Figure 2. State diagram as a class of possible event sequences
George M. Wyner
Center for Coordination Science
Sloan School of
Management
Massachusetts Institute of Technology
Cambridge, MA
02139
phone: 1-617-253-3865
gwyner@mit.edu
Jintae Lee
Department of Decision Science
University of Hawaii, Honolulu,
HI 96822
phone: 1-808-956-4589
jl@hawaii.edu
Malone et al [11] have argued that this limitation of the current approach to information systems design can be addressed by employing a specialization hierarchy of processes. In particular, such a hierarchy offers two major advantages: first, it facilitates the search for existing process models relevant to a given design problem, and thus the systematic consideration of a range of design alternatives. Second, variants of existing processes can be systematically generated by specializing existing process models.
Implementing this proposal, however, will require a clear definition of what it means for one process to be a specialization of another, and some guidelines as to how to go about specializing a process in practice. It is with these issues that this paper is concerned.
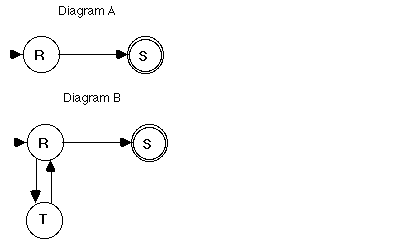
The obvious approach to this problem is to treat the process as a class with a set of attributes and then to specialize processes in the same way that objects are specialized, that is, by subtyping attributes and adding new attributes. It is not obvious, however, how this approach applies to process descriptions, which are typically complex aggregates of nodes and arcs. Consider, for example, the two state diagrams in Figure 1. Diagram A contains two states R and S. Diagram B is identical except that a third state T has been added. Following the usual approach to specialization, we might argue that the diagram with the additional feature, diagram B, is a specialization of diagram A. However, one might also maintain that diagram A is the specialization, since diagram B includes all the behaviors of diagram A, but not vice versa, and thus diagram A is a special case of diagram B. Any approach to specializing process representations must yield an operationalization which can resolve such puzzles.
In this paper, we propose an approach to process specialization which starts from the notion that any process model defines a process class whose instances are specific behaviors of a system. We then define specialization as the act of restricting the extension of a process class. That is, one process is a specialization of another if its instances form a subset of the instances of the original process. We further propose that specialization can be operationalized as a set of "specializing transformations" which can be applied to any process description to produce new process descriptions which are specializations. We identify such a set of transformations for two process descriptions, state diagrams and dataflow diagrams. We also provide simple examples which illustrate two potential advantages of this approach: first, descriptions can be arranged in a specialization hierarchy which facilitates the search for existing process models relevant to a design problem. Second, variants of existing designs can be systematically generated by means of specialization and inheritance.
Before proceeding with our discussion it is useful to define our terms: a system has characteristics which may evolve over time. These changes in the system constitute its behavior. We define a process as a set of behaviors associated with a system. More formally:
We assume that the set of attributes employed is fixed and finite and that each attribute can take on some set of possible values. We refer to this set of possible values as the range of that attribute.
We define an attribute space as the Cartesian product of the attribute ranges of all the attributes in a frame of reference. It follows that whenever the system is observed under that frame of reference its state will correspond to some point in the corresponding attribute space. Furthermore, each point in the attribute space corresponds to what may be a possible state of the system, although some of these points may refer to states which are in fact not realizable.
A process is among other things a set of possible behaviors. Note that any description of a process is made with respect to some frame of reference for the system: the frame of reference corresponding to the attribute space used to describe the set of possible behaviors which constitute that process. As we shall see it is possible to develop equivalent descriptions of a process in a number of different frames of reference.
The set of behaviors which constitute a process is sometimes referred to as the extension of the process and the individual behaviors in the extension are sometimes referred to as instances of that process.
More formally, an attribute space A' is a refinement of attribute space A if there is a surjective mapping M from A' onto A (i.e. the range of M includes every point in A; note that M maps the refinement into the original space rather than vice versa), with the property that whenever a point a' in A' describes the state of the system, then M(a') also applies. The intuition here is that if you refine your description of the system there are more possible state points so that for each point in the original attribute space there is at least one point in the refined attribute space which is a description of the same state.
