hewes and Poole, 1984). The coding forms greatly facilitated our work, and after repeated practice and refinement, we are confident that the general outline of each interaction is reasonably accurate. For more detailed analysis and hypothesis testing, however, we believe that videotaping or some other form of data collection that allows repeated viewing and coding of events may be necessary to overcome these problems. We considered the possibility of using videotape for this study but rejected it for a variety of reasons (i.e., permission, confidentiality, and cost).
The basic question in measuring lexical variety is simply, "how large is the lexicon?" This question can be addressed in a straightforward way by counting the number of entries resulting from a domain analysis, like counting the words in a dictionary. There are two difficulties in this approach. First, most of the words in the dictionary are used rarely, if ever. Given that most task units are specialized to some degree and typically espouse efficiency as a goal, one might expect a relatively small lexicon that is exercised regularly: objects or actions that are not used should eventually be discarded and forgotten. The extent to which this occurs in practice is an empirical question, of course. Second, and perhaps more important, words cluster in semantically related categories. Several words may mean approximately the same thing, or may all be instances of the same class. Thus, it is difficult to elicit and count exact numbers. In our study, we chose to rely on relative measures rather than exact counts.
Our answer to this problem is to analyze actual occurrences of the lexical items in question. In our data collection efforts, we focused on actions, but the same principle applies to objects as well. There are two measures of interest. First, how many different kinds of items were observed (in other words, how large is the dictionary in use)? Second, how far does the distribution of items deviate from the uniform distribution? Consider two task units in which ten kinds of moves were observed. Imagine that in one unit, 90% of the moves were of one kind; in the other, they were distributed evenly. Intuitively, the former is less varied than the latter, and statistically, a random sample of moves from the first unit is less likely to reflect the full lexicon. 2
A more challenging problem in measuring lexical variety has to do with the level of abstraction used to code lexical items. What level of "granularity" is appropriate? In principle, actions can be decomposed into tinier and less meaningful micro-actions (Abell, 1987). We adopted the concept of "moves" (Goffman, 1981; Pentland, 1992) to help keep the units of analysis socially meaningful. However, the problem of abstraction remains and it has a direct effect on two important issues. First, if moves are represented in finer grained detail, there will be more of them -- the task unit will appear to have more variety, when it is really an artifact of the coding scheme used by the observer. Second, two sites may appear more or less comparable based on the level of granularity. Most service organizations have some capacity for "escalating" problems, for example, but this similarity might be obscured by the variety of ways in which they accomplish this move. Thus, the level of abstraction in the coding scheme is a critical feature of the efficacy of the overall approach.
Conceptually, measuring sequential variety is straightforward: how similar (or different) are the set of observed sequences of action in a given task unit? To operationalize this question, we need some measure of distance between two sequences that may vary in length. This problem has been addressed using a technique called optimal string matching (Sankoff & Kruskal, 1983; Abbott & Hrycak, 1990; Sabherwal & Robey, 1993). String matching is a technique that has been used extensively in molecular biology to compare protein sequences, and has also been applied to speech recognition and other topics where two sequences of unequal length must be compared. It has the important advantage that it makes no particular assumptions about the statistical properties of the data used as input; it simply computes a distance measure. Recently, the technique has been applied to the analysis of sequential data in the social sciences, such as the careers of musicians (Abbott & Hrycak, 1990), the formation of professions (Abbott, 1991), and the systems implementation process (Sabherwal & Robey, 1993).
Conceptually, string matching is quite simple. String matching programs compute the distance between two strings by counting up the number of operations needed to transform one string into the other. The operations typically include substituting one element for another, or inserting or deleting elements. Each operation has a cost, and the distance between the strings is simply the total cost. The technique is called "optimal" string matching because it is designed to find the lowest cost set of operations to accomplish the transformation, thus insuring that the computed distances are unique and well-behaved (e.g., they obey the triangle inequality: d(A,B) + d(B,C) >= d(A,C)). Distances computed in this way are called Levenshtein distances (Sankoff & Kruskal, 1983).
Since our objective is to estimate the amount of variation in a set of sequences, we needed to compute the distance between each sequence and every other sequence. The result is a lower right triangular matrix (like a correlation matrix) whose elements are the Levenshtein distances between the strings. This matrix can be normalized for use as input to a clustering procedure, as in Sabherwal & Robey (1993) and Abbott & Hrycak (1990). In our case, we were more interested in the overall degree of dispersion or variety among the sequences. If the sequences were all identical, then all elements of the matrix would be zero. If the sequences diverged from each other in a single element (e.g., "aaa", "aba", "aab", "baa"), then the matrix would be filled with ones. As the differences between the sequences become more pronounced, the distances in the matrix increase. Thus, a convenient and meaningful measure of the sequential variety in the strings is simply the average size of distances in the matrix.