An attribute space A' is said to be a strict refinement if M is as above and is not also injective. That is, the inverse of M is not a function, or in other words, A is not also a refinement of A'. (This eliminates the trivial sense of refinement in which A and A' are essentially isomorphic.)
Given A', a refinement of A, then a behavior b' in A' is said to be a refinement of a behavior b in A if for every x' in b', M(x') is in b, and for every pair of points x1', x2' in b', then if x1' precedes x2' in the path, then M(x1') precedes or is identical to M(x2'). This last condition has to do with the fact that a path is a directed curve in attribute space and we need to make sure that the points are traced out in the same order in both curves. The idea here is that the refined version of the behavior maps point by point onto the original behavior. Note that given the finer grained view of a process which results from refinement, we must allow for the possibility that M(x1') and M(x2') are identical, and hence that several points in one curve may correspond to a single point in the other. Note, too, that it follows from this definition that every behavior in A will have at least one (and possibly more) refinements in A'.
Similarly, a process p' in A' is said to be a refinement of a process p in A, if for every behavior in p, all A'-refinements of that behavior are included in p', and conversely, all behaviors in p' are A'-refinements of some behavior in p. Then it follows that every process in p will have exactly one refinement in A' and that this refinement is equivalent to the original process description in that both process descriptions lead to the same classification of behaviors.
A specializing transformation is an operation which, when applied to a process described using a given representation and a given frame of reference, results in a new process description under that representation and frame of reference corresponding to a specialization of the original process. Specializing transformations change the extension of a process while preserving the frame of reference.
In contrast, a refining transformation is an operation which changes the frame of reference of a process while preserving its extension, producing a process description of the same process under a different frame of reference.
For each type of transformation there is a related inverse type: a generalizing transformation acts on a process description to produce a generalization of the original process and is thus the inverse of a specializing transformation. Similarly, an abstracting transformation is the inverse of the refining transformation, producing a new description of the same process under a frame of reference for which the original frame is a refinement.
Given that the refining/abstracting transformations preserve the extension of a process, it follows from our definition of process specialization that a specializing transformation composed with refining/abstracting transformations in any sequence produces a specialization. The analogous statement holds for generalizing transformations.
A set of refining/abstracting transformations is said to be complete if for any process p described under a frame of reference, the description of that process under any other frame of reference can be obtained by applying to p a finite number of transformations drawn from the set.
A set of specializing transformations is said to be locally complete if for any frame of reference and any process p described using that frame of reference, then any specialization of p described under that frame of reference can be obtained by applying to p a finite number of transformations drawn from the set. This corresponds to the first part of the definition of process specialization given above.
There is also a notion of completeness corresponding to the second part of the definition. A set of specializing transformations and refining/abstracting transformations is said to be globally complete if for any process p, any specialization of p for which a common frame of reference exists can be obtained by applying to p a finite number of transformations drawn from the set.
Proposition: Let A be a complete set of refining/abstracting transformations and S be a locally complete set of specializing transformations. Then A [[union]] S is globally complete.
Proof: Consider a process p0 and a specialization p1 for which a common frame of reference exists. Since A is complete, one can apply a finite sequence of transformations from A to p0 to produce its refinement in the common frame of reference. By local completeness one can then apply specializing transformations to produce the refinement of p1 (since it is a specialization of the refinement of p0 by assumption). Finally, by the completeness of A one can transform the refinement of p1 into p1. Thus there is a finite set of transformations from A [[union]] S which produces p1 from p0. QED.
![]()
Figure
2. State diagram as a class of possible event sequences
Using the approach developed in section two, we can then define a state diagram D' to be a specialization of state diagram D if and only if either:
We will first identify a set of refining/abstracting transformations which is complete under this restriction. Then we will identify a set of specializing transformations which is locally complete. The (restricted) global completeness then follows from the proposition given at the end of section two.
Refinement by exhaustive decomposition. Replace a state by a mutually exclusive collectively exhaustive set of substates. Add events corresponding to all possible transitions between substates. For each event associated with the original state, add a corresponding event for each of the substates.
Abstraction by total aggregation. If a set of states is completely interconnected by events and an identical set of "external" events is associated with each state in the set (in other words, if this set of states has the properties of an exhaustive decomposition as described above), replace that set of states by a single state which represents their aggregation. Associate with this state the same set of events which was associated with each of the substates.
The proof that these transformations are refining and abstracting respectively, together with a proof of the proposition itself may be found in (Wyner & Lee, 1995).
Delete an individual event. This removes a possible transition between events and thus the new diagram is specialized to exclude all behaviors which involve such a transition.
Delete a state and its associated events. The new diagram is specialized to exclude all behaviors which involve the deleted state.
Delete an initial state marker. This transformation is subject to the condition that at least one initial state marker remains. The new diagram is specialized to exclude all behaviors which begin with the affected state.
Delete a final state marker. This transformation is subject to the condition that at least one final state marker remains. The new diagram is specialized to exclude all behaviors which end with the affected state.
Proof: For any frame of reference and any processes p0 and p1 described under that frame of reference, if p1 is a specialization of p0 then every sequence permitted by p0 must be permitted by p1 as well. Then all initial states of p1 must also be initial states of p0, and similarly for final states. Furthermore, any state or event in p1 must be a state or event in p0 as well, otherwise p1 will permit a sequence involving a state or transition which cannot appear in a sequence of p0. Thus p0 includes all elements of p1, and one can obtain p1 by deleting some set of events, states, initial state markers, and final state markers. Since p0 is itself finite, there can be only a finite number of such deletions. Thus p1 can be obtained from p0 by applying a finite number of transformations from the given set. QED.
It follows directly from the propositions proven so far that the union of the sets of transformations given above is globally complete (subject to the restriction noted above).
Finally, while the preceding set of transformations is thus complete it may sometimes be convenient to employ other specializing transformations. In particular we will make use of:
Specialize a state. Replace a state in the original state diagram by one of its substates. This transformation can be expressed in terms of the above set by first exhaustively decomposing a state into substates and then deleting all but one of them.
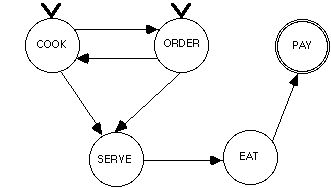
Imagine that you are a systems analyst charged with developing an information system to support the operational side of a large restaurant or chain of restaurants. You might include as part of your analysis a state diagram representing the flow of events involved in a "meal transaction" in a restaurant. That is, the flow of events involved in the delivery of meals to customers and the collection of payment.
We will assume that based on interviews and observations you have determined that any meal transaction will be composed of the following set of five activities: ordering a meal, cooking, serving, eating, and paying. Furthermore your interviews suggest that in the restaurants in question these steps always occur in a single sequence, leading to the simple state machine depicted in Figure 3.[3]
Having observed that none of the four state diagrams developed so far is a specialization of any other, you apply the generalizing transformations to generate a generic restaurant process for which each of the above state diagrams is a specialization: as the diagrams differ only in the events they include, generalizing is simply a matter of adding each of the events from the other diagrams to the original diagram. The resulting diagram is shown in Figure 5.
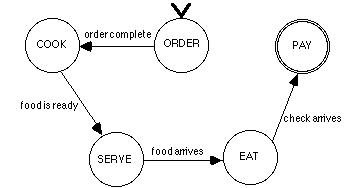
Figure
3. State diagram for full service restaurant
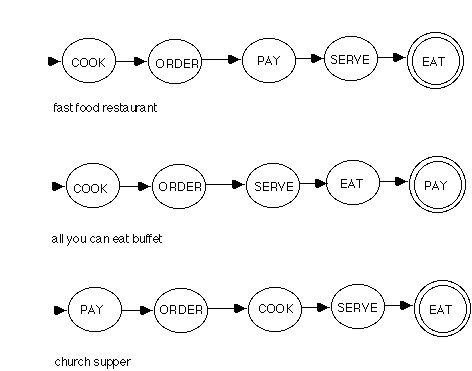
Figure
4. Additional restaurant state diagrams
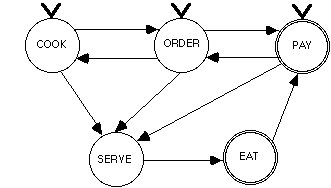
Figure
5. Generalized restaurant transaction
You have thus generated the specialization hierarchy depicted in Figure 6. Such hierarchies can contribute to software (and design) reuse by providing a taxonomy of previous designs which can be searched easily [9].