An important factor in the distance computation is the cost assigned to insertion, deletion, and substitution operations. In our computations, we set all of these costs equal to one. We did not have a strong rationale for imposing a different cost structure, and the literature suggests that the outcomes of string matching procedures are relatively robust to perturbations in the cost structure (Abbott & Hrycak, 1990; Sabherwal & Robey, 1993). Unlike some previous applications of this method to organizational phenomena, we chose not to normalize our distance computations in any way. As a result, longer sequences add directly to the overall measure.
These average distance measures are comparable across sites because the computation of the distances does not depend on the details of the lexicon. For example, the distance between "xxx" and "xxy" is equal to the distance between "aaa" and "aab". This property makes it appropriate to use the average distance for comparison purposes. Unfortunately, it is inappropriate to apply normal parametric statistics (e.g., t-test or ANOVA) to these data because the observations are not independent. Each sequence is compared to all of its siblings and thus influences N-1 of the distance observations.
Our findings consist of three sections. First, we report on the results of the survey we used to measure task variety and task analyzability in each site. These results establish the traditional interpretation of the degree of routinization in each task unit. We then report our findings concerning lexical and sequential variety in each site.
Task variety and analyzability
Table 2 summarizes the results of the survey based measures of task variety and task
analyzability at each task unit. The cells in Table 2 contain the average for each task
unit, and the standard deviations in parentheses. Although the number of respondents in
each task unit was quite low, a one-way analysis of variance on each of the two measures
shows that the differences between task units are statistically significant.
Table 2: Task variety and analyzability by site
|
Task |
Task |
Reference Desk |
4.28 |
5.37 |
PC Lab |
3.23 |
4.23 |
Travel Agent |
2.24 |
6.09 |
SS Between |
16.41 |
11.20 |
SS Within |
15.39 |
13.06 |
F-statistic |
10.13 |
8.15 |
p-value |
0.001 |
0.003 |
The reference librarians reported the highest task variety (4.28 on a seven point scale), the travel agents reported the lowest (2.24), and the PC lab falls in the middle (3.23). In terms of task analyzability, the reference librarians also reported that their work is less analyzable than the travel agents. Given the highly ambiguous nature of the technology in the PC Lab (and the comparative lack of professional culture or strict organizational controls to guide their activities), it is not surprising that workers in the PC lab reported that their work was the least analyzable. If we interpret these findings in terms of traditional organization theory, we would be forced to conclude that the work processes in the travel agent are more routine than those at the reference desk or the PC lab.
There are several ways to describe the content of a task units work. One can categorize the kinds of service requests that emerged from our interviews and observations of each task unit. The number of kinds of service requests characterizes the variety of the work from a functional perspective. In other words, it answers the question, "how many different kinds of things do you do here?" Another way to characterize the variety in content of a task unit's work is, as discussed above, is to enumerate the kinds of objects with which the task unit works. This analysis would address the question, "how many different kinds of things do you handle here?" In this section, we describe each of the task units in both of these ways. The findings are summarized in table 3, which indicates that the reference librarians see themselves as having the largest number of kinds of tasks (five) and the largest number of objects (all manner of books, journals, references, computer-based resources, etc., covering nearly any aspect of human knowledge not delegated to one of the professional school libraries, such as law, medicine or engineering). By comparison, the travel agents deal deal with a much more restricted set of objects: airline seats, rental cars, and hotels.
Table 3: Lexical variety at each task unit
Number of Tasks |
Relative size of lexicon |
|
| Reference Desk | 5 |
High |
| PC Lab | 2 |
Medium |
| Travel Agent | 3 |
Low |
Reference Library. While at the reference desk, reference librarians handle several different kinds of questions and service requests. The first and often the quickest questions are library information questions. In such questions the patrons asks the reference librarian a library related question such as the location of a library item such as a book or a service such as photocopying equipment. Under this category we also saw the general library information questions that deal with the lending and eligibility policies or the hours of operation. Typical informational questions are short and to the point, as in this example:
Q1: Where can I find a current local newspaper?
A1: In the reading room to your left
A second type of interaction is the reference material transaction. This category covers checking out or returning items housed in the reference desk core collection and Inter-library loan items. It is very similar to the standard check-in and check-out procedures for the library as a whole, except that it is done without the bar-code scanning system.