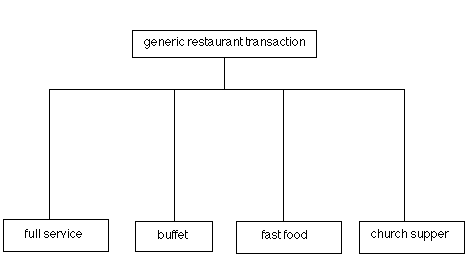
Figure
6. Initial specialization hierarchy for restaurant information system
For example, imagine that you are now called upon to develop a specification to support a restaurant with both table service and a buffet. You can obtain a state diagram for such a hybrid by applying a series of specializing transformations to the generic diagram (see Figure 7).
To the extent that one is choosing among a set of preexisting functions resident in the most generic diagram, a story about the great artist Michaelangelo would seem to be relevant: Michaelangelo was asked how it was that he was able to produce the extraordinary sculpture of David for which he is famous. He replied that he began with a block of marble and simply removed all the pieces that were not David, until only David remained. So with the most generic state diagram in a hierarchy, many diagrams can be generated simply by removing states and events which don't apply.[4]
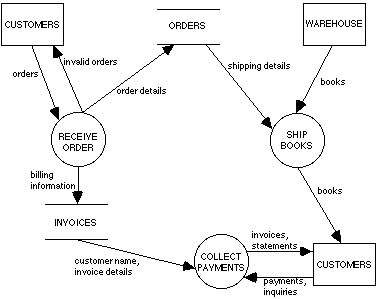
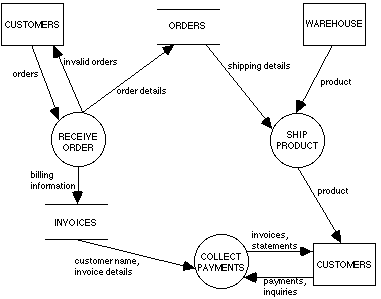
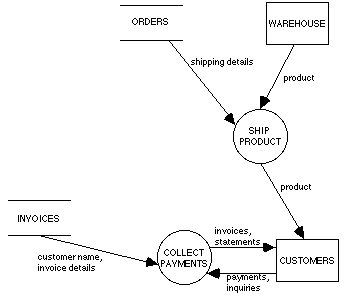
Dataflow diagrams are intended to show the functionality of a system: the various processes, and the flows of information and material which link them to each other, to inventories (data stores), and to various agents external to the system. A dataflow diagram (DFD) consists of a collection of processes, stores, and terminators linked by flows. A simple example taken from Yourdon [19, p.141] is given in Figure 8. This discussion follows the approach taken by Yourdon [19, chapter 9], to which the interested reader is directed for a more detailed exposition.
Processes, shown as circles in the DFD, are the component actions or subprocesses which together constitute the overall process or system being represented in the diagram. Each process is viewed as transforming a set of inputs, modeled by incoming flows, into outputs or outgoing flows. For example, Receive Order in Figure 8 takes as input a flow of orders and produces as outputs order details, billing information, and notification of invalid orders.
Stores, represented by pairs of parallel lines in the DFD, are repositories of the data or material carried in the flows. An incoming flow represents an update to a store, either in the form of additional data (or material), a modification to existing data, or the deletion of data. An outgoing flow represents access to the data or material in a store. In the case of physical material, an outgoing flow represents an actual transfer of material from the store. However, in the case of information, an outgoing flow is taken as representing a non-destructive read of the data in the store. For example, the Invoices store in Figure 8 is updated by a flow of billing information from the Receive Order process and is a source of customer and invoice information for the Collect Payments process.
Terminators, shown as rectangles in the DFD, represent the actors, external to the system being modeled, which interact with the various system processes. Terminators may be sources of information and material which flow into the system and may also receive information and material which flow out of the system. For example, Customers in Figure 8 are a source of orders, payments, and payment inquiries. Customers also receive invoices, statements, and notification of invalid orders.
Flows, shown as arrows in the DFD, represent the movement of information or material between processes, terminators, and stores. A flow can diverge into several subflows, which can signify either that duplicate data/material is being carried in each subflow, or that the data/material has been split into separate components each of which is carried in a subflow. Similarly, several flows can converge into a single superflow which carries an aggregate of the data/material contained in the individual flows. A typical flow is "orders" in Figure 8 which carries orders from Customers to the Receive Order process.
A dataflow diagram does more however than simply list what processes and flows may occur in an instance. It also says something about the relationship between those flows and processes. For example, for each instance of a process which occurs in a DFD instance, one would expect some and possibly all of the flows into and out of that process to also occur.
However, in attempting to state these constraints precisely one encounters certain questions about how a DFD is to be interpreted:
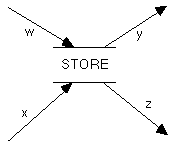
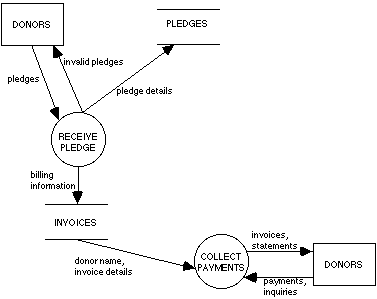
Does a single flow into or out of a store imply all the other flows? For example, in Figure 9 must each instance of flow w be accompanied by flows x, y, and z? It seems clear that this is not always the case. For example, one might have a store of customer information that is updated by one process and queried by another, with the two processes and their flows occurring asynchronously. We shall thus assume that in general all flows into or out of a store may occur independently of each other.[6] This is clearly also true for flows into and out of terminators, since these objects are actors whose behavior is at least to some extent independent of the system in which they act.
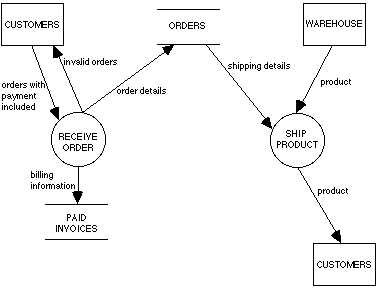
Is a process instance always accompanied by an instance of each of its flows? One can find examples of processes where this is true and processes where it is not. For example, in Figure 8 above, any instance of Ship Books must involve all three flows: an incoming shipping memo and books, which are transformed into an outgoing shipment to the customer. However, in the same diagram the flow of an order into Receive Order may result in a flow of order details into the Orders store or the flow of an invalid order back to the customer, but not both. It seems reasonable to expect each process instance to be accompanied by at least one inflow and one outflow, but one cannot in general say more without reference to the semantics of the domain being modeled. This issue appears to represent a fundamental ambiguity in the dataflow representation: it would seem that there is no domain independent interpretation of a DFD which permits a consistent definition of its class membership.
Since we have no domain independent interpretation of a DFD as defining a class, specialization cannot be extended to DFDs in a domain independent fashion. That is, in general one cannot determine whether one DFD is a valid specialization of another without explicating which flows are mandatory and which are optional and under what circumstances, information which is not captured in the DFD itself.
These ambiguities in the dataflow diagramming technique are well-known and resolutions have been proposed [7]. Interestingly, however, we will show that it is possible to identify a set of transformations which, when applied to a DFD, result in a specialization under any possible interpretation of the flows, and this set is rich enough to be useful.
The following transformations are permitted, because it can be shown that they result in specializations under any possible interpretation of the flows:
Specialization of a component. If one specializes any component (terminator, store, process, or flow) of a dataflow diagram, the resulting diagram will be a specialization of the original diagram under any interpretation.
Deletion of a connected collection of components whose bordering components in the original diagram are all either terminators or stores. To get the sense of this transformation, imagine the original DFD as a physical structure constructed by bonding the various components together, and further imagine that these bonds are unbreakable with the exception of any bond between a flow and either a terminator or store. By breaking these latter bonds, one may in some cases be able to separate the diagram into several pieces. This transformation consists of removing a single one of these pieces while leaving the rest of the diagram and all its bonds intact (e.g. Figure 12 below).