The last three types of interactions between reference librarians are more conventional reference questions that are loosely distinguished by their degree of complexity or open-endedness. Each of these type of questions are different enough to warrant a different sequence of steps in the interaction. The first type of reference question is the "known" or standard question. Such questions are usually specific and have been asked frequently enough that the reference librarian either knows about the answer or knows where to find the answer, as in:
Q:" I am writing a paper on Uganda's international trade and I need the latest published data on the volume and type of imports and exports.
A: " The World Bank publishes an annual report that would include this type of data, let me find you the call number."
General reference questions are more open ended, as in the case of a patron who wants to learn about mining. This type of question requires an extensive reference interview by the librarian to determine what and how much information the patron really needs and match it to the appropriate reference sources. While a patron might ask the reference librarian for a good book on French literature a reference interview might yield that the patron is in fact looking for the text of "La Chanson de Roland".
The final type of question is the complex reference question. In such cases, the patron has a specific question that requires some research by the librarian. A typical question would be "I am looking for a critique on Antigone in French". This type of question is characterized by iterative computer searches and confirmation requests from the librarians.
It should be clear from this brief discussion, however, that while the kinds of questions are few in number, the topics of these questions are nearly limitless. If one were to attempt to map out the lexical domain of a reference librarian, one would step quickly into very deep water. In fact, it is difficult to imagine an occupational group that, by virtue of daily contact with researchers and students from a wide variety of academic disciplines, deals with a broader range of topics. While we did not undertake this analysis explicitly, we would expect that other university library specializing in medicine, law, or engineering would probably engage in a narrow range of topics.
PC Labs. There are two basic kinds of work activities in the PC Labs. The first kind concerns the replenishment of supplies, mainly in the printing room. TAs are responsible for keeping paper and toner in the printers. This aspect of the work is relatively straightforward; the TA retrieves paper, toner or other supplies from the cabinet and then uses them to replenish the particular piece of equipment in question.
The second kind of work involves helping students with software problems. These questions are much more open ended; some are very short, while others can go on for nearly an hour. Software problems are potentially very difficult to diagnose and repair, even in apparently simple circumstances (Pentland, 1992). Also, the TAs are subject to frequent interruptions from other students looking for help. The problem solving is sometimes collaborative, where the student and the TA work together to achieve the desired results, while at other times, the TA takes a more directive role and tells the student what to do, or simply does it for the student.
The content of these questions is limited, to a large extent, by the kinds of software that are in use by students in the labs. This is influenced, in turn, by the kinds of software provided by the local area network that connects the machines in the lab. The lexicon of nouns the PC Lab consists mainly of two kinds of computer operating systems (Macintosh and Windows), a few word processing, spreadsheet, and presentation products, an electronic mail system used at the school, and a few specialized applications used in specific courses. And as mentioned above, students primarily need help with formatting and printing. Students who bring in other software are largely on their own. For this reason, it seems reasonable to conclude that the lexicon of nouns in use at the PC Labs would be smaller than at the reference library, for example.
Travel Agency. Three kinds of work predominate at the travel agency. The first is making new bookings, which can include airplane, hotel and rental car arrangements. Travel agents have a very concrete idea of the steps in a new booking, and these steps coincide with the steps in their on-line information system. However, the interaction between agent and traveler is often far from routine. Travelers may make their own arrangements, and then ask the agent to ticket them, which greatly complicates their work. Travelers also may not be ready to accept the least expensive alternative, because they want to arrange trips to meet personal requirements, such as visiting relatives or taking advantage of frequent flyer or frequent guest plans. Furthermore, new bookings sometimes include multiple destinations and multiple parties traveling, which can complicate the work process. Although the travel agents were quite definite about the steps followed in new booking, they rarely followed those steps in the order described.
Informational travel questions are another large segment of the requests that come in. Travelers often call to find out about weather, availability of accommodations, options for ground transportation, or other travel information questions. Travelers may need to know, for example, how far their hotel is from their meeting site. They may need such information before making a booking or after. These kinds of questions may or may not require the use of the on-line reservation system.
Finally, confirmation and changing existing bookings are a common kind of service request at the travel agent. Altered schedules are the norm rather than the exception, as crises occur and meeting times change. Unlike a new booking, where all the travel information must be accumulated and alternatives explored, confirmations and changes are much more narrowly focused. Thus, while the work entails a similar lexicon of moves as a new booking, they would not all need to be used in making a change or a confirmation.
In considering the lexical variety of travel agent work, we are faced with an interesting dilemma. Travel agents basically deal with three kinds of bookings: planes, hotels, and cars. But within that extremely limited lexicon of possibilities, they have access to a huge number of destinations. This illustrates the importance of choosing the appropriate level of abstraction to compare across sites. On one hand, travel agents have an extremely circumscribed lexicon of activities (like the menu at a ball-park hot-dog stand). On the other hands, there is a huge variety of destinations, dates, times, and classes of service. There is some evidence that because of the computerized reservation systems in use at TRAVEL, the staff tend to view airline bookings as more or less equivalent, regardless of destination. The exception to this is Southwest Airlines, whose flights were not fully indexed on the reservation system at the time of this research (i.e., travel agents had to call to get seat assignments). It would be difficult to confirm this without more detailed analysis, but to the extent that this observation applies to other kinds of bookings, then the lexical content of the travel agents' work is very limited indeed.
Lexical Variety: Process (verbs)
The variety of moves observed at each site is shown in figure 2 as a set of histograms of the relative number of moves observed for each site. The bars in each histogram represent percentages of the number of moves at each site. Note that at each site, there are several kinds of moves that are used frequently (the tall bars at the left) and a number of moves that are used less frequently.
Figure 2: Distribution of moves observed at each site


The kinds of moves involved will be discussed in more detail below; what is important to note here is the difference in variety between sites. The reference desk has the least varied lexicon (18 moves), the travel agency had the most varied lexicon (51 moves), while the PC lab fell in between (32 moves). This finding is in reverse order from what we would expect based on the standard measure of task variety. If lexical variety corresponds to traditional measures of task variety, then the library should have the most varied lexicon, but it does not. The task unit that reported the most routine work, the travel agency, has the most varied lexicon of moves.
The observed lexicon of moves provides an interesting basis for comparing the work in each site. Figure 3 (see next page) shows the relative frequency of moves observed at each site, grouped into a set of 12 categories that reflect some theoretically interesting aspects of knowledge-based service work. These integrate the service aspect of managing the interaction and the problem-solving and information processing aspects of the work. The categories include interaction control (starting, stopping, interrupting, walking around, etc.), defining the problem, search for information, trying a solution, providing information to the customer, recording information (e.g., in a computer system), conveying materials to others, referring a request elsewhere, escalating a request, giving up, authorizing some aspect of the service, and denying service.
Comparisons between sites, as shown in figure 4, tend to reinforce the validity of our observations because they generally confirm our qualitative sense of how the work in each site differs. For example, the TAs in the PC lab spent the largest fraction of their work on interaction control. This makes sense, because they were frequently interrupted and had to move around the lab to look at problems, etc. The librarians also had a considerable amount of interaction control, but they were protected from interruptions by a first-come, first-served queuing system that was rigorously observed.
Figure 3: Relative frequency of moves at each site
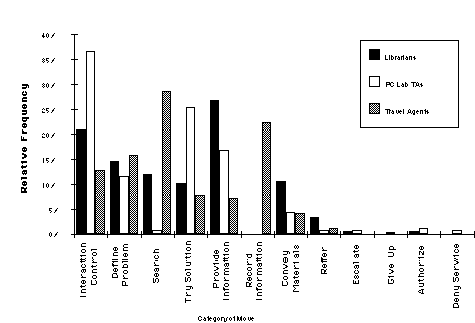
The groups spent approximately equal amounts of effort on defining problems (e.g., clarifying what it is that the customer wants). There are striking differences, however, in the way that this information was subsequently used. The travel agents and the librarians engaged in extensive search (defined as looking up possibilities or alternatives on-line or in reference books). The workers in the PC lab, however, practically never engaged in any kind of formal search. Rather, they would dive in and start attempting solutions. This can be considered an alternative form of search, which is practical for PC support but not for the other task units. It is difficult to imagine a librarian leading an inquisitive patron around the stacks, pulling books off the shelf and asking, "is this what you had in mind?" Because of the physical constraints of the situation, the kind of search that is appropriate for each task unit is quite different.
It was not surprising to find that the reference librarians devoted the largest fraction of their effort to providing information, followed by the PC labs and then the travel agents. This is the primary function of the reference desk. It also makes sense that the librarians and the PC lab would not engage in recording information (that is, entering information into a database, filling out forms, etc.) For the travel agents, however, this is a significant portion of their work, nearly equal in frequency to the search work. Of the three groups, the reference librarians devoted the largest fraction of their work to conveying materials (either to or from) their clients. This was due primarily to their function as the conduit for inter-library loan requests.
The remaining categories involve moves that define, in practice, the boundaries of the work unit and the services provided, such as refering clients elsewhere, escalating problems to management, and so on (Pentland, 1992). It is interesting to observe that these moves comprise a very small fraction of the work in all three of the sites. Only the reference librarians engaged in a significant level of referrals, which again makes sense given the nature of their work. In general, most of the clients at all three sites were entitled to service and could be helped.