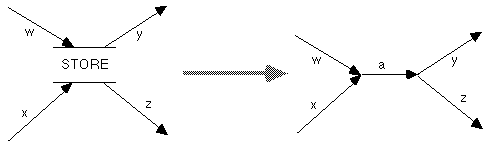
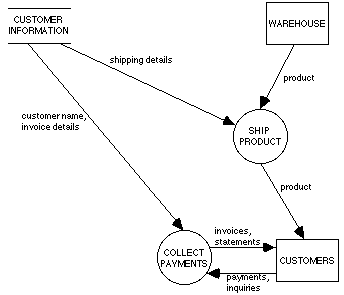
Replacement of all flows into and out of a store by a set of direct flows. This is accomplished by having all incoming flows converge to a single flow which then diverges into the various outgoing flows, with the store omitted, as illustrated in Figure 10. The intuition behind this transformation is that a direct flow between two objects is a kind of degenerate special case of a flow into and out of a store. An interesting example of this kind of specialization is the relationship between manufacturing systems which use work-in-process inventory vs. just-in-time systems.
Decomposition of a component. Any process in a DFD can be decomposed into a lower level DFD, as long as the flows into and out of the decomposition are consistent with the flows in the top level diagram. The resulting DFD is a specialization of the original DFD.[7]
 Figure
10.
Figure
10.
Figure 11 depicts an abstraction of the original dataflow diagram which results when the process Ship Books is generalized to Ship Product, and the flows labeled "books" are generalized to product flows.
For this analysis we will consider primarily the set of dataflow diagrams which are generated by deleting connected portions of the DFD which border on stores and terminators. Specialization of components will also play a limited role in our analysis.
Figure
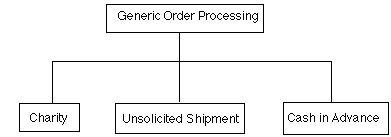
12. Cash in advance order processing
Although this particular process may not sound realistic because of its serious ethical and legal implications, it illustrates one advantage of this type of analysis, namely its ability to generate possibilities that violate commonly held assumptions and norms. In fact, some of these possibilities are in practice, for example when people are sent software (shareware) or a set of personalized mailing labels along with an invoice that the recipient has no obligation to pay but can pay if he or she likes the product. Thus an exploration of process specializations helps one imagine such possibilities by calling into question previously unexamined assumptions.
Figure
14. Unsolicited offers
Figure
15. Orders store and Invoices store are combined
Some modeling languages such as TAXIS [2] define a kind of specialization specific to their process representation. Our goal, on the other hand, is to define a general method for specializing processes under any process representation (even one that does not build the notion of specialization into its semantics). We have pursued this goal in this paper by using two of the common process representations, i.e. state diagram and data flow diagram. In the future, we would like to show how we could accommodate other representations such as TAXIS.
There are other studies of process representation which take approaches similar to the one proposed here. For example, the process formalism in this paper and the definition of refinement in particular are quite similar to the approach taken by Horning and Randell [8]. Horning and Randell also develop a notion of one process "containing" another which is equivalent to our definition of process specialization. This concept, however, plays a secondary role in their analysis. The F-ORM method, a method for specifying applications, discusses "transformation operations" among process representations [4]. In this method, however, these transformations pertain to the decomposition relation, not specialization.
The research most closely related to our own would appear to be Nierstrasz's work on defining a subtyping relationship for active objects [12]. Nierstrasz treats an object as a finite state machine which defines the communications protocol supported by that object: the messages it accepts, the services it provides. He then defines a subtyping relationship on these state machines. This would appear to be quite similar to our own efforts to define a specialization relationship for state machines.
In comparing our work with Nierstrasz, four differences are salient:
To see this, note that object specialization involves subtyping one or more attributes, and subtyping is in a sense a kind of deletion: one makes the type of the attribute more restrictive and thus makes the set of permissible values smaller (which is kind of like deleting from a list of permissible values). If one represents the type of an attribute graphically, this subtyping may be manifested as deleting elements from the graphical representation.
To take a simple example, consider a numeric attribute with type: INTEGER IN 1-10. One might choose to represent this type as a list of allowable numbers. Thus the type would be represented as
1 2 3 4 5 6 7 8 9 10
If one specializes by subtyping to INTEGER IN 4-7 one must delete elements from the representation to obtain:
4 5 6 7
This may appear to be "specialization by deletion" if one focuses on the representation, but clearly it is simply specialization by subtyping.