Our findings on the sequential variety of the work in each site are summarized in Table 4. To gain a better grasp of how the work varied in each site, we have broken down the results by the kind of service request, as described above. This table shows the mean and standard deviation (in parentheses) of the Levenshtein distances between the sequences observed at each site. Thus, in row one, we find that the average distance between 13 library information questions at the Reference Library was 3.24 (using site specific codes) and 1.80 (using a common set of codes).
We report these distances based on both the site-specific coding schemes (as shown in
Figure 2) and the common set of codes (as shown in Figure 3). The mapping between these
coding schemes is given in Appendix B. We computed the distance both ways because the size
of the lexicon will tend to affect the apparent distance between the sequences; sites with
a larger lexicon, such as the travel agent, will appear to have more sequential variety.
To correct for this problem, we computed the distances based on a common set of codes.
Note that the use of a smaller lexicon does indeed reduce the apparent sequential variety
in each line of Table 4. This makes sense, because recoding to a common lexicon has the
effect of collapsing several categories into one. On average, it should take fewer
substitutions to transform one string into another. It is reassuring, therefore, that the
relative ranking of each site is unchanged by the recoding. Thus, we will discuss the
findings in terms of the common codes.
Table 4: Sequential Variety by Site and Kind of Work
Reference Library |
|
Sequential Variety |
Sequential Variety |
| Library information questions | 13 |
3.24 |
1.8 |
| Reference material transactions | 10 |
2.42 |
2.28 |
| Standard reference questions | 9 |
1.67 |
1.53 |
| General reference questions | 13 |
4.27 |
3.90 |
| Complex reference question | 14 |
7.33 |
6.35 |
| Reference Library Overall | 59 |
5.05 |
4.54 |
| PC Labs | |||
| Supply problems | 14 |
4.71 |
4.16 |
| Software problems | 18 |
8.45 |
7.46 |
| PC Labs Overall | 32 |
7.43 |
6.73 |
| Travel Agent | |||
| New Bookings | 9 |
19.00 |
13.42 |
| Travel information questions | 26 |
4.00 |
3.32 |
| Confirmation of booking | 12 |
7.97 |
7.17 |
| Travel Agent Overall | 47 |
9.87 |
9.09 |
Contrary to our expectations, the reference librarians did not exhibit the highest sequential variety in their work process. Rather, they had the lowest overall variety (4.54), and the travel agents had the highest (9.09), with the PC Labs falling in the middle (6.73). 3 The validity of this overall finding is reinforced by a comparison of the sequential variety of work within each site. In the library, for example, the sequential variety increases with the complexity of the question; standard questions are the least varied (1.53), while complex reference questions are the most varied (6.35). Likewise, at the PC labs, the supply problems are the least varied (4.16) and the software problems are more varied (7.46). At the travel agent, we find that new bookings are the most varied (13.42), while confirmation are less varied (7.17) and information questions are the least varied (3.32). Thus, in comparative terms, it seems like our measure of sequential variety captures some important features of the work within each site.
This makes the overall comparison between the sites all the more striking. It is
interesting to note that the standard reference questions and the reference material
transactions at the library are the least varied kinds of work at all three sites. The
informational questions at the travel agent are roughly similar in variety to the general
reference questions at the library. The work process with the highest variety, according
to our measure, was new bookings at a travel agent (19.00). The size of this number is
influenced by a small number of new bookings that were particularly long and involved.
These kinds of work sequences are a meaningful part of the data, however, and legitimately
contribute to the overall findings.
The data reported here raise some interesting questions concerning the relationship between traditional measures of task variety and task analyzability and our new constructs, lexical and sequential variety. Table 5 summarizes the findings for all three sites by ranking each site on each of the measures reported in this paper.
Table 5: Summary of findings
|
|
Task |
Lexical |
Lexical |
|
Ref.Desk |
H |
M |
H |
L |
L |
PC Labs |
M |
L |
M |
M |
M |
Travel Agent |
L |
H |
L |
H |
H |
One proposition that can be drawn from this summary table is that traditional measures of task variety and analyzability have more to do with the content of work than with the process of the work. That is, these measures seem to correspond in rank order to the lexical variety of the content of the work in each task unit. Although we did not undertake a rigorous operationalization of the lexical variety of work in each site, our observations and interviews suggest that these qualitative rankings are reasonable. This suggests that when people are asked questions about their work that seemingly refer to the work process (as in Appendix A), they tend to respond in terms of the content of what they do, not the process of how they do it. Thus, reference librarians handle a huge number of different requests in the course of their work, but the details of how they go about handling these requests do not vary much from instance to instance. Travel agents, on the other hand, mainly handle requests for three kinds of things: air travel, rental cars, and hotels. Yet they apparently go about handling these requests in a wide variety of specific ways. It is important to emphasize that these findings are based on too small a sample to be broadly generalized. But at the very least, they suggest a possible construct validity problem with measurement of "task variety" using conventional, survey based methods. It is also interesting to consider the implications of such findings if they are borne out in studies with larger samples and more rigorous methods of data collection.
One important function of the framework proposed here is to explicitly separate work content (what is produced) from work process (how it is produced). This distinction is critical if one hopes to understand analogies between work processes (Malone, Crowston, Lee and Pentland, 1993). If one asks, for example, how is a bank like a manufacturing organization (the guiding metaphor in John Reed's famous re-design of the back office at CitiBank), one must be able to make this separation.
One important theoretical implication of this research concerns our understanding of flexibility and adaptation. Increased flexibility within a task unit should also imply greater lexical and sequential variety. Adaptation should show up as changes in the lexicon or in the set of sequences produced (Pentland, 1995). We need to be mindful, however, of the distinction between process and content. Flexibility (and the closely related notion of adaptability) are intuitively connected to the content of work: how many different kinds of products or services can be provided, for example. The question we need to ask, we would argue, is how this is related to flexibility of work processes. It is quite possible that work processes may vary widely, appearing to be highly flexible (as in the case of the travel agent) without any meaningful ability to produce different kinds of goods or services.
There are a range of interesting questions that one can pose about lexical and sequential variety in task units. By now, the reader should have some intuition for what these constructs mean and how they might relate to more familiar ideas from organizational behavior. For example, we would expect that higher division of labor and increasing specialization would lead to lower lexical and sequential variety in each job description. As jobs become narrower, the actions required to accomplish them and the range of ways in which they can be accomplished should also be reduced. Conversely, we might expect that jobs that had been "reskilled" or "empowered" might exhibit a larger lexical and sequential variety than jobs that had not. In this usage, however, we have shifted the unit of analysis from the task unit to the specific job. In the data reported here, this distinction was not important because there was no significant division of labor among individuals. The same general ideas, however, can be applied to any part of a task units' work flow or work process.
A related question concerns the role of the customer or client in the analysis. More generally, one must ask how to bound the "membership" of the unit of analysis from a process point of view. Should a customer's actions, for example, be included as part of the lexical variety in a task unit? What about the suppliers' actions in a manufacturing process? On what basis can we assign some actions to the lexicon being analyzed and exclude others. In our study, we chose to exclude customer actions from the analysis. But we could easily have included them. Doing so would make sense because customers are often deeply involved in providing their own service (looking up their own books, solving their own problems, booking their own flights). For this reason, it is difficult to identify clear boundaries on a process that make both practical and analytical sense.
The concepts of lexical and sequential variety pose a number of interesting methodological challenges. The most important, perhaps, is how to get reliable data cheaply. The most reliable results can be obtained using video-taped data, but this approach is expensive and would seem to limit the possible applications of the concepts to a rather narrow range of settings where videotaping is possible. Alternatively, one can engage in direct observations of the kind reported here, but this approach makes it difficult to achieve high reliability (Folger, Hewes & Poole, 1984). As work processes increasingly become supported by work flow automation, of course, there will be an increasing possibility of using electronically generated data. Such an approach has obvious limitations, because the data would be filtered through a system that may or may not operationalize important theoretical constructs. Further, only a limited selection of sites would make such data available.
Another important methodological problem concerns the details of the domain analysis. In our study, we chose to record data using informants' natural categories, rather than imposing our own theoretically derived categories. To the extent that categories differ, this choice limits the comparability of data across sites, as discussed above. Yet, as shown in figure 3, we were able to group these categories together to create a meaningful comparison across sites. The answer to this problem depends, to a large extent, on the kind of research question under investigation. Theoretical categories are perfectly appropriate (and indeed, necessary) for a large range of questions.
Finally, it will be important to refine and extend our measures of lexical and sequential variety. At this point, we have an intuitive sense of how to compute measures that have a reasonable level of face validity and an intuitive connection to the constructs in question, but there is plenty of room for improvement.
The framework proposed here has implications for some areas of managerial practice, such as the design of automated systems to support work. While it is a truism that informal work practices rarely conform to official guidelines, there has been little attention to the issue of how to characterize these divergences. The notion of sequential variety starts to provide rigorous methodological handle on this issue. It can also provide some insight into what range of activities is actually being performed in a work unit. This kind of data is valuable input for a systems analysis and design.