While this example may appear to be contrived, it is exactly analogous to the state diagram example. Deleting transitions in a state diagram corresponds to subtyping an attribute of the corresponding process. More specifically, one attribute of the process associated with any state diagram is the sequence of states associated with an instance of that process. When one instantiates the process in the form of a behavior, this attribute takes on the value corresponding to the sequence of states associated with that behavior. The type of this attribute must be defined so as to restrict the possible values to those sequences permitted by this process. As it turns out, one can represent this type as a collection of production-like rules which are equivalent to the state machine depicted in the state diagram. One can then show that subtyping this attribute corresponds to deleting events or states from the state diagram [18].
Thus specialization by deletion can be seen to actually be specialization by subtyping.
In fact we will argue that this upward propagation can occur in any specialization hierarchy where one is strict about specialization, and that it is potentially of considerable value to the systems designer.
Consider then what happens to an object in the specialization hierarchy when one changes the attributes of one of its specializations (i.e. one of its children). Clearly adding additional attributes or further subtyping of attributes simply further specializes the child object and has no effect on the parent object. However, if one for some reason needs to "supertype" an attribute of the specialization (for example, one is validating the object model and discovers that the type of an attribute of some object is overly restrictive), a conflict may be introduced into the specialization hierarchy if the new type of this attribute is no longer a subtype of the corresponding attribute in the parent process. Then the child process is no longer a specialization.
If one is to be strict about specialization and it turns out that the new change in type is unavoidable, then one would have to resolve the situation by modifying the type of the parent object in a similar fashion. This would follow logically given that the child is a specialization of the parent and the type of the child is now correct. Then, by definition of specialization, the type of the parent must be at least as inclusive. Now one has modified an attribute in the parent by supertyping and the same issue may arise with its parent with the result that a change in a leaf may necessitate changes in one or more ancestors, possibly all the way to the root of the tree.
Thus we can see that upward propagation is at least a theoretical possibility in any specialization hierarchy. It is important to note that such upward propagation is not normally supported in implementations of object oriented languages and would have to be carried out manually by a series of edits to the class definitions.
It is also important to note that upward propagation occurs only when one takes a strict approach to specialization. That is, the attributes of a specialization must always be identical to or subtypes of the original attributes If this strict approach is not enforced, then in the scenario above one would be free to add an inconsistent specialization without changing the attributes of the parent, and upward propagation would not occur. One would, of course, still be free to choose to modify the parent to reflect insights gained from developing the specialization, but there would be no automatic support for such a process.
The interesting implication here is that a specialization hierarchy may exhibit both upward and downward propagation. Furthermore, each type of propagation appears to offer certain advantages to the system designer.
The benefits of downward propagation (inheritance) are well known, and include the ability to define a new object incrementally by specifying only those aspects of the object which have changed, and thus to inherit all the design knowledge associated with the parent node in the specialization hierarchy.
The benefits of upward propagation are those advanced by Malone et al in their arguments that a specialization hierarchy of processes will allow one to systematically identify a wide range of design alternatives. Upward propagation makes this possible by forcing all design knowledge upward from the leaves to the highest level of abstraction at which it is relevant. Thus each process or object in the hierarchy reflects all the possibilities inherent in its descendants, which can in turn lead to the other benefit mentioned by Malone et al: generativity. For example, upward propagation may bring together a set of features originally present in distinct processes, which can then be recombined in unique ways by specialization.
One especially interesting result is that if specialization rules are enforced strictly, a specialization hierarchy exhibits upward as well as downward propagation, and this upward propagation offers significant benefits to the systems designer.
The work presented in this paper might be extended further in several directions:
First, this approach might be extended to additional process representations.
Second, one might explore whether the notion of specializing and generalizing transformations can be useful in other contexts, for example, the specializing of aggregates.
Third, this approach can be put to the acid test by embodying it in an object-oriented analysis and design tool which will demonstrate the extent to which the potential benefits ascribed to this method are realized in practice.