Similarly, lexical and sequential variety provide a very concrete descriptive base from which to think about redesigning existing processes. Most process descriptions tend to be static -- as though work was accomplished the same way all the time. The concept of sequential variety directly challenges this view by calling attention to the innumerable ways in which work flow varies from instance to instance, even within supposedly highly routinized task units (e.g., the travel agent). Data of this kind may help alert process designers to potential problems in an existing process and signal a potential need for flexibility in the new process. All processes have variety, and the drive to be increasingly responsive to customer needs seems to encourage still more variety and customization. The practical question is not how to limit variety through increased controls, but how to design systems that foster "good" variety (that results in increased customer satisfaction, for example) and limit "bad" variety (that results in substandard performance).
In this paper, we have proposed a new, process-based framework for thinking about task
variety that builds on a linguistic metaphor for describing organizational processes. We
introduced the concepts of lexical and sequential variety and we have begun to explore
their relationship to traditional concepts of task variety and analyzability. The
question, in a sense, is how to describe the routines and routineness in task units in a
way that is theoretically valid and practically useful. We believe that the results
reported here make some tentative steps in that direction.
Abbott, A. (1991). A primer on sequence methods. Organization Science, 1(4), 375-392.
Abbott, A., & Hrycak, A. (1990). Measuring Resemblance in Sequence Data: An Optimal Matching Analysis of Musicians' Careers. American Journal of Sociology, 96(1), 144-185.
Adler, P. A., & Adler, P. (1994) Observational Techniques. In N. K. Denzin, & Y. S. Lincoln Eds.), Handbook of Qualitative Research: 377-392. Thousand Oaks, CA: Sage.
Ashforth, B. E., & Fried, Y. (1988). The Mindlessness of Organizational Behaviors. Human Relations, 41(4), 305-329.
Daft, R. L., & Macintosh, N. B. (1981). A Tentative Exploration into the Amount and Equivocality of Information Processing in Organizational Work Units. Administrative Science Quarterly, 26, 207-224.
Folger, J. P., Hewes, D. E., & Poole, M. S. (1984). Coding Social Interaction. In B. Dervin & M. J. Voight (Eds.), Progress in Communication Science, Volume IV (pp. 115-161). Norwood, NJ: Ablex.
Gersick, C. J., & Hackman, J. R. (1990). Habitual Routines in Task-Performing Groups. Organizational Behavior and Human Decision Processes, 47, 65-97.
Jackendoff, R. (1983). Semantics and Cognition. Cambridge, MA: MIT Press.
Leidner, R. (1993). Fast Food, Fast Talk: Service Work and the Routinization of Everyday Life. Berkeley: University of California Press.
Lynch, B. P. (1974). An Empirical Assessment of Perrow's Technology Construct. Administrative Science Quarterly, 19(3), 338-356.
Malone, T. W., Crowston, K., Lee, J., & Pentland, B. T. (1993). Tools for Inventing Organizations: Towards a Handbook of Organizational Processes. In Proceedings of the 2nd IEEE Workshop on Enabling Technologies Infrastructure for Collaborative Enterprises, . Morgantown, WV:
Mervis, C., & Rosch, E. (1981). Categorization of Natural Objects. Annual Review of Psychology, 32, 89-115.
Pentland, B. T. (1992). Organizing Moves Software Support Hot Lines. Administrative Science Quarterly, 37(4): 527-548.
Pentland, B. T. (1995). Grammatical Models of Organizational Processes. Organization Science, 6(5): 541-556.
Pentland, B. T. and Rueter, H. H. (1994). Organizational Routines as Grammars of Action, Administrative Science Quarterly, 39(3), 484-510.
Perrow, C. (1967). A Framework for the Comparative Analysis of Organizations. American Sociological Review, 32, 194-208.
Sabherwal, R., & Robey, D. (1993). An Empirical Taxonomy of Implementation Processes Based on Sequences of Events in Information System Development. Organization Science, 4(4), 548-576.
Sankoff, D., & Kruskal, J. B. (1983). Time Warps, Strings Edits, and Macromolecules: The Theory and Practice of Sequence Comparison. Reading, MA: Addison-Wesley.
Spradley, J. P. (1970). You Owe Yourself a Drunk: An Ethnography of Urban Nomads. Boston: Little Brown.
Spradley, J. P. (1979). The Ethnographic Interview. New York: Holt, Rinehart, Winston.
Stinchcombe, A. L. (1990). Information and Organizations. Berkeley: University of California Press.
Sutton, R. I. (1991). Maintaining Norms About Expressed Emotions - The Case Of Bill Collectors. Administrative Science Quarterly, 36(2), 245-268.
Withey, M., Daft, R. L., & Cooper, W. H. (1983). Measures of
Perrow's Work Unit Technology: An Empirical Assessment and a New Scale. Academy of
Management Journal, 26(1), 45-63.
Items adapted from Withey, Daft and Cooper (1983)
All items measured on a seven point scale, anchored by either "Agree Strongly /
Disagree Strongly" or "Very Minor Extent / Very Great Extent" depending on
the wording of the item.
TASK VARIETY
People working here do about the same job in the same
way most of the time.
Basically, people working here perform repetitive activities
in doing their jobs.
Basically, my tasks are the same from day to day.
To what extent would you say your work is routine?
To what extent are your duties repetitious?
TASK ANALYZABILITY
In my job, one needs to know a lot of procedures and
standard practices to do the work.
To what extent is there an understandable sequence of steps
that can be followed in doing your work?
To what extent do you actually rely on established procedures
and practices in doing your work?
To what extent is there a clearly defined body of knowledge
or subject matter which can guide you in doing your work?
| Lexicon of Moves at Each Site, Categorized into Common Lexicon | |||
| Generic Categories | Reference Desk | PC Lab | Travel Agent |
| Social maintenance | Greet | Greet | Greet |
| Invite Comeback | |||
| Interaction control | OK | End transaction | |
| Not OK | Pause script | ||
| Walk/interrupt/etc | Wait/interrupt | ||
| Monitor Screens & Queue | |||
| Define problem | Question | Question | Get request |
| Ask requestor for info | |||
| Search | Computer based lookup | Look something up | Look in book |
| Look in reference book | Get help | Look in log | |
| Phone for information | |||
| Ask colleague for info | |||
| Ask APOLLO | |||
| Look up existing record | |||
| Verify traveller | |||
| Get personal profile | |||
| Get possible flights | |||
| Ask for lowest fare | |||
| Verify/check delivery | |||
| Get seat Assignments | |||
| Phone contact | |||
| Look in existing stacks | |||
| Request Frequent flyer number | |||
| Try solution | Suggest a source | Suggest Action | Pick best flight |
| Demonstrate On-Line | Try suggestion | Request reservation | |
| Walk over & show | Typing/Mousing | Request APOLLO to book | |
| NU on own PC | Phone hotel to book | ||
| Check results | |||
| Provide Information | Answer | Answer | Answer question |
| Explain | Explain | Give advice | |
| Give directions | Confirm Booking | ||
| Tell Colleague | |||
| Record information | Update booking | ||
| Write in logbook | |||
| Correct booking | |||
| Open new record | |||
| Book flight | |||
| Book car w/corporate vendor | |||
| Book Hotel | |||
| Script moves info in | |||
| Enter air seating preference | |||
| Store pricing/accounting | |||
| Add notes | |||
| Change seat assignments | |||
| Leave voicemail | |||
| Update personal profile | |||
| Convey materials | Get material | Get lost disks | Queue record to pre-ticketing |
| Give material | Checkout keyboard | Queue to QC | |
| Replenish Supplies | Queue to ticketing | ||
| Phone to Rush | |||
| Refer | Off-campus library | Refer elsewhere | Refer request elsewhere |
| On campus library | |||
| Escalate | Escalate | Escalate to Full Time staff | |
| Give up | Admit defeat | ||
| Authorize | Monitor CD-ROM | Monitor users on PCs | |
| Deny service | Call out names | ||
| Anyone Done? | |||
| Deny Service | Decline/refuse | Ask to leave | Deny Service |
| Decline to help | |||
1At the travel agent, however, the client side of the interaction could not be observed and was not coded. Hence, this data was dropped from the subsequent analysis at the other sites, as well. The implications of this decision are discussed below.
2 To capture this intuition, we experimented with a chi-square goodness of fit test. The question here is, for any given observed distribution, what uniform distribution best fits? The number of categories in the best fitting distribution is a measure of the number of moves commonly in use. To identify the best fitting uniform distribution, we examined every uniform distribution up to the maximum number of moves observed for a variety of hypothetical cases and for the data in our three sites. While the method produced intuitively reasonable results, we found that uniform distributions of any width fit the observed data very poorly. The approach works, statistically, but it yields results that are not particularly meaningful. For this reason, we will report only the basic descriptive statistics for the distribution of observed moves.
3For comparisons between sites, the distances computed based on the common lexicon are best. As mentioned in the methodology section, analysis of variance techniques are not appropriate for these data because the observations are not independent. Considering that these averages are based on serveral hundred data points (each strings with every other string), if the data did not violate this important assumption, then all of the differences reported here would be statistically significant.