In conclusion, this paper has suggested that specialization, currently applied to great advantage in the modeling of objects, the nouns of the world, can be fruitfully applied to processes, the verbs of the world, as well. Together, specialization and abstraction give rise to a method of process analysis which shows promise as a means both for identifying new and interesting process possibilities and for gathering the multitude of alternatives so generated into process taxonomies which can then serve as reservoirs of process knowledge [11].
[2] Borgida, A., J. Mylopoulos, and J.W. Schmidt, The TaxisDL Software Description Language, in Database Application Engineering with DAIDA. Volume 1 of Research Reports ESPRIT, M. Jarke, Editor. 1993, Springer-Verlag: Berlin. p. 65-84.
[3] Coad, P. and E. Yourdon, Object-Oriented Analysis. 1990, Englewood Cliffs, New Jersey: Prentice-Hall.
[4] De Antonellis, V., B. Pernici, and P. Samarati. F-ORM METHOD: a F-ORM methodology for reusing specifications. in IFIP TC8/WG8.1 Working Conference on the Object Oriented Approach in Information Systems. 1991. Quebec City, Canada: North-Holland.
[5] de Champeaux, D. Object-Oriented Analysis and Top-Down Software Development. in ECOOP '91, European Conference on Object-Oriented Programming. 1991. Geneva, Switzerland: Springer-Verlag.
[6] de Champeaux, D., L. Constantine, I. Jacobson, S. Mellor, P. Ward, and E. Yourdon. Panel: Structured Analysis and Object Oriented Analysis. in Conference on Object-Oriented Programming: Systems, Languages, and Applications / European Conference on Object-Oriented Programming. 1990. Ottawa, Canada: Association for Computing Machinery.
[7] France, R.B., Semantically Extended Data Flow Diagrams: A Formal Specification Tool. IEEE Transactions on Software Engineering, 1992. 18(4).
[8] Horning, J.J. and B. Randell, Process Structuring. Computing Surveys, 1973. 5(1): p. 5-30.
[9] Krueger, C.W., Software reuse. ACM Computing Surveys, 1992. 24(2): p. 131-183.
[10] Maksay, G. and Y. Pigneur. Reconciling functional decomposition, conceptual modeling, modular design and object orientation for application development. in IFIP TC8/WG8.1 Working Conference on the Object Oriented Approach in Information Systems. 1991. Quebec City, Canada: North-Holland.
[11] Malone, T.W., K. Crowston, J. Lee, and B. Pentland. Tools for Inventing Organizations: Toward a Handbook of Organizational Processes. in Second IEEE Workshop on Enabling Technologies Infrastructure for Collaborative Enterprises. 1993. Morgantown, West Virginia:
[12] Nierstrasz, O. Regular Types for Active Objects. in Conference on Object-Oriented Programming: Systems, Languages, and Applications. 1993. Washington, D.C.: Association for Computing Machinery.
[13] Rogers, R.V. Understated Implications of Object-Oriented Simulation and Modeling. in IEEE International Conference on Systems, Man, and Cybernetics. 1991. Charlottesville, Virginia: IEEE.
[14] Rumbaugh, J., M. Blaha, W. Premerlani, F. Eddy, and W. Lorensen, Object-Oriented Modeling and Design. 1991, Englewood Cliffs, New Jersey: Prentice Hall.
[15] Salancik, G.R. and H. Leblebici, Variety and Form in Organizing Transactions: A Generative Grammar of Organization, in Research in the Sociology of Organizations, N. DiTomaso and S.B. Bacharach, Editor. 1988, JAI Press: Greenwich, Connecticut. p. 1-31.
[16] Takagaki, K. and Y. Wand. An Object-Oriented Information Systems Model Based On Ontology. in IFIP TC8/WG8.1 Working Conference on the Object Oriented Approach in Information Systems. 1991. Quebec City, Canada: North-Holland.
[17] Wegner, P. and S.B. Zdonik. Inheritance as an Incremental Modification Mechanism or What Like Is and Isn't Like. in European Conference on Object-Oriented Programming. 1988. Oslo, Norway: Springer-Verlag.
[18] Wyner, G. and J. Lee, Defining Specialization for Process Models. 1995, Technical Report (in preparation).
[19] Yourdon, E., Modern Structured Analysis. Yourdon Press Computing Series, 1989, Englewood Cliffs, New Jersey: Yourdon Press.